Projects
Multi-sensor perception
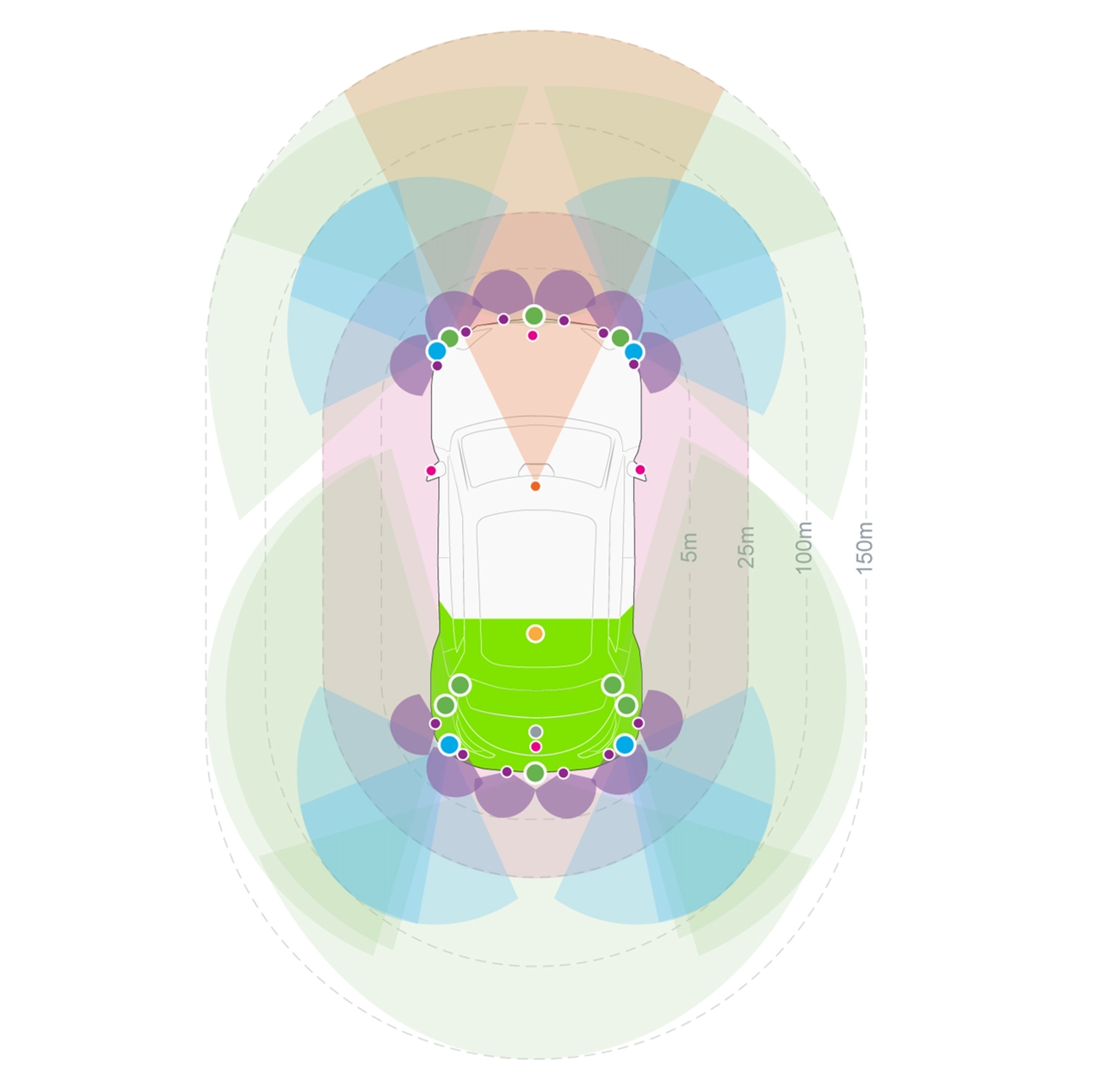
Automated driving relies first on a diverse range of sensors, like Valeo’s fish-eye cameras, LiDARs, radars and ultrasonics. Exploiting at best the outputs of each of these sensors at any instant is fundamental to understand the complex environment of the vehicle and gain robustness. To this end, we explore various machine learning approaches where sensors are considered either in isolation (as radar in Carrada at ICPR’20) or collectively (as in xMUDA at CVPR’20).

3D perception
Each sensor delivers information about the 3D world around the vehicle. Making sense of this information in terms of drivable space and important objects (road users, curb, obstacles, street furnitures) in 3D is required for the driving system to plan and act in the safest and most confortable way. This encompasses several challenging tasks, in particular detection and segmentation of objects in point clouds as in FKAConv at ACCV’20.

Frugal learning
Collecting diverse enough data, and annotating it precisely, is complex, costly and time-consuming. To reduce dramatically these needs, we explore various alternatives to fully-supervised learning, e.g, training that is unsupervised (as rOSD at ECCCV’20), self-supervised (as BoWNet at CVPR’20), semi-supervised, active, zero-shot (as ZS3 at NeurIPS’19) or few-shot. We also investigate training with fully-synthetic data (in combination with unsupervised domain adaptation) and with GAN-augmented data (as Semantic Palette at CVPR’21).

Domain adaptation
Deep learning and reinforcement learning are key technologies for autonomous driving. One of the challenges they face is to adapt to conditions which differ from those met during training. To improve systems’ performance in such situations, we explore so-called “domain adaptation” techniques, as in AdvEnt at CVPR’19 and DADA its extension at ICCV’19. We propose new solutions to more practical DA scenarios in MTAF (ICCV'21) to handle multiple target domains and in BUDA (CVIU'21) to handle new target classes. In xMUDA (CVPR'20), we introduce a new framework to tackle the challenging adaptation problem on both 2D image and 3D point-cloud spaces.

Reliability
When the unexpected happens, when the weather badly degrades, when a sensor gets blocked, the embarked perception system should diagnose the situation and react accordingly, e.g., by calling an alternative system or the human driver. With this in mind, we investigate ways to improve the robustness of neural nets to input variations, including to adversarial attacks, and to predict automatically the performance and the confidence of their predictions as in ConfidNet at NeurIPS’19.
Driving in action
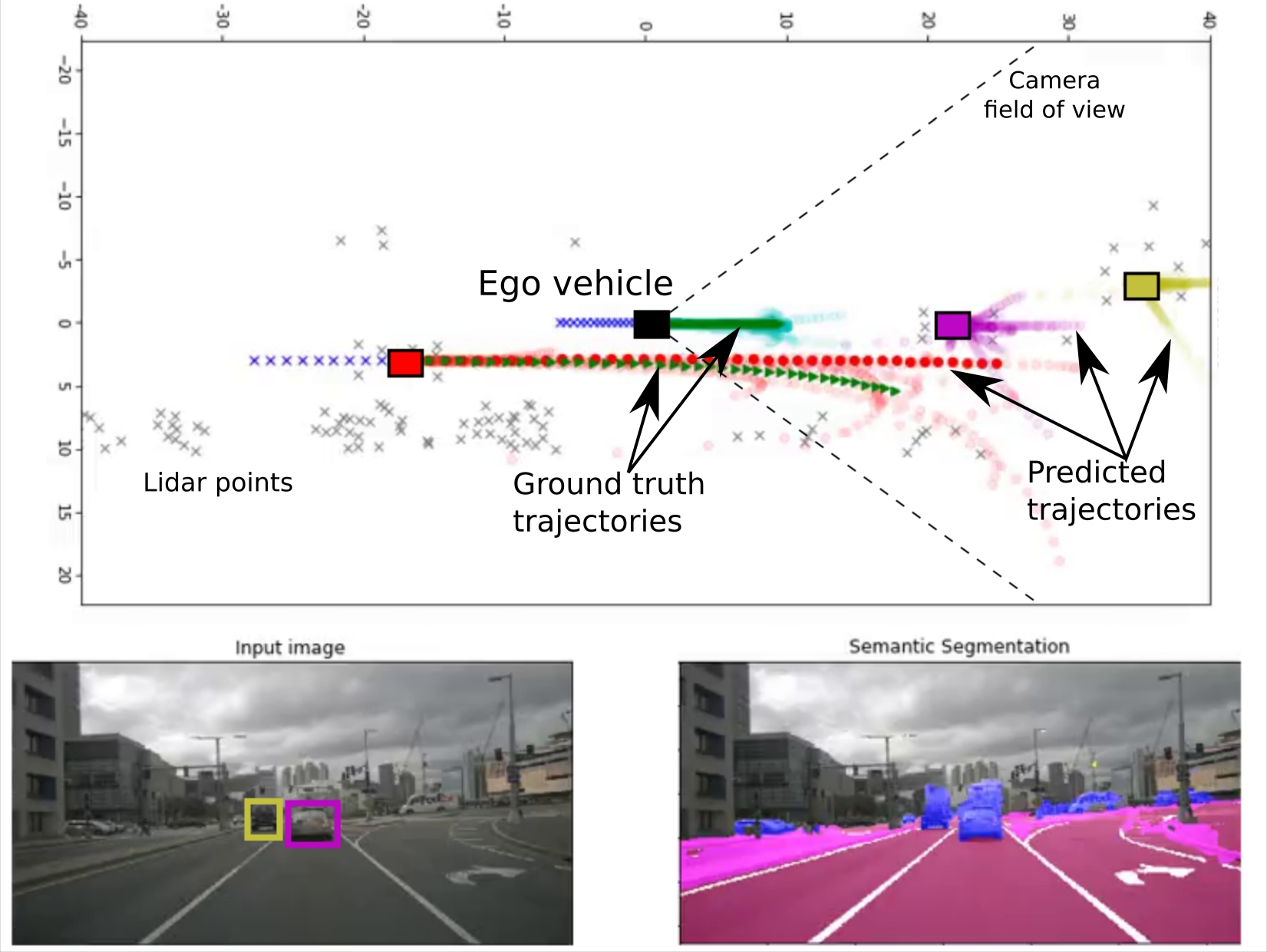
Getting from sensory inputs to car control goes either through a modular stack (perception > localization > forecast > planning > actuation) or, more radically, through a single end-to-end model. We work on both strategies, more specificaly on action forecasting, automatic interpretation of decisions taken by a driving system, and reinforcement / imitation learning for end-to-end systems (as in RL work at CVPR’20).
Core Deep Learning
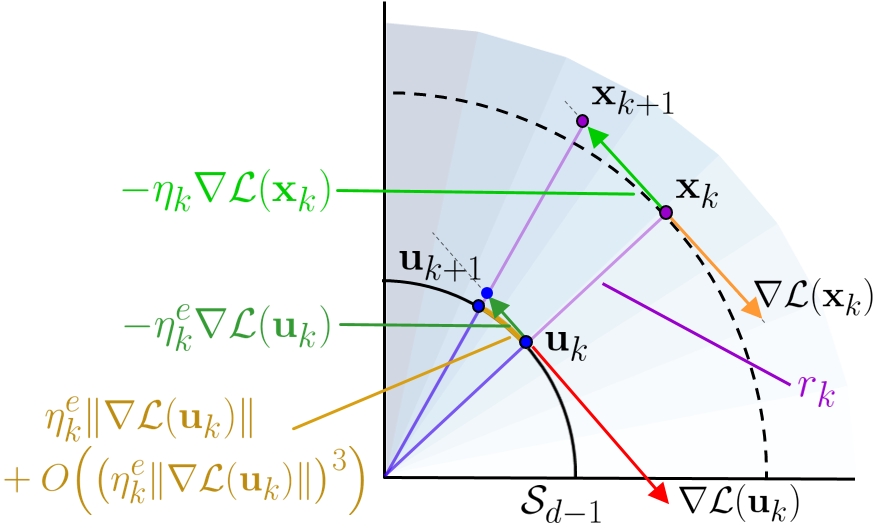
Deep learning being now a key component of AD systems, it is important to get a better understanding of its inner workings, in particular the link between the specifics of the learning optimization and the key properities (performance, regularity, robustness, generalization) of the trained models. Among other things, we investigate the impact of popular batch normalization on standard learning procedures and the ability to learn through unsupervised distillation.
Interpretability and Explainability of Deep Models
The concept of explainability has several facets and the need for explainability is strong in safety-critical applications such as autonomous driving where deep learning models are now widely used. As the underlying mechanisms of these models remain opaque, explainability and trustworthiness have become major concerns. Among other things, we investigate methods providing explanations to a black-box visual-based systems in a post-hoc fashion, as well as approaches that aim at building more interpretable self-driving systems by design.