valeo.ai at ICLR 2025
The International Conference on Learning Representations (ICLR) is a leading conference that brings together researchers and practitioners in deep learning, representation learning, and artificial intelligence. It covers a wide range of topics, including optimization, generative models, interpretability, robustness. This year, at the thirteen edition of ICLR, the valeo.ai team will present 5 papers in the main conference.
We will be happy to discuss more about these projects and ideas, and share our exciting ongoing research. Take a quick view of our papers below and come meet us at the posters or catch us for a coffee in the hallways.
Halton Scheduler For Masked Generative Image Transformer
Authors: Victor Besnier Mickael Chen David Hurych Eduardo Valle Matthieu Cord
[Paper] [Code] [Project page]
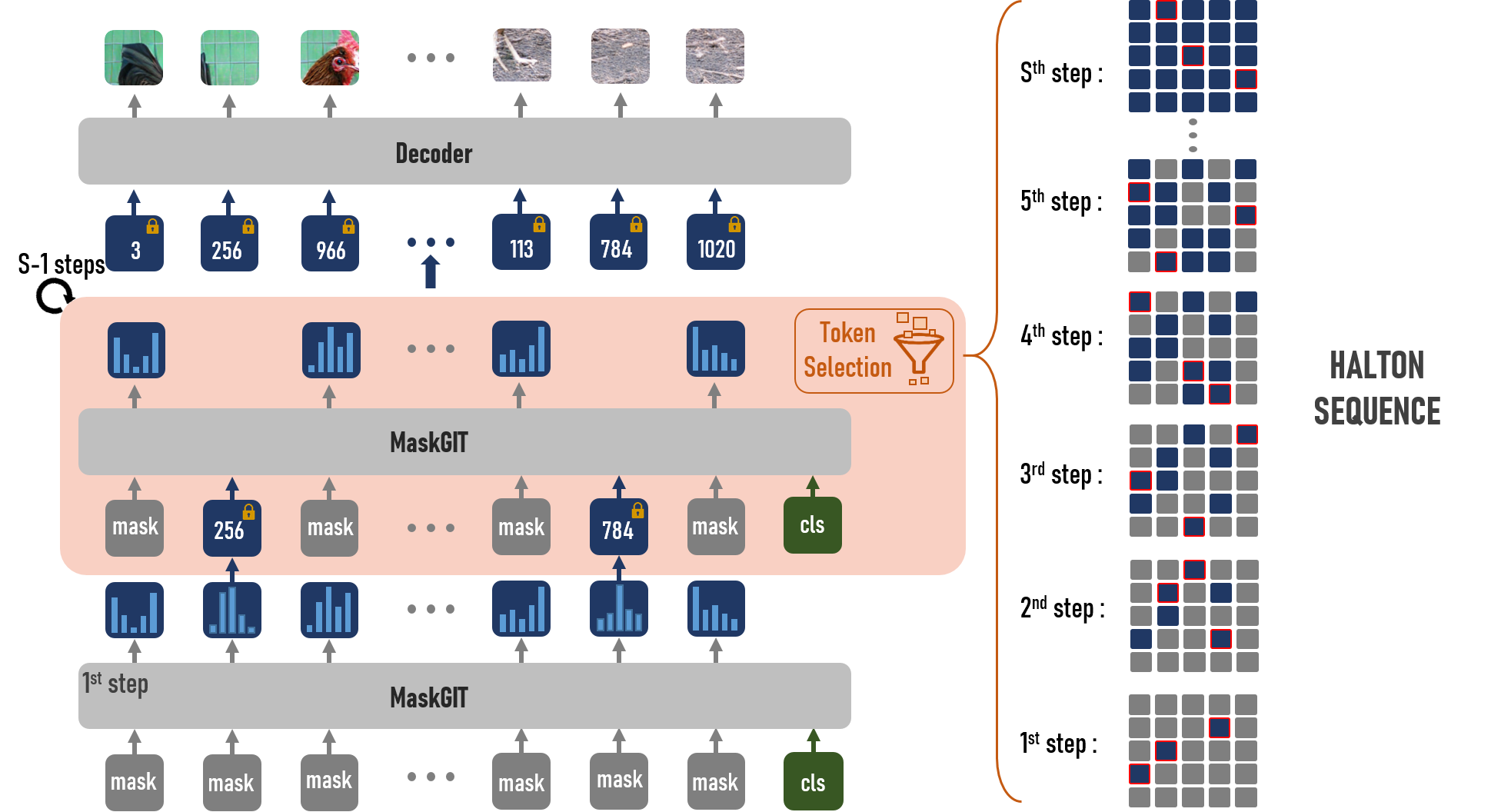
Masked Generative Image Transformers (MaskGIT) have gained popularity for their fast and efficient image generation capabilities. However, the sampling strategy used to progressively "unmask" tokens in these models plays a crucial role in determining image quality and diversity. Our new research paper, introduces the Halton Scheduler—a novel approach that significantly enhances MaskGIT's image generation performance.
From Confidence to Halton: What’s New?
Traditional MaskGIT uses a Confidence scheduler, which selects tokens based on logit distribution but tends to cluster token selection, leading to reduced image diversity. The Halton Scheduler addresses this by leveraging low-discrepancy sequences, the Halton sequence, to distribute token selection more uniformly across the image.

MaskGIT using our Halton scheduler on ImageNet 256.
Key Insights and Benefits
- Improved Image Quality and Diversity: The Halton scheduler reduces clustering of sampled tokens, enhancing image sharpness and background richness.
- No Retraining Required: This scheduler can be integrated as a drop-in replacement for the existing MaskGIT sampling strategy.
- Faster and More Balanced Sampling: By reducing token correlation, the Halton Scheduler allows MaskGIT to progressively add fine details while avoiding local sampling errors.

Figure 2: MaskGIT using our Halton scheduler for text-to-image.

Figure 3: MaskGIT using the Confidence scheduler for text-to-image.
Results: ImageNet and COCO Benchmarks
On benchmark datasets like ImageNet (256×256) and COCO, the Halton Scheduler outperforms the baseline Confidence scheduler:
- Reduced Fréchet Inception Distance (FID): Indicating better image realism.
- Improved Precision and Recall: Reflecting a more diverse image generation.
LLM-wrapper: Black-Box Semantic-Aware Adaptation of Vision-Language Models for Referring Expression Comprehension
Authors: Amaia Cardiel Éloi Zablocki Elias Ramzi Oriane Siméoni Matthieu Cord
[Paper] [Code] [Project page]

Vision Language Models (VLMs) have demonstrated remarkable capabilities in various open-vocabulary tasks, yet their zero-shot performance lags behind task-specific fine-tuned models, particularly in complex tasks like Referring Expression Comprehension (REC). Fine-tuning usually requires “white-box” access to the model’s architecture and weights, which is not always feasible due to proprietary or privacy concerns. In this work, we propose LLM-wrapper, a method for “black-box” adaptation of VLMs for the REC task using Large Language Models (LLMs). LLM-wrapper capitalizes on the reasoning abilities of LLMs, improved with a light fine-tuning, to select the most relevant bounding box matching the referring expression, from candidates generated by a zero-shot black-box VLM. Our approach offers several advantages: it enables the adaptation of closed-source models without needing access to their internal workings, it is versatile as it works with any VLM, it transfers to new VLMs and datasets, and it allows for the adaptation of an ensemble of VLMs. We evaluate LLM-wrapper on multiple datasets using different VLMs and LLMs, demonstrating significant performance improvements and highlighting the versatility of our method. While LLM-wrapper is not meant to directly compete with standard white-box fine-tuning, it offers a practical and effective alternative for black-box VLM adaptation.

MOCA: Self-supervised Representation Learning by Predicting Masked Online Codebook Assignments
Authors: Spyros Gidaris Andrei Bursuc Oriane Siméoni Antonin Vobecky Nikos Komodakis Matthieu Cord Patrick Pérez
[Paper] [Code] [Project page]
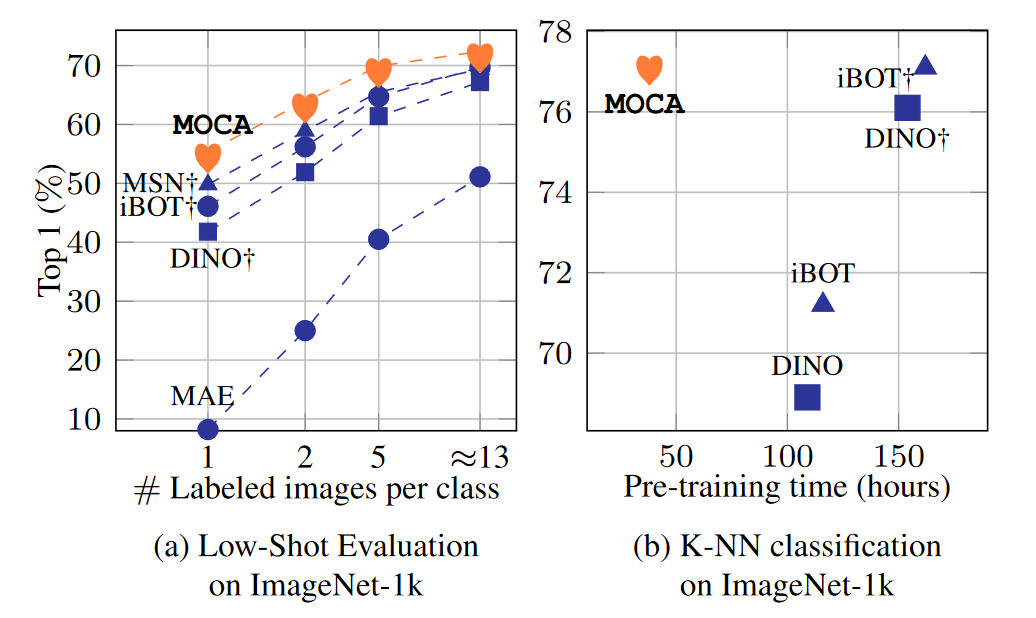
Self-supervised learning can be used for mitigating the greedy needs of Vision Transformer networks for very large fully-annotated datasets. Different classes of self-supervised learning offer representations with either good contextual reasoning properties, e.g., using masked image modeling strategies, or invariance to image perturbations, e.g., with contrastive methods. In this work, we propose a single-stage and standalone method, MOCA, which unifies both desired properties using novel mask-and-predict objectives defined with high-level features (instead of pixel-level details). Moreover, we show how to effectively employ both learning paradigms in a synergistic and computation-efficient way. Doing so, we achieve new state-of-the-art results on low-shot settings and strong experimental results in various evaluation protocols with a training that is at least 3 times faster than prior methods.
Learning a Neural Solver for Parametric PDEs to Enhance Physics-Informed Methods
Authors: Lise Le Boudec Emmanuel de Bezenac Louis Serrano Ramon Daniel Regueiro-Espino Yuan Yin Patrick Gallinari
[Paper] [Code] [Project page]
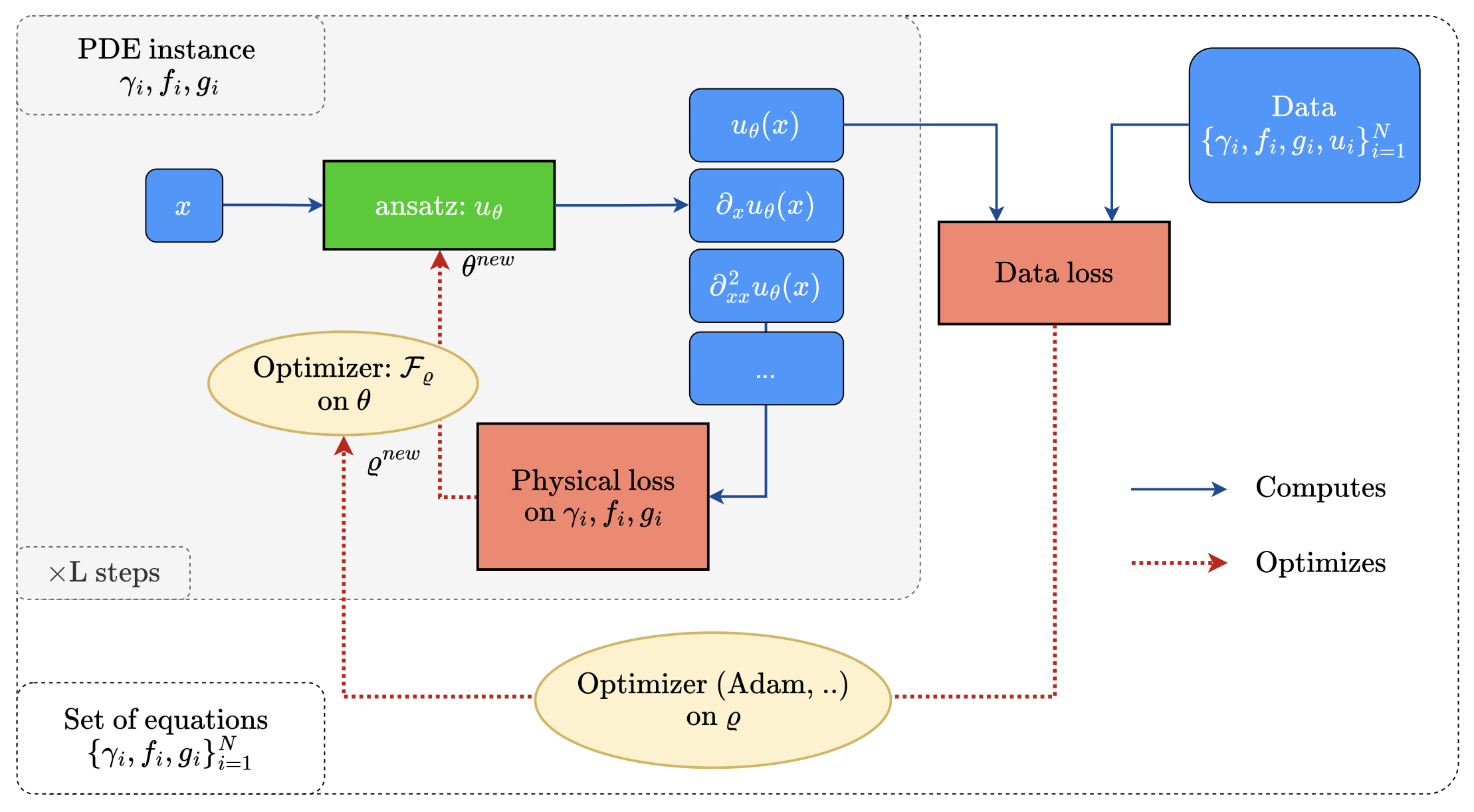
Physics-informed deep learning often faces optimization challenges due to the complexity of solving partial differential equations (PDEs), which involve exploring large solution spaces, require numerous iterations, and can lead to unstable training. These challenges arise particularly from the ill-conditioning of the optimization problem, caused by the differential terms in the loss function. To address these issues, we propose learning a solver, i.e., solving PDEs using a physics-informed iterative algorithm trained on data. Our method learns to condition a gradient descent algorithm that automatically adapts to each PDE instance, significantly accelerating and stabilizing the optimization process and enabling faster convergence of physics-aware models. Furthermore, while traditional physics-informed methods solve for a single PDE instance, our approach addresses parametric PDEs. Specifically, our method integrates the physical loss gradient with the PDE parameters to solve over a distribution of PDE parameters, including coefficients, initial conditions, or boundary conditions. We demonstrate the effectiveness of our method through empirical experiments on multiple datasets, comparing training and test-time optimization performance.
ToddlerDiffusion: Interactive Structured Image Generation with Cascaded Schrödinger Bridge
Authors: Eslam Abdelrahman Liangbing Zhao Vincent Tao Hu Matthieu Cord Patrick Perez Mohamed Elhoseiny
[Paper] [Code] [Project page]

Diffusion models break down the challenging task of generating data from high-dimensional distributions into a series of easier denoising steps. Inspired by this paradigm, we propose a novel approach that extends the diffusion framework into modality space, decomposing the complex task of RGB image generation into simpler, interpretable stages. Our method, termed ToddlerDiffusion, cascades modality-specific models, each responsible for generating an intermediate representation, such as contours, palettes, and detailed textures, ultimately culminating in a high-quality RGB image. Instead of relying on the naive LDM concatenation conditioning mechanism to connect the different stages together, we employ Schrödinger Bridge to determine the optimal transport between different modalities. Although employing a cascaded pipeline introduces more stages, which could lead to a more complex architecture, each stage is meticulously formulated for efficiency and accuracy, surpassing Stable-Diffusion (LDM) performance. Modality composition not only enhances overall performance but enables emerging proprieties such as consistent editing, interaction capabilities, high-level interpretability, and faster convergence and sampling rate. Extensive experiments on diverse datasets, including LSUN-Churches, ImageNet, CelebHQ, and LAION-Art, demonstrate the efficacy of our approach, consistently outperforming state-of-the-art methods. For instance, ToddlerDiffusion achieves notable efficiency, matching LDM performance on LSUN-Churches while operating 2× faster with a 3× smaller architecture.