valeo.ai at ICCV 2021
Andrei Bursuc, Gilles Puy, Arthur Ouaknine, Antoine Saporta
The International Conference on Computer Vision (ICCV) is a top event for researchers and engineers working on computer vision and machine learning. The valeo.ai team will present six papers in the main conference, four of which are presented below. Join us to find out more about these projects and ideas, meet our team and learn about our exciting ongoing research. See you at ICCV!
Multi-View Radar Semantic Segmentation
Authors: Arthur Ouaknine, Alasdair Newson, Patrick Pérez, Florence Tupin, Julien Rebut
[Paper] [Code] [Project page]

Understanding the scene around the ego-vehicle is key to assisted and autonomous driving. Nowadays, this is mostly conducted using cameras and laser scanners, despite their reduced performance in adverse weather conditions. Automotive radars are low-cost active sensors that measure properties of surrounding objects, including their relative speed, and have the key advantage of not being impacted by rain, snow or fog and could effectively complement the other perception sensors mounted on the car, e.g., cameras, LIDAR. However, they are seldom used for scene understanding due to the size and complexity of radar raw data and the lack of annotated datasets. Fortunately, recent open-sourced datasets have opened up research on classification, object detection and semantic segmentation with raw radar signals using end-to-end trainable models.
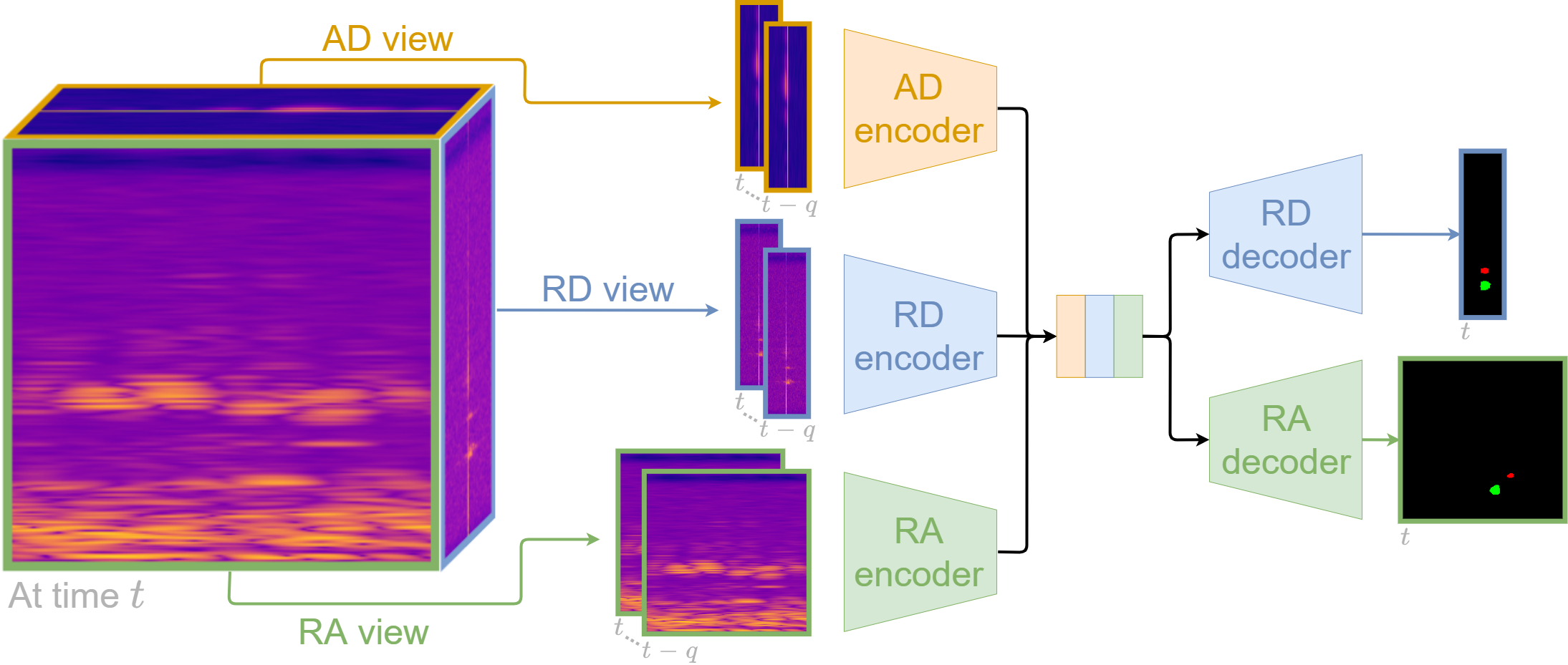
In our paper, Multi-View Radar Semantic Segmentation, we propose a set of deep neural network architectures to segment simultaneously range-angle and range-Doppler radar representations, providing the location and the radial velocity of the detected objects. Our best model takes a sequence of radar views as input, extracts features using individual branches including ASPP blocks, and recovers the range-angle and range-Doppler view dimensions with two decoding branches. We also propose a combination of loss functions composed of a weighted cross entropy, a soft dice and an additional coherence term. We introduce a coherence loss to impose a spatial consistency between the segmented radar views. Our experiments on the CARRADA dataset (Ouaknine et al., 2021) demonstrate that our best model outperforms competing methods with a large margin while requiring significantly fewer parameters.
Triggering Failures: Out-Of-Distribution detection by learning from local adversarial attacks in Semantic Segmentation
Authors: Victor Besnier, Andrei Bursuc, Alexandre Briot, David Picard
[Paper] [Code] [Project page]

For real-world decision systems such as autonomous vehicles, accuracy is not the only performance requirement and it often comes second to reliability, robustness, and safety concerns, as any failure carries serious consequences. Component modules of such systems frequently rely on powerful Deep Neural Networks (DNNs), that however do not always generalize to objects unseen in the training data. Simple uncertainty estimation techniques, e.g., entropy of softmax predictions, are less effective since modern DNNs are consistently overconfident on both in-domain and out-of-distribution (OOD) data samples. This hinders further the performance of downstream components relying on their predictions. Dealing successfully with the “unknown unknown”, e.g., by launching an alert or failing gracefully, is crucial.

In this work we take inspiration from practices in industrial validation, where the performance of a target model is tested in various extreme cases. Instead of simply verifying the performance of the model we learn how this model behaves in face of failures. To this end we propose a new OOD detection architecture called ObsNet and an associated training scheme based on Local Adversarial Attacks (LAA). Finding failure modes in a trained DNN is quite challenging as such models typically achieve high accuracy, i.e., are rarely wrong, and corner-case samples are rather inserted in the training set than used for validation. LAA triggers failure modes in the target model that are a good proxy for failures in face of unknown OOD data. ObsNet achieves reliable detection of failure and OOD objects without compromising on predictive accuracy and computational time.
Multi-Target Adversarial Frameworks for Domain Adaptation in Semantic Segmentation
Authors: Antoine Saporta, Tuan-Hung Vu, Matthieu Cord, Patrick Pérez
[Paper] [Code] [Project page]
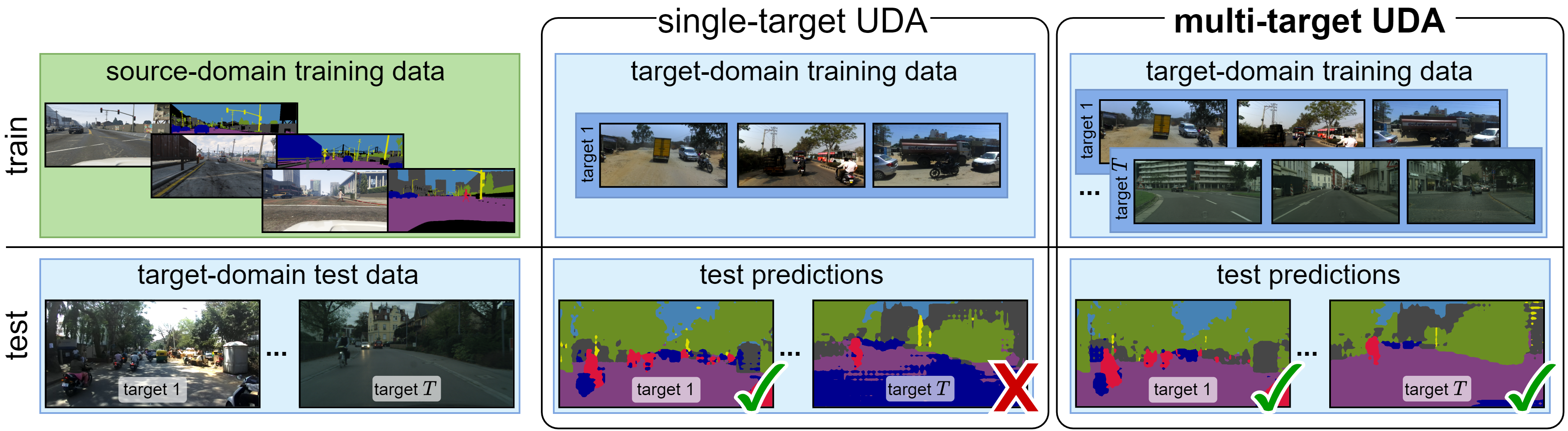
Autonomous vehicles rely on perception models that require a tremendous amount of annotated data to be trained in a supervised fashion. To reduce the reliance on manual annotation which can get extremely expensive when we consider semantic segmentation of urban scenes for instance, domain adaptation is a popular topic that leverages annotated data from a source domain to train a model on a target domain. More specifically, the unsupervised domain adaptation (UDA) setting only relies on unlabeled data from the target domain and aims at bridging the gap between target and source domains. Most UDA approaches tackle the alignment between a single source domain and a single target domain but don’t generalize well to more domains. Yet, real-world perception systems need to be confronted to a variety of scenarios, such as multiple cities or multiple weather conditions, motivating to extend UDA to multi-target settings.
In our work, Multi-Target Adversarial Frameworks for Domain Adaptation in Semantic Segmentation, we introduce two UDA frameworks to tackle multi-target adaptation: (i) multi-discriminator, which extends single target UDA approaches to multiple target domains by explicitly aligning each target domain to its counterparts; (ii) multi-target knowledge transfer, which learns a target-agnostic model thanks to a multiple teachers/single student distillation mechanism. We also propose multiple new challenging evaluation benchmarks for multi-target UDA in semantic segmentation based on existing urban scenes datasets.
PCAM: Product of Cross-Attention Matrices for Rigid Registration of Point Clouds
Authors: Anh-Quan Cao, Gilles Puy, Alexandre Boulch, Renaud Marlet
[Paper] [Code] [Project page]
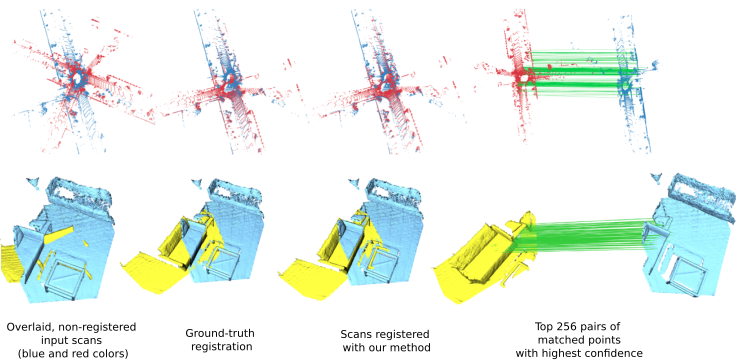
Point cloud registration has many applications in various domains such as autonomous driving, motion and pose estimation, 3D reconstruction, simultaneous localisation and mapping (SLAM), and augmented reality. The most famous method to solve this task is ICP, but is mostly suited for small transformations. Several improvements have been made and the most recent techniques leverage deep learning.
The typical pipeline for point cloud registration is (a) point matching followed by (b) point-pairs filtering to remove incorrect matches in, e.g., non-overlapping regions. One natural way to improve this pipeline is to use deep learning in step (a) to obtain point features of high quality and get pairs of matching points with a nearest neighbors search in this learned feature space. Then, one can typically rely on a classical RANSAC-based method in step (b). Another category of methods exploits deep learning in step (a) and step (b), as proposed by, e.g., DCP, PRNet, DGR. PCAM belongs to this second category where a first network outputs pairs of matching points and a second network filters incorrect pairs.
We construct PCAM by observing that one needs two types of information to correctly match points between two point clouds. First, one needs local fine geometric information to precisely select the best corresponding point. Second, one also needs high-level contextual information to differentiate between points with similar local geometry but from different parts of the scene. Therefore, we compute point correspondences at every layer of our deep network via cross-attention matrices, and combine these matrices via a pointwise multiplication. This simple yet very effective solution naturally ensures that both low-level geometric and high-level context information are exploited when matching points. It also permits to remove spurious matches found only at one scale. Furthermore, these cross-attention matrices are also exploited to exchange information between the point clouds at each layer, allowing the network to use context information to find the best matching point within the overlapping regions.
References
- Ouaknine, A., Newson, A., Rebut, J., Tupin, F., & Pérez, P. (2021). CARRADA Dataset: Camera and Automotive Radar with Range- Angle- Doppler Annotations. 2020 25th International Conference on Pattern Recognition (ICPR), 5068–5075.