Learning Representations by Predicting Bags of Visual Words
Spyros Gidaris Andrei Bursuc Nikos Komodakis Patrick Pérez Matthieu Cord
CVPR 2020
Abstract
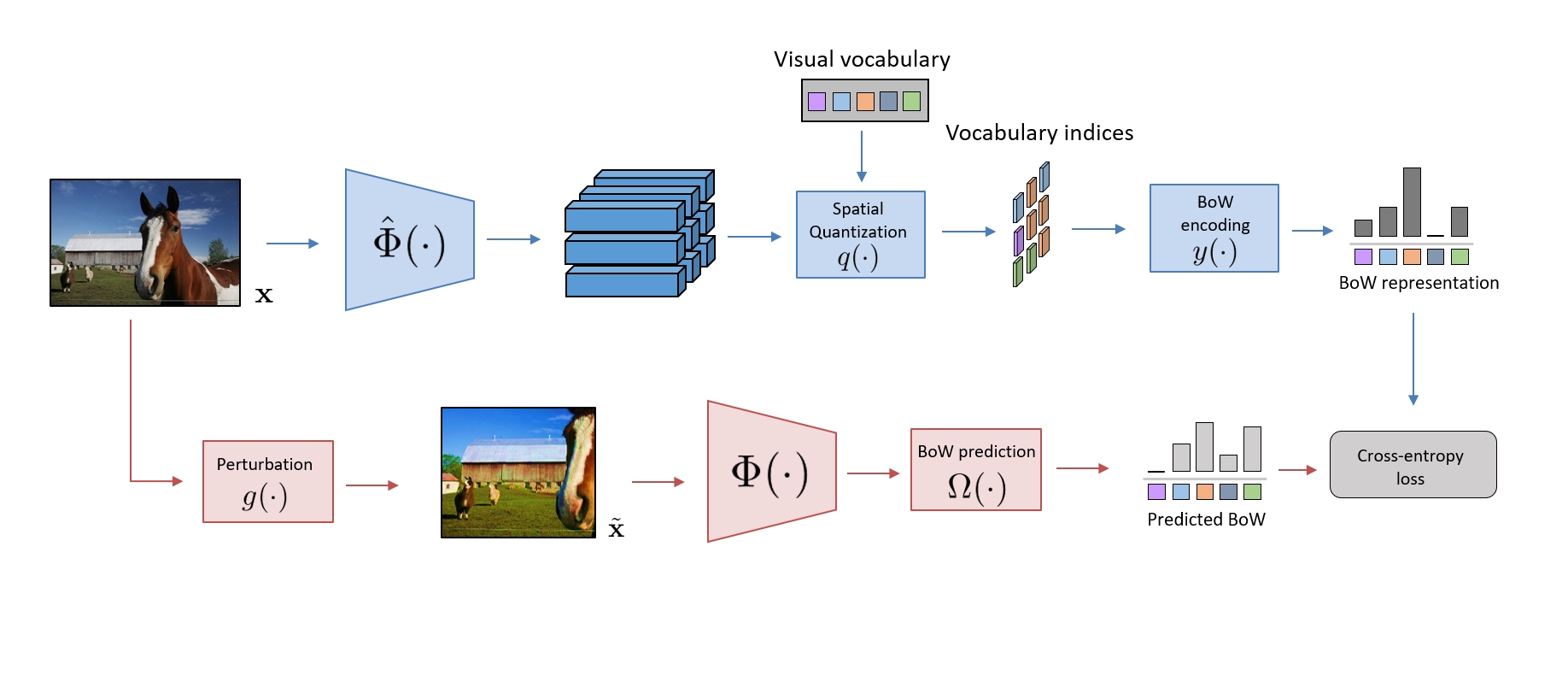
Self-supervised representation learning targets to learn convnet-based image representations from unlabeled data. Inspired by the success of NLP methods in this area, in this work we propose a self-supervised approach based on spatially dense image descriptions that encode discrete visual concepts, here called visual words. To build such discrete representations, we quantize the feature maps of a first pre-trained self-supervised convnet, over a k-means based vocabulary. Then, as a self-supervised task, we train another convnet to predict the histogram of visual words of an image (i.e., its Bag-of-Words representation) given as input a perturbed version of that image. The proposed task forces the convnet to learn perturbation-invariant and context-aware image features, useful for downstream image understanding tasks. We extensively evaluate our method and demonstrate very strong empirical results, e.g., our pre-trained self-supervised representations transfer better on detection task and similarly on classification over classes "unseen" during pre-training, when compared to the supervised case. This also shows that the process of image discretization into visual words can provide the basis for very powerful self-supervised approaches in the image domain, thus allowing further connections to be made to related methods from the NLP domain that have been extremely successful so far.
BibTeX
@inproceedings{gidaris2020learning,
title={Learning Representations by Predicting Bags of Visual Words},
author={Gidaris, Spyros and Bursuc, Andrei and Komodakis, Nikos and P{\'e}rez, Patrick and Cord, Matthieu},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={6928--6938},
year={2020}
}