valeo.ai at CVPR 2023
Alexandre Boulch, Oriane Siméoni, Gilles Puy, Éloi Zablocki, Spyros Gidaris, Andrei Bursuc
The IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR) is a key event for researchers and engineers working on computer vision and machine learning. At the 2023 edition the valeo.ai team will present six papers in the main conference, one workshop keynote and organize a tutorial. The team will be at CVPR to present these works and will be happy to discuss more about these projects and ideas, and share our exciting ongoing research. We outline four of our team papers below.
OCTET: Object-aware Counterfactual Explanations
Authors: Mehdi Zemni, Mickaël Chen, Éloi Zablocki, Hédi Ben-Younes, Patrick Pérez, Matthieu Cord
[Paper] [Code] [Video] [Project page]
Nowadays, deep vision models are being widely deployed in safety-critical applications, e.g., autonomous driving, and explainability of such models is becoming a pressing concern. Among explanation methods, counterfactual explanations aim to find minimal and interpretable changes to the input image that would also change the output of the model to be explained. Such explanations point end-users at the main factors that impact the decision of the model. However, previous methods struggle to explain decision models trained on images with many objects, e.g., urban scenes, which are more difficult to work with but also arguably more critical to explain. In this work, we propose to tackle this issue with an object-centric framework for counterfactual explanation generation. Our method, inspired by recent generative modeling works, encodes the query image into a latent space that is structured in a way to ease object-level manipulations. Doing so, it provides the end-user with control over which search directions (e.g., spatial displacement of objects, style modification, etc.) are to be explored during the counterfactual generation. We conduct a set of experiments on counterfactual explanation benchmarks for driving scenes, and we show that our method can be adapted beyond classification, e.g., to explain semantic segmentation models. To complete our analysis, we design and run a user study that measures the usefulness of counterfactual explanations in understanding a decision model.

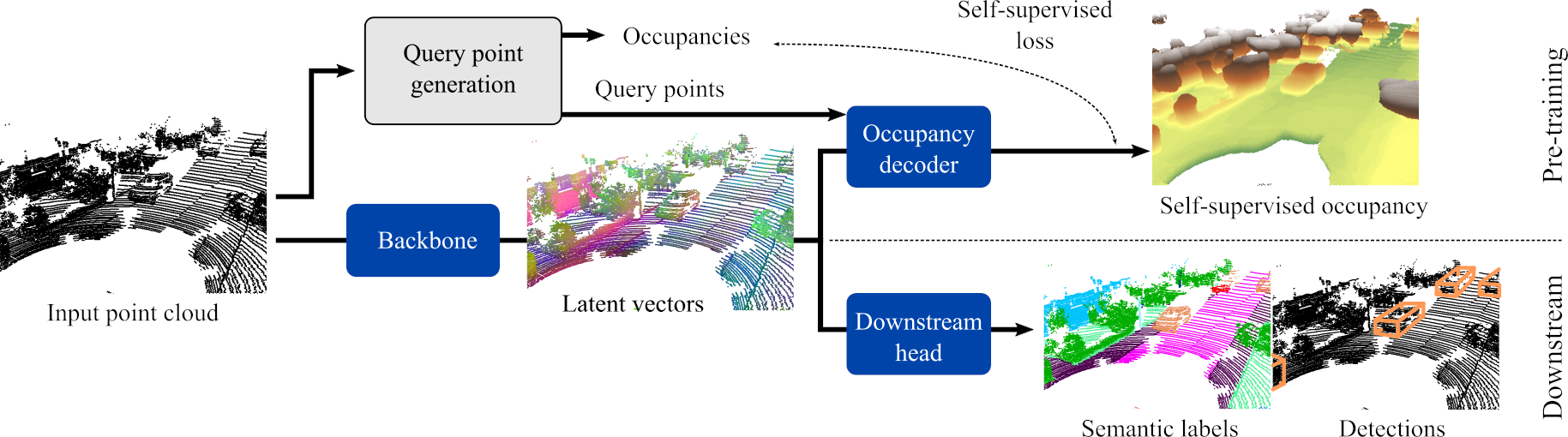
ALSO: Automotive Lidar Self-supervision by Occupancy estimation
Authors: Alexandre Boulch, Corentin Sautier, Björn Michele, Gilles Puy, Renaud Marlet
[Paper] [Code] [Video] [Project page]
We propose a new self-supervised method for pre-training the backbone of deep perception models operating on point clouds. The core idea is to train the model on a pretext task which is the reconstruction of the surface on which the 3D points are sampled, and to use the underlying latent vectors as input to the perception head. The intuition is that if the network is able to reconstruct the scene surface, given only sparse input points, then it probably also captures some fragments of semantic information that can be used to boost an actual perception task. This principle has a very simple formulation, which makes it both easy to implement and widely applicable to a large range of 3D sensors and deep networks performing semantic segmentation or object detection. In fact, it supports a single-stream pipeline, as opposed to most contrastive learning approaches, allowing training on limited resources. We conducted extensive experiments on various autonomous driving datasets, involving very different kinds of lidars, for both semantic segmentation and object detection. The results show the effectiveness of our method to learn useful representations without any annotation, compared to existing approaches.
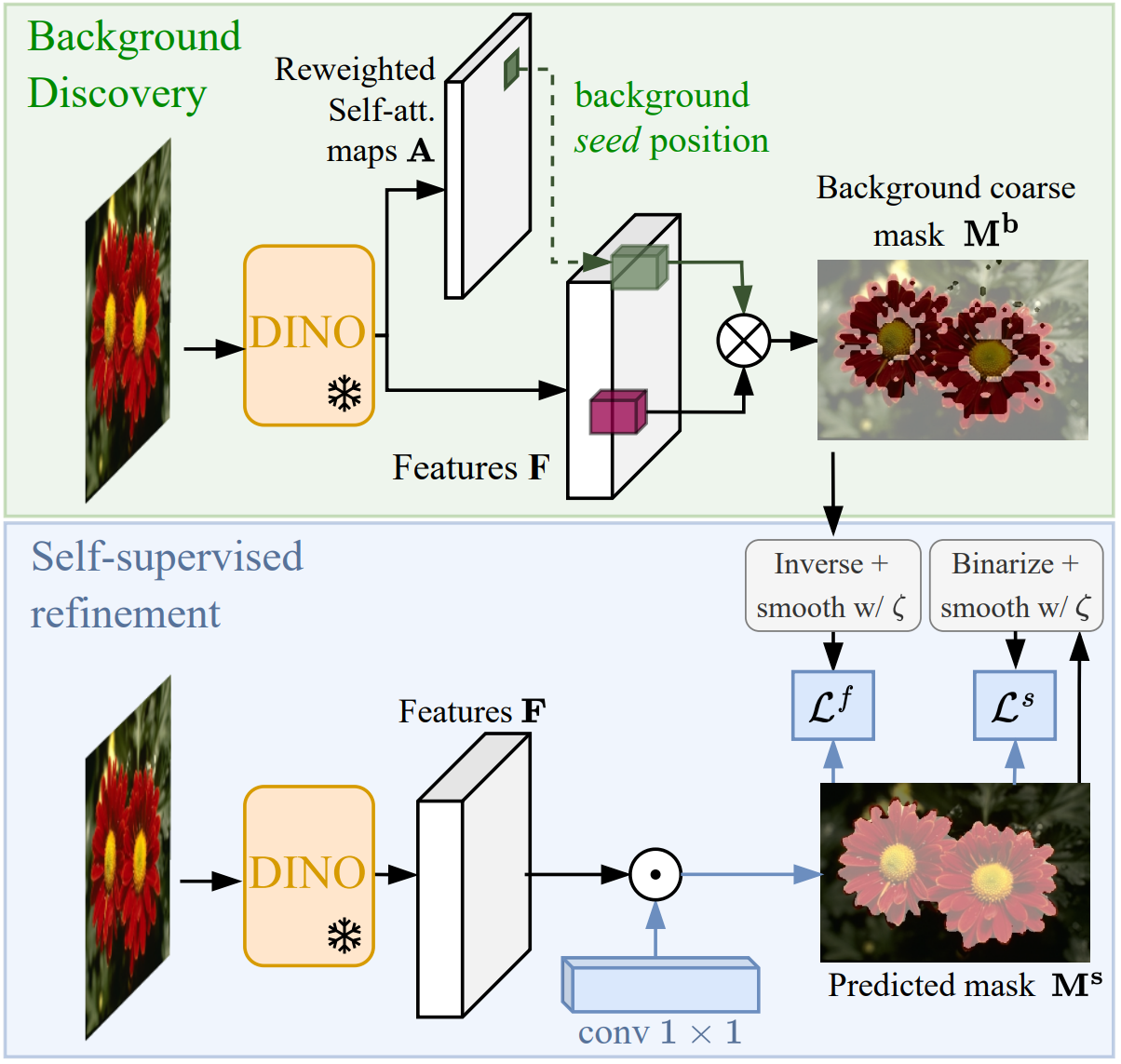
Unsupervised Object Localization: Observing the Background to Discover Objects
Authors: Oriane Siméoni, Chloé Sekkat, Gilles Puy, Antonin Vobecky, Éloi Zablocki, Patrick Pérez
[Paper] [Code] [Video] [Project page]
Recent advances in self-supervised visual representation learning have paved the way for unsupervised methods tackling tasks such as object discovery and instance segmentation. However, discovering objects in an image with no supervision is a very hard task; what are the desired objects, when to separate them into parts, how many are there, and of what classes? The answers to these questions depend on the tasks and datasets of evaluation. In this work, we take a different approach and propose to look for the background instead. This way, the salient objects emerge as a by-product without any strong assumption on what an object should be. We propose FOUND, a simple model made of a single conv1 × 1 initialized with coarse background masks extracted from self-supervised patch-based representations. After fast training and refining these seed masks, the model reaches state-of-the-art results on unsupervised saliency detection and object discovery benchmarks. Moreover, we show that our approach yields good results in the unsupervised semantic segmentation retrieval task.
RangeViT: Towards Vision Transformers for 3D Semantic Segmentation in Autonomous Driving
Authors: Angelika Ando, Spyros Gidaris, Andrei Bursuc, Gilles Puy, Alexandre Boulch, Renaud Marlet
[Paper] [Code] [Video] [Project page]
Semantic segmentation of LiDAR point clouds permits vehicles to perceive their surrounding 3D environment independently of the lighting condition, providing useful information to build safe and reliable vehicles. A common approach to segment large scale LiDAR point clouds is to project the points on a 2D surface and then to use regular CNNs, originally designed for images, to process the projected point clouds. These projection-based methods usually benefit from fast computations and, when combined with techniques which use other point cloud representations, achieve state-of-the-art results.
Today, projection-based methods leverage 2D CNNs but recent advances in computer vision show that vision transformers (ViTs) have achieved state-of-the-art results in many image-based benchmarks. Despite the absence of almost any domain-specific inductive bias apart from the image tokenization process, ViTs have a strong representation learning capacity and achieve excellent results on various image perception tasks, such as image classification, object detection or semantic segmentation. Inspired by this success of ViTs for image understanding, in this work, we show that projection-based methods for 3D semantic segmentation can benefit from these latest improvements on ViTs when combined with three key ingredients, all described in our paper.
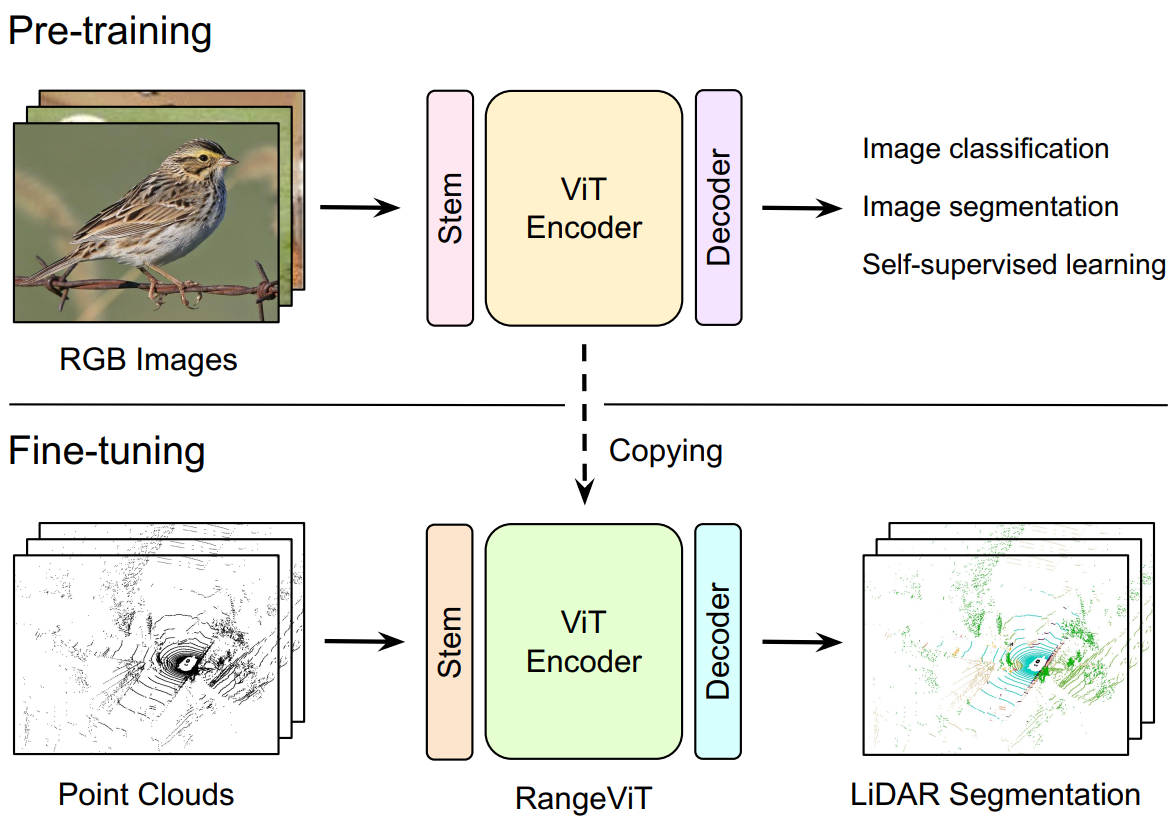
We answer positively but only after combining them with three key ingredients: (a) ViTs are notoriously hard to train and require a lot of training data to learn powerful representations. By preserving the same backbone architecture as for RGB images, we can exploit the knowledge from long training on large image collections that are much cheaper to acquire and annotate than point clouds. We reach our best results with pre-trained ViTs on large image datasets. (b) We compensate for ViTs’ lack of inductive bias by substituting a tailored non-linear convolutional stem for the classical linear embedding layer. (c) We refine pixel-wise predictions with a convolutional decoder and a skip connection from the convolutional stem to combine low-level but fine-grained features of the convolutional stem with the high-level but coarse predictions of the ViT encoder. With these ingredients, we show that our method, called RangeViT, outperforms prior projection-based methods on nuScenes and SemanticKITTI.
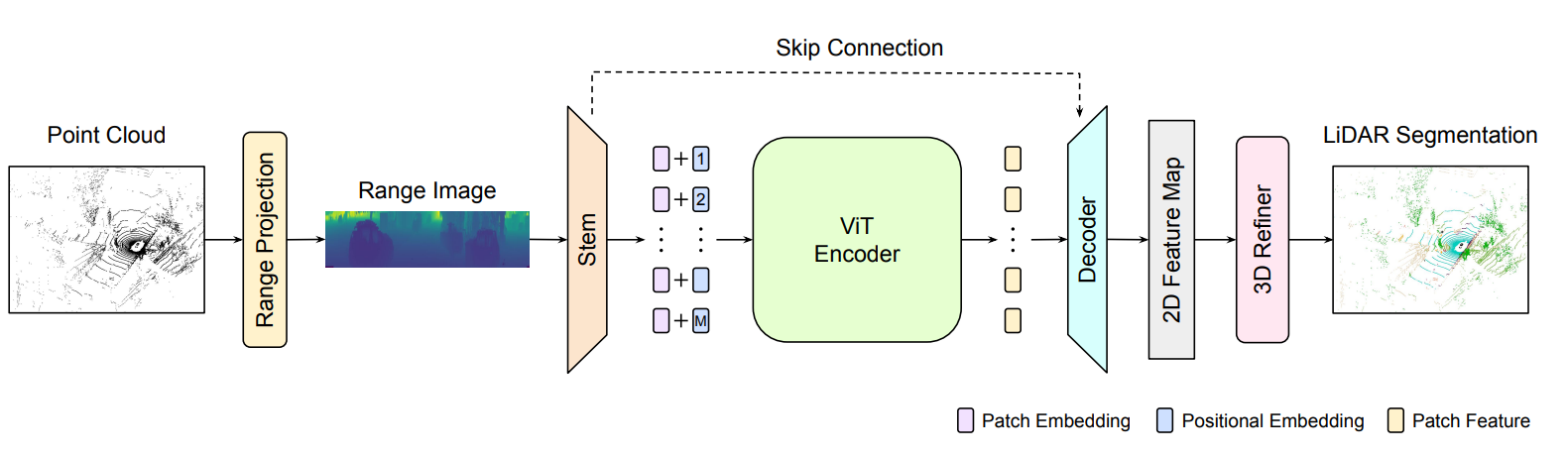
In summary, our work offers the following contributions:
- Exploiting the powerful representation learning capacity of vision transformers for LiDAR semantic segmentation.
- Unifying the network architectures for processing LiDAR point clouds and images, enabling advancements in one domain to benefit both.
- Demonstrating the utilization of pre-trained ViTs on large-scale natural image datasets for LiDAR point cloud segmentation.
We believe that this finding is highly intriguing. The RangeViT approach can leverage off-the-shelf pre-trained ViT models, enabling direct benefits from ongoing and future advances in training ViT models with natural RGB images - a rapidly growing research field.