valeo.ai at CVPR 2022
Corentin Sautier, Alexandre Boulch, Patrick Pérez, Éloi Zablocki, Tuan-Hung Vu, Matthieu Cord, Andrei Bursuc
The IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR) is a major event for researchers and engineers working on computer vision and machine learning. At the 2022 edition the valeo.ai team will present four papers in the main conference, three papers in workshops and one workshop keynote. The team will be at CVPR to present these works and will be happy to discuss more about these projects and ideas, and share our exciting ongoing research.
Image-to-Lidar Self-Supervised Distillation for Autonomous Driving Data
Authors: Corentin Sautier, Gilles Puy, Spyros Gidaris, Alexandre Boulch, Andrei Bursuc, Renaud Marlet
[Paper] [Code] [Project page]
Self-driving vehicles require object detection or segmentation to safely maneuver in their environment. Such safety-critical tasks are usually performed by neural networks demanding huge Lidar datasets with high quality annotations, and no domain shift between training and testing conditions. However, annotating 3D Lidar data for these tasks is tedious and costly. In Image-to-Lidar Self-Supervised Distillation for Autonomous Driving Data, we propose a self-supervised pre-training method for 3D perception models that is tailored to autonomous driving data and that does not require any annotation. Specifically, we leverage the availability of synchronized and calibrated image and Lidar data in autonomous driving setups for distilling self-supervised pre-trained image representations into 3D models, using neither point cloud nor image annotations.
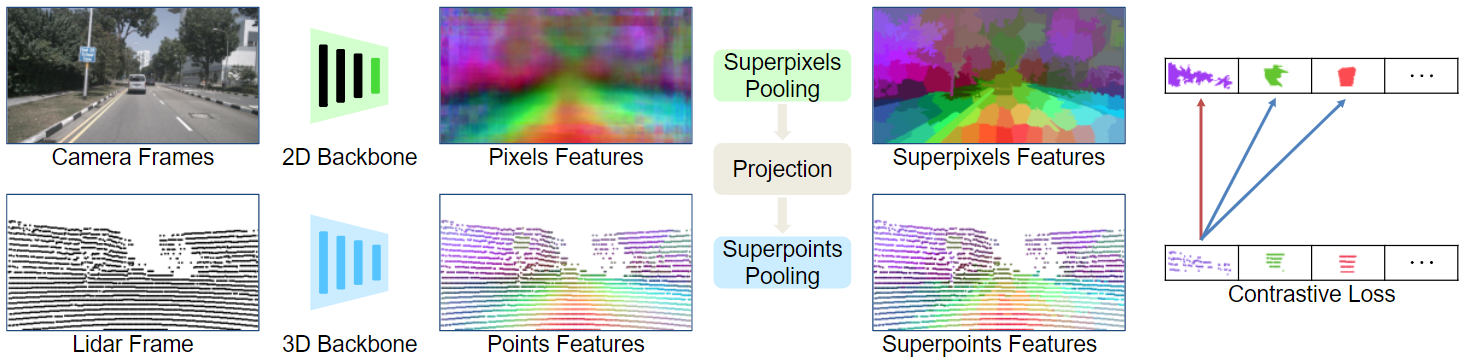
A key ingredient of our method is the use of superpixels which are used to pool 3D point features and 2D pixel features in visually similar regions. We then train a 3D network on the self-supervised task of matching these pooled 3D-point features with the corresponding pooled image pixel features. Extensive experiments on autonomous driving datasets demonstrate the ability of our image-to-Lidar distillation strategy to produce 3D representations that transfer well to semantic segmentation and object detection tasks.

With our pre-training, a Lidar network can learn features that are mostly consistent within an object class. This pre-training greatly improves data annotation efficiency, both in semantic segmentation and object detection, and is even applicable in cross-dataset setups.
Raw High-Definition Radar for Multi-Task Learning
Authors: Julien Rebut, Arthur Ouaknine, Waqas Walik, Patrick Pérez
[Paper] [Code] [Project page]
With their robustness to adverse weather conditions and their ability to measure speeds, radar sensors have been part of the automotive landscape for more than two decades. Recent progress toward High Definition (HD) Imaging radars has driven the angular resolution below the degree, thus approaching laser scanning performance. However, the amount of data a HD radar delivers and the computational cost to estimate the angular positions remain a challenge. In this paper, we propose a novel HD radar sensing model, FFT-RadNet, that eliminates the overhead of computing the range-azimuth-Doppler 3D tensor, learning instead to recover angles from a range-Doppler spectrum. This architecture can be leveraged for various perception tasks with raw HD radar signals. In particular we show how to train FFT-RadNet both to detect vehicles and to segment free driving space. On both tasks, it competes with the most recent radar-based models while requiring less compute and memory.
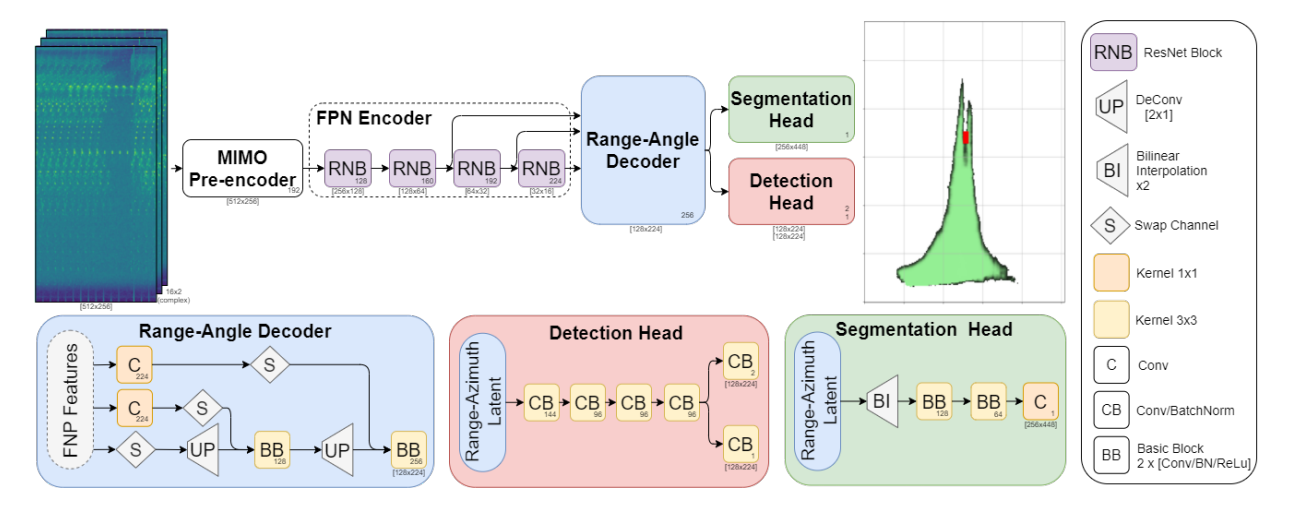
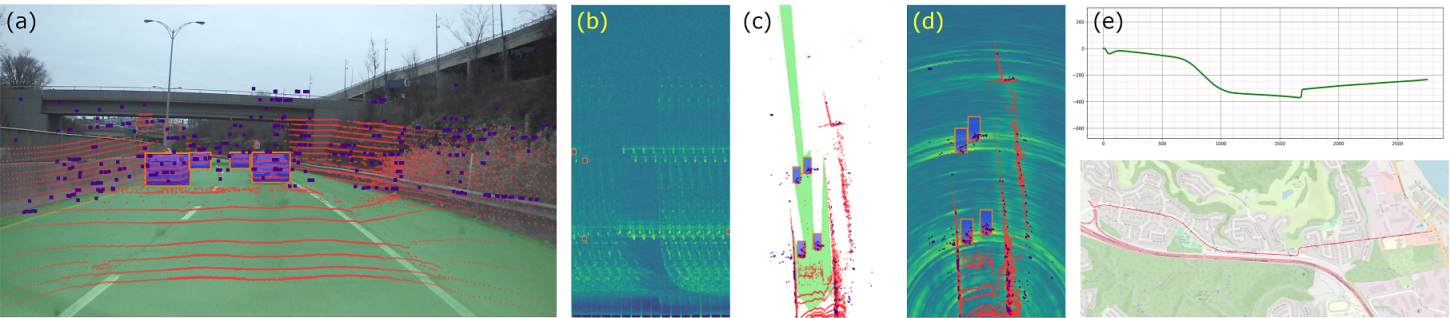
Also, and importantly, we collected and annotated 2-hour worth of raw data from synchronized automotive-grade sensors (camera, laser, HD radar) in various environments (city street, highway, countryside road). This unique dataset, nick-named RADIal for “Radar, Lidar et al.”, is publicly available.
POCO: Point convolution for surface reconstruction
Authors: Alexandre Boulch, Renaud Marlet
[Paper] [Code] [Project page]
Implicit neural networks have been successfully used for surface reconstruction from point clouds. However, many of them face scalability issues as they encode the isosurface function of a whole object or scene into a single latent vector. To overcome this limitation, a few approaches infer latent vectors on a coarse regular 3D grid or on 3D patches, and interpolate them to answer occupancy queries. In doing so, they lose the direct connection with the input points sampled on the surface of objects, and they attach information uniformly in space rather than where it matters the most, i.e., near the surface. Besides, relying on fixed patch sizes may require discretization tuning.
In POCO, we propose to use point cloud convolution and compute a latent vector at each input point. We then perform a learning-based interpolation on nearest neighbors using inferred weights. On the one hand, using a convolutional backbone allows the aggregation of global information about the shape needed to correctly orientate the surface (decide which side of the surface is inside or outside). On the other hand, surface location is inferred via a local attention-based approach which enables accurate surface positioning.
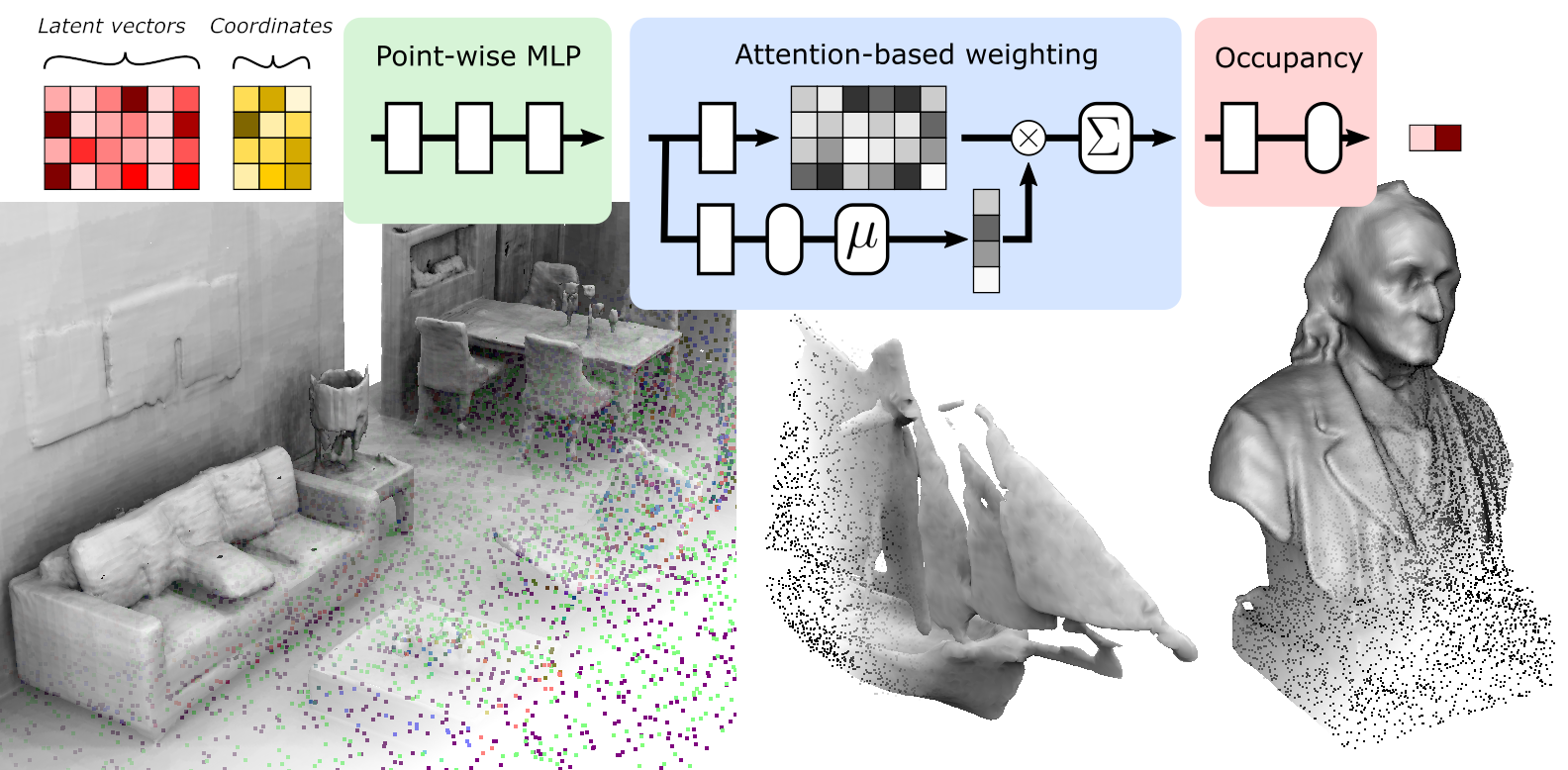
We show that our approach, while being very simple to set up, reaches the state of the art on several reconstruction-from-point-cloud benchmarks. It underlines the importance of reasoning about the surface location at a local scale, close to the input points. POCO also shows good generalization properties including the possibility of learning on object datasets while being able to reconstruct complex scenes.
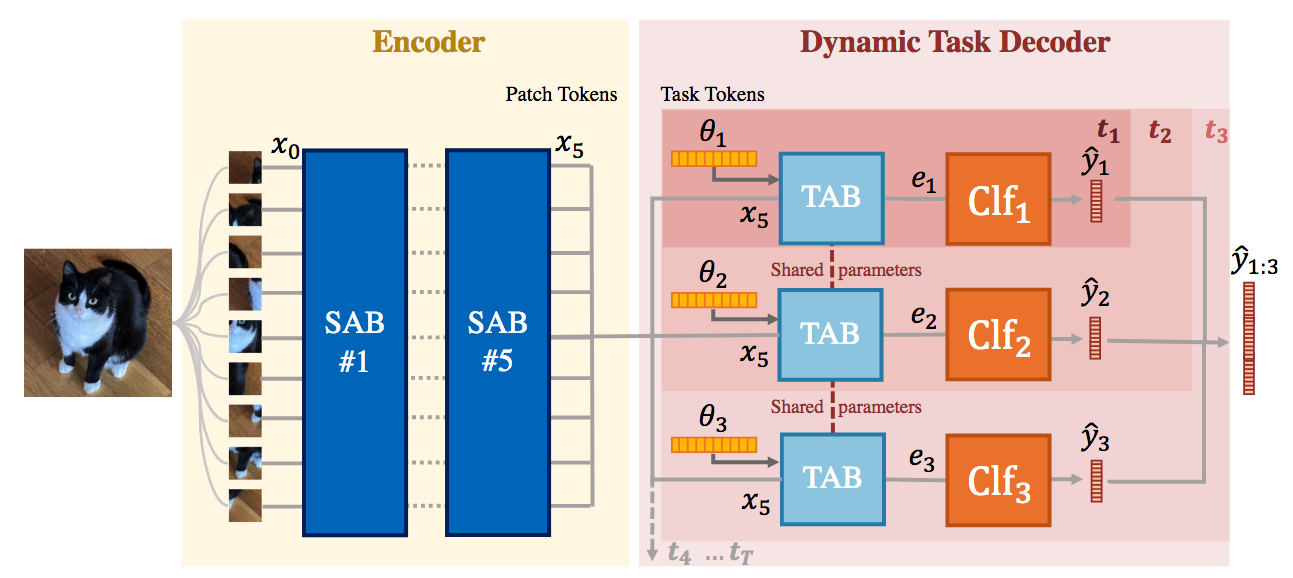
DyTox: Transformers for Continual Learning with DYnamic TOken eXpansion
Authors: Arthur Douillard, Alexandre Ramé, Guillaume Couairon, Matthieu Cord
[Paper] [Code]
Deep network architectures struggle to continually learn new tasks without forgetting the previous tasks. In this paper, we propose a transformer architecture based on a dedicated encoder/decoder framework. Critically, the encoder and decoder are shared among all tasks. Through a dynamic expansion of special tokens, we specialize each forward of our decoder network on a task distribution. Our strategy scales to a large number of tasks while having negligible memory and time overheads due to strict control of the parameters expansion. Moreover, this efficient strategy does not need any hyperparameter tuning to control the network’s expansion. Our model reaches excellent results on CIFAR100 and state-of-the-art performances on the large-scale ImageNet100 and ImageNet1000 while having fewer parameters than concurrent dynamic frameworks.
FlexIT: Towards Flexible Semantic Image Translation
Authors: Guillaume Couairon, Asya Grechka, Jakob Verbeek, Holger Schwenk, Matthieu Cord
[Paper]
Deep generative models, like GANs, have considerably improved the state of the art in image synthesis, and are able to generate near photo-realistic images in structured domains such as human faces. We propose FlexIT, a novel method which can take any input image and a user-defined text instruction for editing. Our method achieves flexible and natural editing, pushing the limits of semantic image translation. First, FlexIT combines the input image and text into a single target point in the CLIP multimodal embedding space. Via the latent space of an auto-encoder, we iteratively transform the input image toward the target point, ensuring coherence and quality with a variety of novel regularization terms. We propose an evaluation protocol for semantic image translation, and thoroughly evaluate our method on ImageNet.

Raising context awareness in motion forecasting
CVPR 2022 Workshop on Autonomous Driving
Authors: Hédi Ben-Younes, Éloi Zablocki, Mickaël Chen, Patrick Pérez, Matthieu Cord
[Paper]
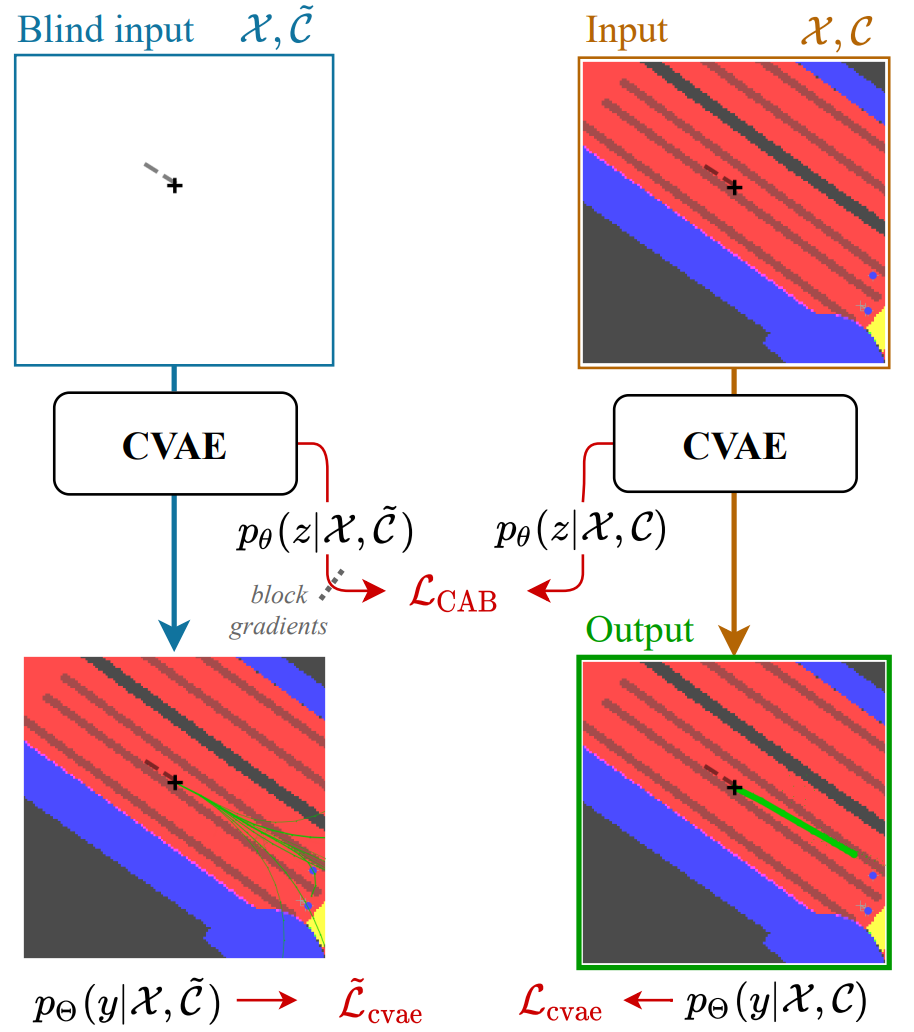
Learning-based trajectory prediction models have encountered great success, with the promise of leveraging contextual information in addition to motion history. Yet, we find that state-of-the-art forecasting methods tend to overly rely on the agent’s current dynamics, failing to exploit the semantic contextual cues provided at its input. To alleviate this issue, we introduce CAB, a motion forecasting model equipped with a training procedure designed to promote the use of semantic contextual information. We also introduce two novel metrics, dispersion and convergence-to-range, to measure the temporal consistency of successive forecasts, which we found missing in standard metrics. Our method is evaluated on the widely adopted nuScenes Prediction benchmark as well as on a subset of the most difficult examples from this benchmark.
CSG0: Continual Urban Scene Generation with Zero Forgetting
CVPR 2022 Workshop on Continual Learning (CLVision)
Authors: Himalaya Jain, Tuan-Hung Vu, Patrick Pérez, Matthieu Cord
[Paper] [Project page]
With the rapid advances in generative adversarial networks (GANs), the visual quality of synthesized scenes keeps improving, including for complex urban scenes with applications to automated driving. We address in this work a continual scene generation setup in which GANs are trained on a stream of distinct domains; ideally, the learned models should eventually be able to generate new scenes in all seen domains. This setup reflects the real-life scenario where data are continuously acquired in different places at different times. In such a continual setup, we aim for learning with zero forgetting, i.e., with no degradation in synthesis quality over earlier domains due to catastrophic forgetting. To this end, we introduce a novel framework, named CSG0, that not only (i) enables seamless knowledge transfer in continual training but also (ii) guarantees zero forgetting with a small overhead cost.
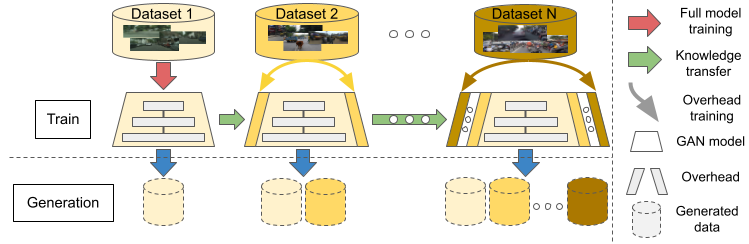
To showcase the merit of our framework, we conduct intensive experiments on various continual urban scene setups, covering both synthetic-to-real and real-to-real scenarios. Quantitative evaluations and qualitative visualizations demonstrate the interest of our CSG0 framework, which operates with minimal overhead cost (in terms of architecture size and training). Benefiting from continual learning, CSG0 outperforms the state-of-the-art OASIS model trained on single domains. We also provide experiments with three datasets to emphasize how well our strategy generalizes despite its cost constraints. Under extreme low-data regimes, our approach outperforms the baseline by a large margin.
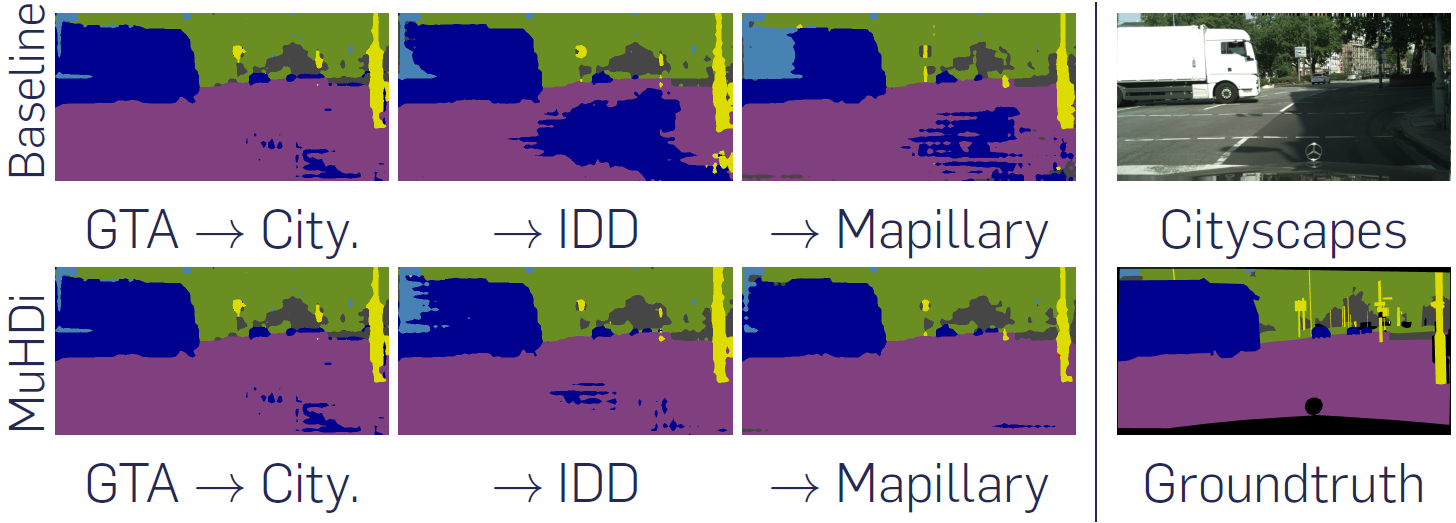
Multi-Head Distillation for Continual Unsupervised Domain Adaptation in Semantic Segmentation
CVPR 2022 Workshop on Continual Learning (CLVision)
Authors: Antoine Saporta, Arthur Douillard, Tuan-Hung Vu, Patrick Pérez, Matthieu Cord
[Paper] [Code] [Project page]
This work focuses on a novel framework for learning UDA, continuous UDA, in which models operate on multiple target domains discovered sequentially, without access to previous target domains. We propose MuHDi, for Multi-Head Distillation, a method that solves the catastrophic forgetting problem, inherent in continual learning tasks. MuHDi performs distillation at multiple levels from the previous model as well as an auxiliary target-specialist segmentation head. We report both extensive ablation and experiments on challenging multi-target UDA semantic segmentation benchmarks to validate the proposed learning scheme and architecture.
References
- Chen, X., Fan, H., Girshick, R., & He, K. (2020). Improved baselines with momentum contrastive learning. ArXiv Preprint ArXiv:2003.04297.