ADVENT - Adversarial Entropy Minimization for Domain Adaptation in Semantic Segmentation
Tuan-Hung Vu, Andrei Bursuc
This post describes our recent work on unsupervised domain adaptation for semantic segmentation presented at CVPR 2019. ADVENT is a flexible technique for bridging the gap between two different domains through entropy minimization. Our work builds upon a simple observation: models trained only on source domain tend to produce over-confident, i.e., low-entropy, predictions on source-like images and under-confident, i.e., high-entropy, predictions on target-like ones. Consequently by minimizing the entropy on the target domain, we make the feature distributions from the two domains more similar. We show that our approach achieves competitive performances on standard semantic segmentation benchmarks and that it can be successfully extended to other tasks such as object detection.
Visual perception is a remarkable ability that human drivers leverage for understanding their surroundings and for supporting the multiple micro-decisions needed in traffic. Since many years, researchers have been working on mimicking this human capability by means of computer algorithms. This research field is known as computer vision and it has seen impressive progress and wide adoption. Most of the modern computer vision systems rely on Deep Neural Networks (DNNs) which are powerful and widely employed tools able to learn from large amounts of data and make accurate predictions. In autonomous driving, DNN-based visual perception is also at the heart of the complex architectures under intelligent cars, and supports downstream decisions of the vehicle, e.g., steering, braking, signaling, etc.
The diversity and complexity of the situations encountered in real-world driving is tremendous. Unlike humans who can extrapolate effortlessly from previous experience in order to adapt to new environments and conditions, the scope of DNNs beyond the types of conditions and scenes seen during training is limited. For instance a model trained on data from a sunny country, would have a hard time delivering the same performance on streets with mixed weather conditions in a different country (with different urban architecture, furniture, vegetation, types of cars and pedestrian appearance and clothing). Similarly a model trained on a particular type of camera, is expected to see a drop in performance with images coming from a camera with different specifications. This difference between environments that leads to performance drops is referred to as domain gap.
Bridging domains
We can resort to two options for narrowing the domain gap: (i) annotate more data; (ii) leverage the experience acquired on an initial environment and transfer it to the new environment. More annotated data has been shown to always improve performance of DNNs (Sun et al., 2017). However the labeling process brings a significant financial and temporal burden. The time required for a high-quality annotation, such as the ones from the popular Cityscapes dataset is ∼90 minutes per image (Cordts et al., 2016). The amount of images required to train high performance DNNs typically counts in hundreds of thousands. The acquisition of diverse data across seasons and weather conditions adds up even more time. It makes then sense to look for a solution elsewhere and the second option seems now more appealing, though achieving it remains technically challenging. This is actually the area of research of domain adaptation (DA) which addresses the domain-gap problem by transferring knowledge from a source domain (with full annotations) to a target domain (with fewer annotations if any), aiming to reach good performances on target samples. DA has consistently attracted interest from different communities across years (Csurka, 2017).
Here we are working on Unsupervised DA (UDA), which is a more challenging task where we have access to labeled source samples and only unlabeled target samples. We use as source, data generated by a simulator or video game engine, while for target we consider real-data from car-mounted cameras. In Figure 1 we illustrate the difficulty of this task and the impact of our UDA technique, ADVENT.

The main approaches for UDA include discrepancy minimization between source and target feature distributions usually achieved via adversarial training (Ganin & Lempitsky, 2015), (Tzeng et al., 2017), self-training with pseudo-labels (Zou et al., 2018) and generative approaches (Hoffman et al., 2018), (Wu et al., 2018).
Entropy minimization has been shown to be useful for semi-supervised learning (Grandvalet & Bengio, 2005), clustering (Jain et al., 2018) and more recently to domain adaptation for classification (Long et al., 2016). We chose to explore entropy based UDA training to obtain competitive performance on semantic segmentation.
Approach
We present our two proposed approaches for entropy minimization using (i) an unsupervised entropy loss and (ii) adversarial training. To build our models, we start from existing semantic segmentation frameworks and add an additional network branch used for domain adaptation. Figure 2 illustrates our architectures.
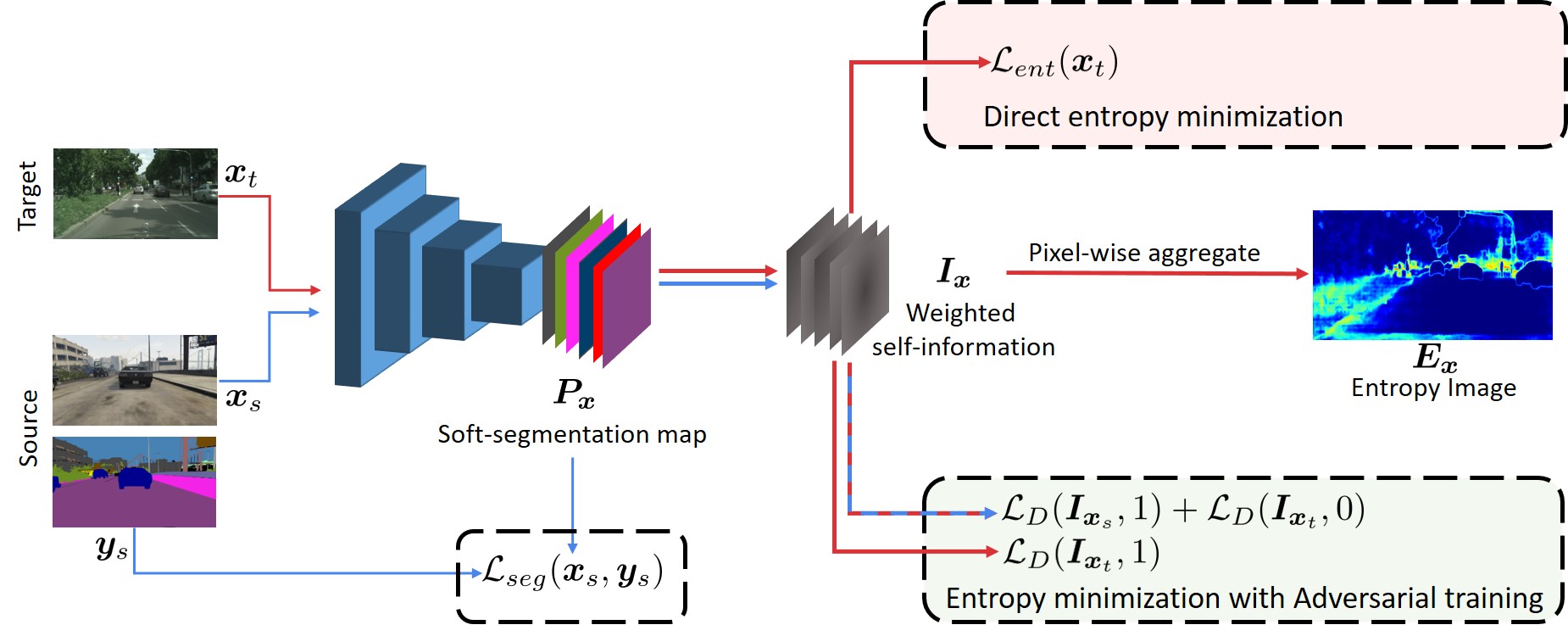
Direct entropy minimization
On the source domain we train our model, denoted as $F$, as usual using a supervised loss. For the target domain, we do not have annotations and we can no longer use the segmentation loss to train $F$. We notice that models trained only on source domain tend to produce over-confident predictions on source-like images and under-confident predictions on target-like ones. Motivated by this observation, we propose a supervision signal that could leverage visual information from the target samples, in spite of the lack of annotations. The objective is to constrain $F$ to produce high-confident predictions on target samples similarly to source samples. To this effect, we introduce the entropy loss $\mathcal{L}_{ent}$ to maximize directly the prediction confidence in the target domain. Here we consider the Shannon Entropy (Shannon). During training, we jointly optimize the supervised segmentation loss $\mathcal{L}_{seg}$ on source samples and the unsupervised entropy loss $\mathcal{L}_{ent}$ on target samples.
Entropy minimization by adverarial learning
A limitation of the entropy loss is related to the absence of structural dependencies between local semantics. This is caused by the aggregation of the pixel-wise prediction entropies by summation. We address this through a unified adversarial training framework which minimizes indirectly the entropy of target data, by encouraging it to become similar to the source one. This allows the exploitation of the structural consistency between the domains. To this end, we formulate the UDA task as minimizing distribution distance between source and target on the weighted self-information space. Since the trained model produces naturally low-entropy predictions on source-like images, by aligning weighted self-information distributions of target and source domains, we reach the same behavior on target-like data.
We perform the adversarial adaptation on weighted self-information maps using a fully-convolutional discriminator network $D$. The discriminator produces domain classification outputs, i.e., class label $1$ (resp. $0$) for the source (resp. target) domain. We train $D$ to discriminate outputs coming from source and target images, and at the same time, train the segmentation network to fool the discriminator.
Experiments
We evaluate our approaches on the challenging synthetic-2-real unsupervised domain adaptation set-ups. Models are trained on fully-annotated synthetic data and are validated on real-world data. In such set-ups, the models have access to some unlabeled real images during training.
Semantic Segmentation
To train our models, we use either GTA5 (Richter et al., 2016) or SYNTHIA (Ros et al., 2016) as source synthetic data, along with the training split of Cityscapes dataset (Cordts et al., 2016) as target domain data.
In Table 1 we report our results on semantic segmentation from models trained on GTA5 $\rightarrow$ Cityscapes and from SYNTHIA $\rightarrow$ Cityscapes. We compare here only with the top performing method Adapt-SegMap (Tsai et al., 2018), while additional baselines and related methods are covered in the paper.
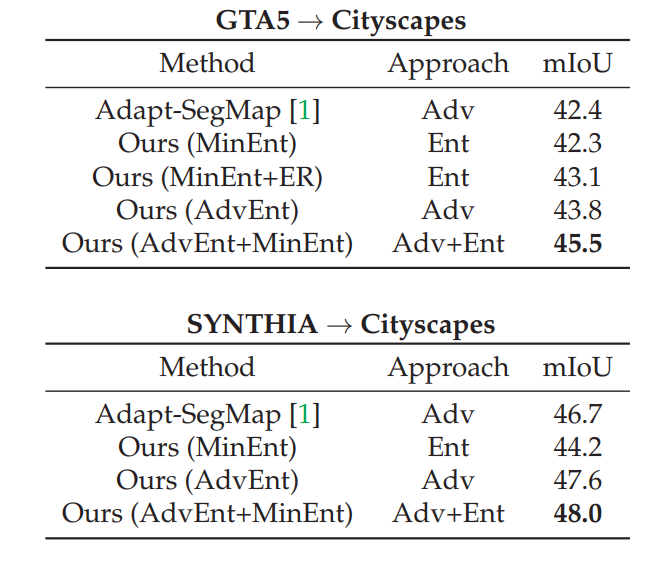
Our first approach of direct entropy minimization (MinEnt) achieves comparable performance to state-of-the-art baselines. The light overhead of the entropy loss makes training time shorter for the MinEnt model, while being easier train compared to adversarial networks. Our second approach using adversarial training on the weighted self-information space, noted as AdvEnt, shows consistent improvement to the baselines. In general, AdvEnt works better than MinEnt, confirming the importance of structural adaptation. The two approaches are complementary as their combination boosts performance further.
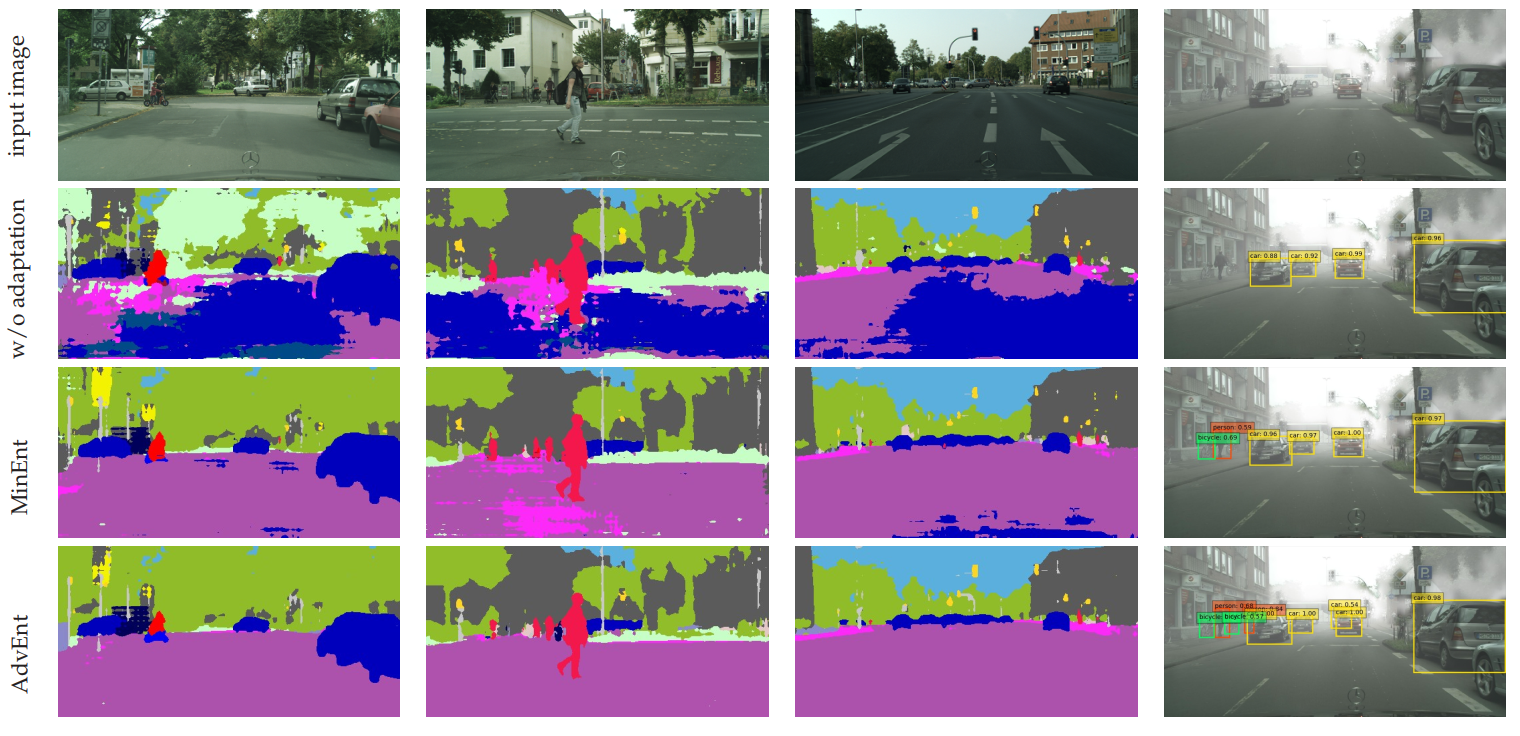
In Figure 3, we illustrate a few qualitative results of our models. Without domain adaptation, the model trained only on source supervision produces noisy segmentation predictions as well as high entropy activations, with a few exceptions on some classes like “building” and “car”. However, there are many confident predictions (low entropy) which are completely wrong. Our models, on the other hand, manage to produce correct predictions at high level of confidence.
UDA for object detection
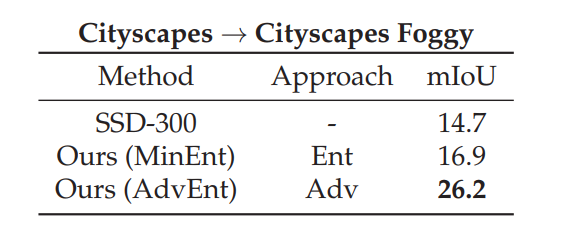
The proposed entropy-based approaches are not limited to semantic segmentation and can be applied to UDA for other recognition tasks, e.g. object detection. We conducted experiments in the UDA object detection set-up Cityscapes $\rightarrow$ Cityscapes-Foggy, similar to the one in (Chen et al., 2018). We report quantitative results in Table 2 and qualitative ones in Figure 3. In spite of the unfavorable factors, our improvement over the baseline ($+11.5\%$ mAP using AdvEnt) is larger than the one reported in (Chen et al., 2018) ($+8.8\%$). Additional experiments and implementation details can be found in the paper. These encouraging preliminary results suggest the feasibility of applying entropy-based approached on UDA for detection.
Conclusion
In this work, we propose two approaches for unsupervised domain adaptation reaching state-of-the-art performances on standard synthetic-2-real benchmarks. Interestingly the method can be easily extended to UDA for object detection with promising preliminary results. Check out our paper to find out more about intuitions, experiments and implementation details for AdvEnt and try out our code.
References
- Sun, C., Shrivastava, A., Singh, S., & Gupta, A. (2017). Revisiting unreasonable effectiveness of data in deep learning era. Proceedings of the IEEE International Conference on Computer Vision, 843–852.
- Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., & Schiele, B. (2016). The cityscapes dataset for semantic urban scene understanding. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3213–3223.
- Csurka, G. (2017). Domain adaptation in computer vision applications. 8.
- Ganin, Y., & Lempitsky, V. (2015). Unsupervised domain adaptation by backpropagation. International Conference on Machine Learning, 1180–1189.
- Tzeng, E., Hoffman, J., Saenko, K., & Darrell, T. (2017). Adversarial discriminative domain adaptation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7167–7176.
- Zou, Y., Yu, Z., Vijaya Kumar, B. V. K., & Wang, J. (2018). Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. Proceedings of the European Conference on Computer Vision (ECCV), 289–305.
- Hoffman, J., Tzeng, E., Park, T., Zhu, J.-Y., Isola, P., Saenko, K., Efros, A., & Darrell, T. (2018). Cycada: Cycle-consistent adversarial domain adaptation. International Conference on Machine Learning, 1989–1998.
- Wu, Z., Han, X., Lin, Y.-L., Gokhan Uzunbas, M., Goldstein, T., Nam Lim, S., & Davis, L. S. (2018). Dcan: Dual channel-wise alignment networks for unsupervised scene adaptation. Proceedings of the European Conference on Computer Vision (ECCV), 518–534.
- Grandvalet, Y., & Bengio, Y. (2005). Semi-supervised learning by entropy minimization. Advances in Neural Information Processing Systems, 529–536.
- Jain, H., Zepeda, J., Pérez, P., & Gribonval, R. (2018). Learning a complete image indexing pipeline. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4933–4941.
- Long, M., Zhu, H., Wang, J., & Jordan, M. I. (2016). Unsupervised domain adaptation with residual transfer networks. Advances in Neural Information Processing Systems, 136–144.
- Richter, S. R., Vineet, V., Roth, S., & Koltun, V. (2016). Playing for data: Ground truth from computer games. European Conference on Computer Vision, 102–118.
- Ros, G., Sellart, L., Materzynska, J., Vazquez, D., & Lopez, A. M. (2016). The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3234–3243.
- Tsai, Y.-H., Hung, W.-C., Schulter, S., Sohn, K., Yang, M.-H., & Chandraker, M. (2018). Learning to adapt structured output space for semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7472–7481.
- Chen, Y., Li, W., Sakaridis, C., Dai, D., & Van Gool, L. (2018). Domain adaptive faster r-cnn for object detection in the wild. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3339–3348.