valeo.ai at ICCV 2023
Gilles Puy, Tuan-Hung Vu, Oriane Siméoni, Matthieu Cord, Cédric Rommel, Andrei Bursuc
- Using a Waffle Iron for Automotive Point Cloud Semantic Segmentation
- PØDA: Prompt-driven Zero-shot Domain Adaptation
- You Never Get a Second Chance To Make a Good First Impression: Seeding Active Learning for 3D Semantic Segmentation
- eP-ALM: Efficient Perceptual Augmentation of Language Models
- Zero-shot spatial layout conditioning for text-to-image diffusion models
- DiffHPE: Robust, Coherent 3D Human Pose Lifting with Diffusion
- Challenges of Using Real-World Sensory Inputs for Motion Forecasting in Autonomous Driving
- POP-3D: Open-Vocabulary 3D Occupancy Prediction from Images
The IEEE / CVF International Conference on Computer Vision (ICCV) is a landmark event for the increasingly large and diverse community of researchers in computer vision and machine learning. This year, ICCV takes place in Paris, home of the valeo.ai team. From interns to senior researchers, the valeo.ai team will participate in mass at ICCV and will be looking forward to welcoming you and talking about the exciting progress and ideas in the field.
At ICCV 2023 we will present 5 papers in the main conference and 3 in the workshops. We are also organizing 2 tutorials with 2 challenges (BRAVO and UNCV) and a tutorial (Many Faces of Reliability). Take a quick view of our papers in the conference and come meet us at the posters, at our booth or in the hallway.
Using a Waffle Iron for Automotive Point Cloud Semantic Segmentation
Authors: Gilles Puy, Alexandre Boulch, Renaud Marlet
[Paper] [Code] [Project page]
Semantic segmentation of point clouds delivered by lidars permits autonomous vehicles to make sense of their 3D surrounding environment. Sparse convolutions have become a de-facto tool to process these large outdoor point clouds. The top performing methods on public benchmarks, such SemanticKITTI or nuScenes, all leverage sparse convolutions. Nevertheless, despite their undeniable success and efficiency, these convolutions remain available in a limited number of deep learning frameworks and hardware platforms. In this work, we propose an alternative backbone built with tools broadly available (such as 2D and 1D convolutions) but that still reaches the level of performance of the top methods on automotive datasets.
We propose a point-based backbone, called WaffleIron, which is essentially built using standard MLPs and dense 2D convolutions, both readily available in all deep learning frameworks thanks to their wide use in the field of computer vision. The architecture of this backbone is illustrated in the figure below. It is inspired by the recent MLP-Mixer. It takes as input a point cloud with a token associated to each point. All these point tokens are then updated by a sequence of layers, each containing a token-mixing step (made of dense 2D convolutions) and a channel-mixing step (made of a MLP shared across points).
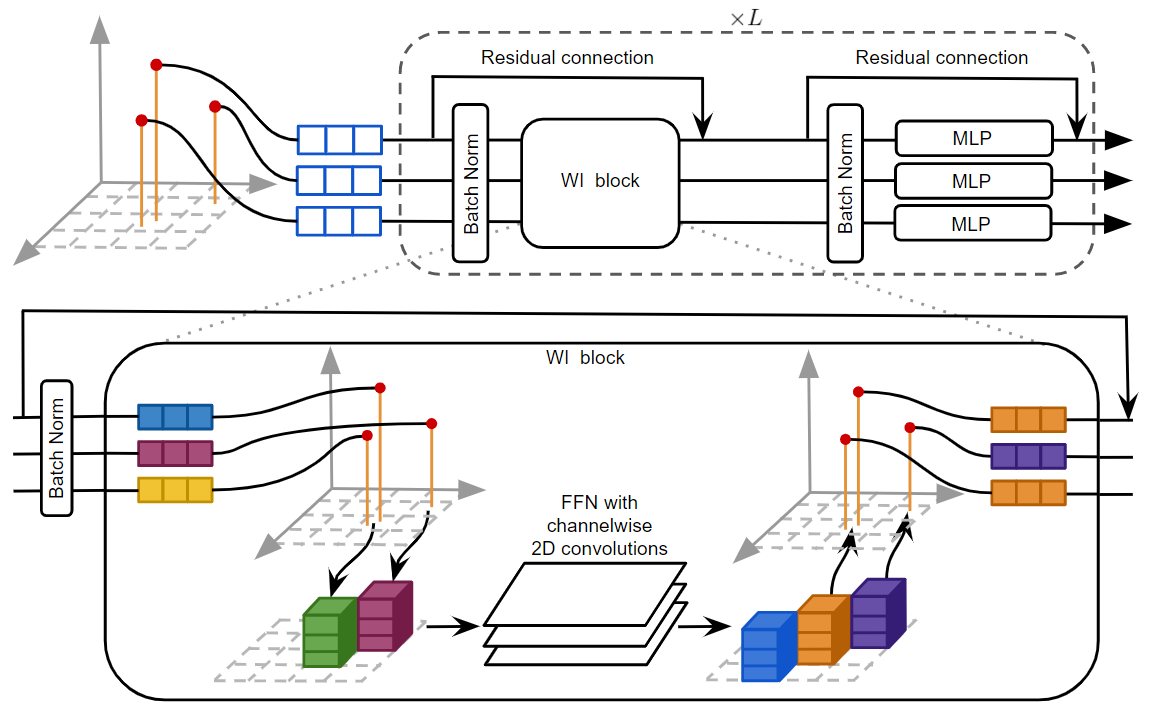
WaffleIron has three main hyperparameters to tune: the depth L, the width F and the resolution of the 2D grid. We show that these parameters are easy to tune: the performance increases with the network width F and depth L, until an eventual saturation; we observe stable results over a wide range of values for the resolution of the 2D grid.
In our paper, we also provide many details on how to train WaffleIron to reach the performance of top-entries on two autonomous driving benchmarks: SemanticKITTI and nuScenes.
PØDA: Prompt-driven Zero-shot Domain Adaptation
Authors: Mohammad Fahes, Tuan-Hung Vu, Andrei Bursuc, Patrick Pérez, Raoul de Charette
[Paper] [Code] [Video] [Project page]
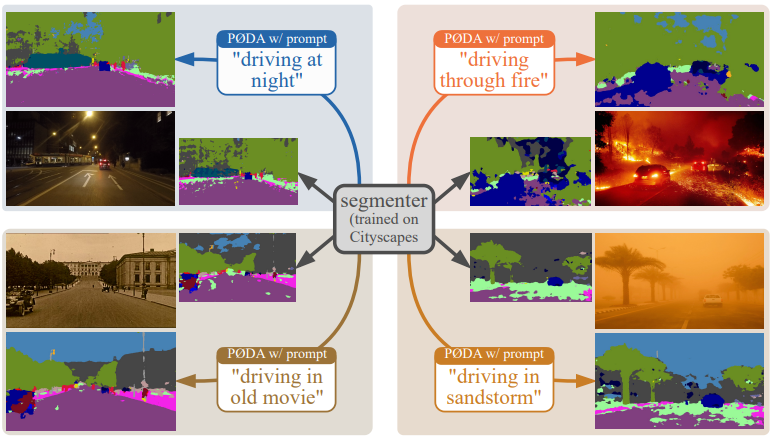
Domain adaptation has been vastly investigated in computer vision but still requires access to target images at train time, which might be intractable in some uncommon conditions. In this paper, we propose the task of ‘Prompt-driven Zero-shot Domain Adaptation’, where we adapt a model trained on a source domain using only a general description in natural language of the target domain, i.e., a prompt. First, we leverage a pre-trained contrastive vision-language model (CLIP) to optimize affine transformations of source features, steering them towards the target text embedding while preserving their content and semantics. To achieve this, we propose Prompt-driven Instance Normalization (PIN). Second, we show that these prompt-driven augmentations can be used to perform zero-shot domain adaptation for semantic segmentation. Experiments demonstrate that our method significantly outperforms CLIP-based style transfer baselines on several datasets for the downstream task at hand, even surpassing one-shot unsupervised domain adaptation. A similar boost is observed on object detection and image classification
You Never Get a Second Chance To Make a Good First Impression: Seeding Active Learning for 3D Semantic Segmentation
Authors: Nermin Samet, Oriane Siméoni, Gilles Puy, Georgy Ponimatkin, Renaud Marlet, Vincent Lepetit
[Paper] [Code]
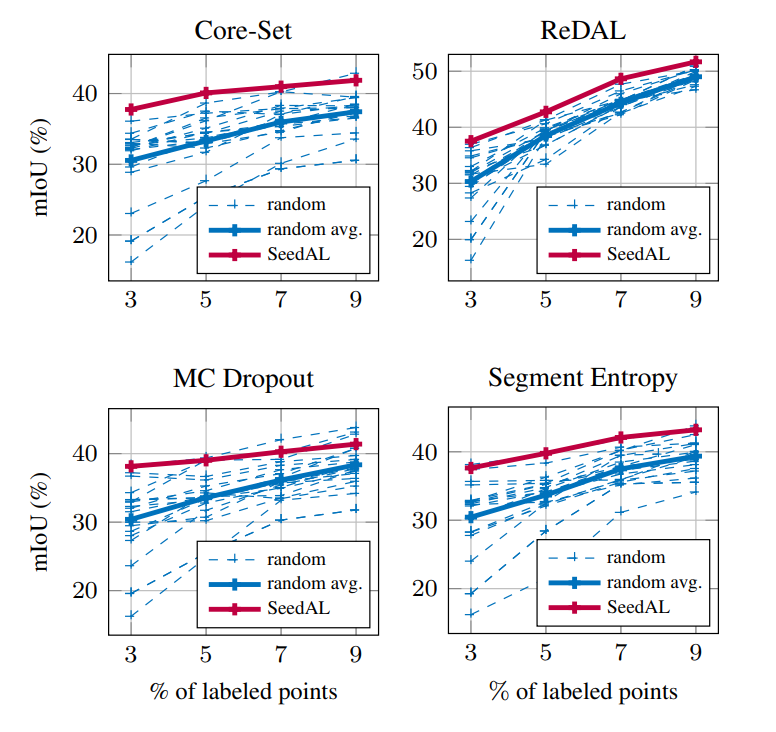
We are interested in the efficient annotation of sparse 3D point clouds (as captured indoors by depth cameras or outdoors by automotive lidars) for semantic segmentation. Active Learning (AL) iteratively selects relevant data fractions to annotate within a given budget, but requires a first fraction of the dataset (a ’seed’) to be already annotated to estimate the benefit of annotating other data fractions. We show that the choice of the seed can significantly affect the performance of many AL methods and propose a method, named SeedAL, for automatically constructing a seed that will ensure good performance for AL. Assuming that images of the point clouds are available, which is common, our method relies on powerful unsupervised image features to measure the diversity of the point clouds. It selects the point clouds for the seed by optimizing the diversity under an annotation budget, which can be done by solving a linear optimization problem. Our experiments demonstrate the effectiveness of our approach compared to random seeding and existing methods on both the S3DIS and SemanticKitti datasets.
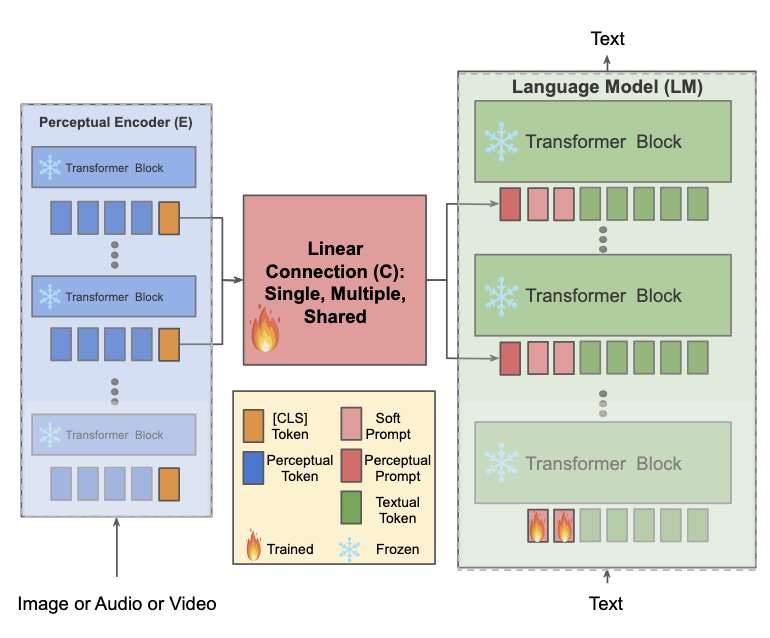
eP-ALM: Efficient Perceptual Augmentation of Language Models
Authors: Mustafa Shukor, Corentin Dancette, Matthieu Cord
[Paper] [Code] [Project page]
eP-ALM aims to augment large language models (LLMs) with perception. While most existing approaches train a large number of parameters and rely on extensive multimodal pre-training, we investigate the minimal computational effort required to adapt unimodal models to multimodal tasks. We show that by freezing more than 99% of total parameters, training only one linear projection layer and prepending only one trainable token, our approach (dubbed eP-ALM) significantly outperforms other baselines on VQA and captioning for image, video and audio modalities.
Zero-shot spatial layout conditioning for text-to-image diffusion models
Authors: Guillaume Couairon, Marlène Careil, Matthieu Cord, Stéphane Lathuilière, Jakob Verbeek
[Paper]
Large-scale text-to-image diffusion models have considerably improved the state of the art in generative image modeling, and provide an intuitive and powerful user interface to drive the image generation process. In this paper, we propose ZestGuide, a “zero-shot” segmentation guidance approach that can be integrated into pre-trained text-image diffusion models, and requires no additional training. It exploits the implicit segmentation maps that can be extracted from cross-attention layers, and uses them to align generation with input masks.

DiffHPE: Robust, Coherent 3D Human Pose Lifting with Diffusion
ICCV Workshop on Analysis and Modeling of Faces and Gestures
Authors: Cédric Rommel, Eduardo Valle, Mickaël Chen, Souhaiel Khalfaoui, Renaud Marlet, Matthieu Cord, Patrick Pérez
[Paper] [Code] [Project page]
Diffusion models are making waves across various domains, including computer vision, natural language processing and time-series analysis. However, its application to purely predictive tasks, such as 3D human pose estimation (3D-HPE), remains largely unexplored. While a few pioneering works have shown promising performance metrics in 3D-HPE, the understanding of the benefits of diffusion models over classical supervision — as well as key design choices — is still in its infancy. In this work, we address those concerns, providing an in-depth analysis of the effects of diffusion models on 3D-HPE.
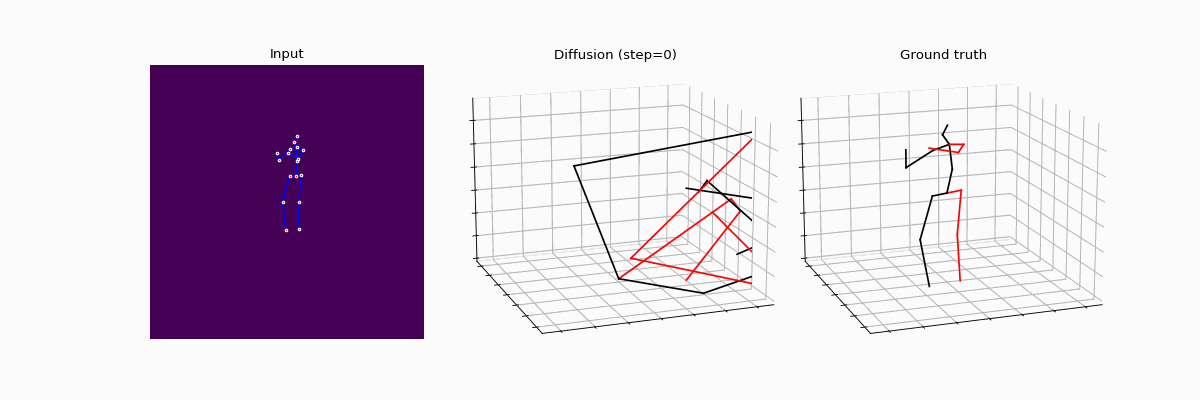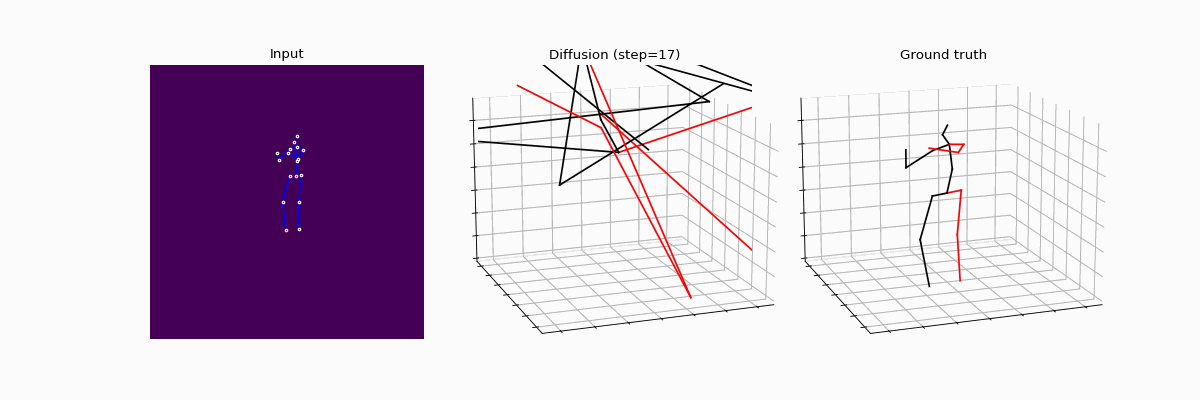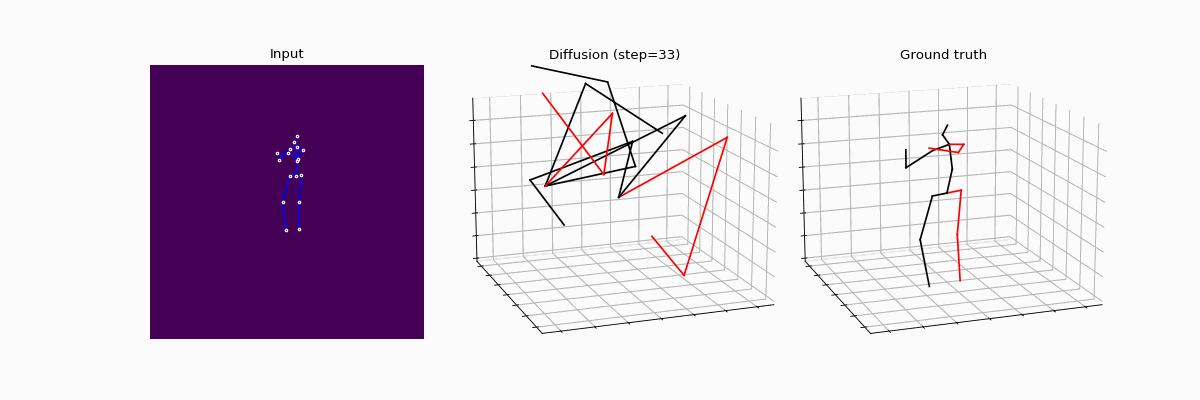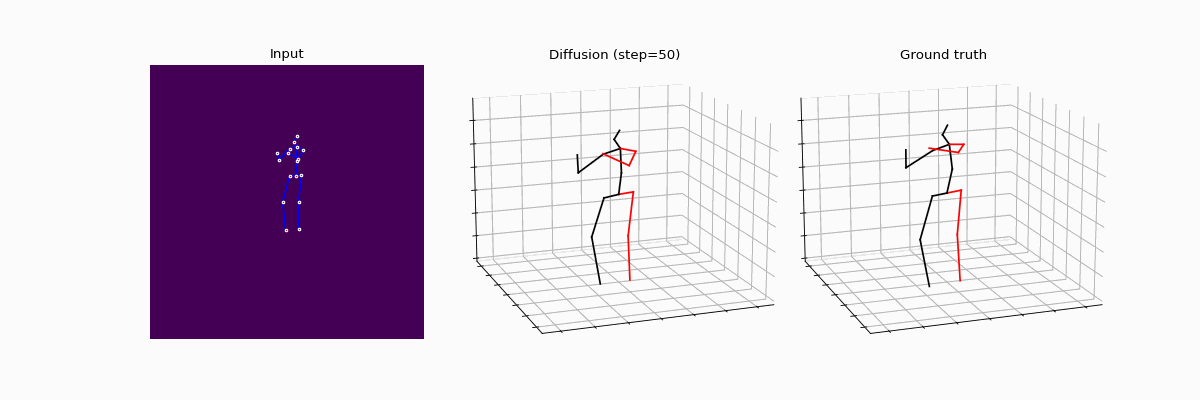
More precisely, we propose DiffHPE, a novel strategy to use diffusion models in 3D-HPE, and show that combining diffusion with pre-trained supervised models allows to outperform both pure diffusion and pure supervised models trained separately. Our analysis demonstrates not only that the diffusion framework can be used to enhance accuracy, as previously understood, but also that it can improve robustness and coherence. Namely, our experiments showcase how poses estimated with diffusion models’ display better bilateral and temporal coherence, and are more robust to occlusions, even when not perfectly trained for the latter.
Challenges of Using Real-World Sensory Inputs for Motion Forecasting in Autonomous Driving
Authors: Yihong Xu, Loïck Chambon, Éloi Zablocki, Mickaël Chen, Matthieu Cord, Patrick Pérez
[Paper] [Project page]
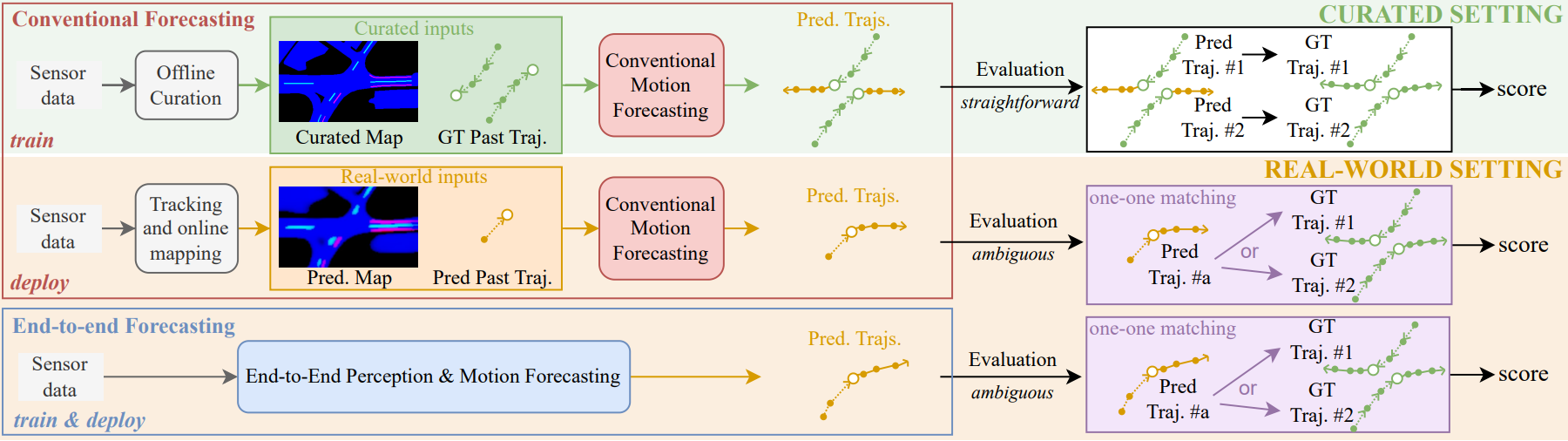
Motion forecasting is crucial in enabling autonomous vehicles to anticipate the future trajectories of surrounding agents. To do so, it requires solving mapping, detection, tracking, and then forecasting problems, in a multi-step pipeline. In this complex system, advances in conventional forecasting methods have been made using curated data, i.e., with the assumption of perfect maps, detection, and tracking. This paradigm, however, ignores any errors from upstream modules. Meanwhile, an emerging end-to-end paradigm, that tightly integrates the perception and forecasting architectures into joint training, promises to solve this issue. So far, however, the evaluation protocols between the two methods were incompatible and their comparison was not possible. In fact, and perhaps surprisingly, conventional forecasting methods are usually not trained nor tested in real-world pipelines (e.g., with upstream detection, tracking, and mapping modules). In this work, we aim to bring forecasting models closer to real-world deployment. First, we propose a unified evaluation pipeline for forecasting methods with real-world perception inputs, allowing us to compare the performance of conventional and end-to-end methods for the first time. Second, our in-depth study uncovers a substantial performance gap when transitioning from curated to perception-based data. In particular, we show that this gap (1) stems not only from differences in precision but also from the nature of imperfect inputs provided by perception modules, and that (2) is not trivially reduced by simply finetuning on perception outputs. Based on extensive experiments, we provide recommendations for critical areas that require improvement and guidance towards more robust motion forecasting in the real world. We will release an evaluation library to benchmark models under standardized and practical conditions.
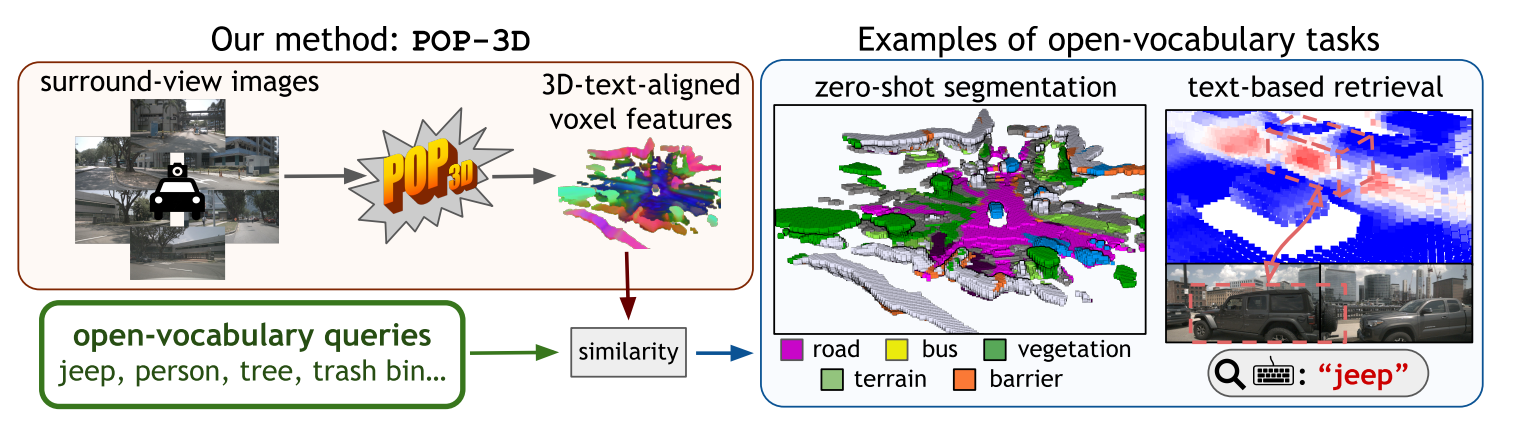
POP-3D: Open-Vocabulary 3D Occupancy Prediction from Images
ICCV 2023 Workshop on Open-Vocabulary 3D Scene Understanding (OpenSUN 3D)
Authors: Antonin Vobecky, Oriane Siméoni, David Hurych, Spyros Gidaris, Andrei Bursuc, Patrick Pérez, Josef Sivic
[Paper]
We propose an approach to predict a 3D semantic voxel occupancy map from input 2D images with features allowing 3D grounding, segmentation and retrieval of free-form language queries. To this end: We design a new architecture that consists of a 2D-3D encoder together with occupancy prediction and 3D-language heads; We develop a tri-modal self-supervised training that leverages three modalities – images, language and LiDAR point clouds– and enables learning the proposed architecture using a strong pre-trained vision-language model without the need for any 3D manual annotations. We quantitatively evaluate the proposed model on the task of zero-shot 3D semantic segmentation using existing datasets and show results on the tasks of 3D grounding and retrieval of free-form language queries.