LaRa: Latents and Rays for Multi-Camera Bird's-Eye-View Semantic Segmentation
Florent Bartoccioni Éloi Zablocki Andrei Bursuc Patrick Pérez Matthieu Cord Karteek Alahari
CoRL 2022
Abstract
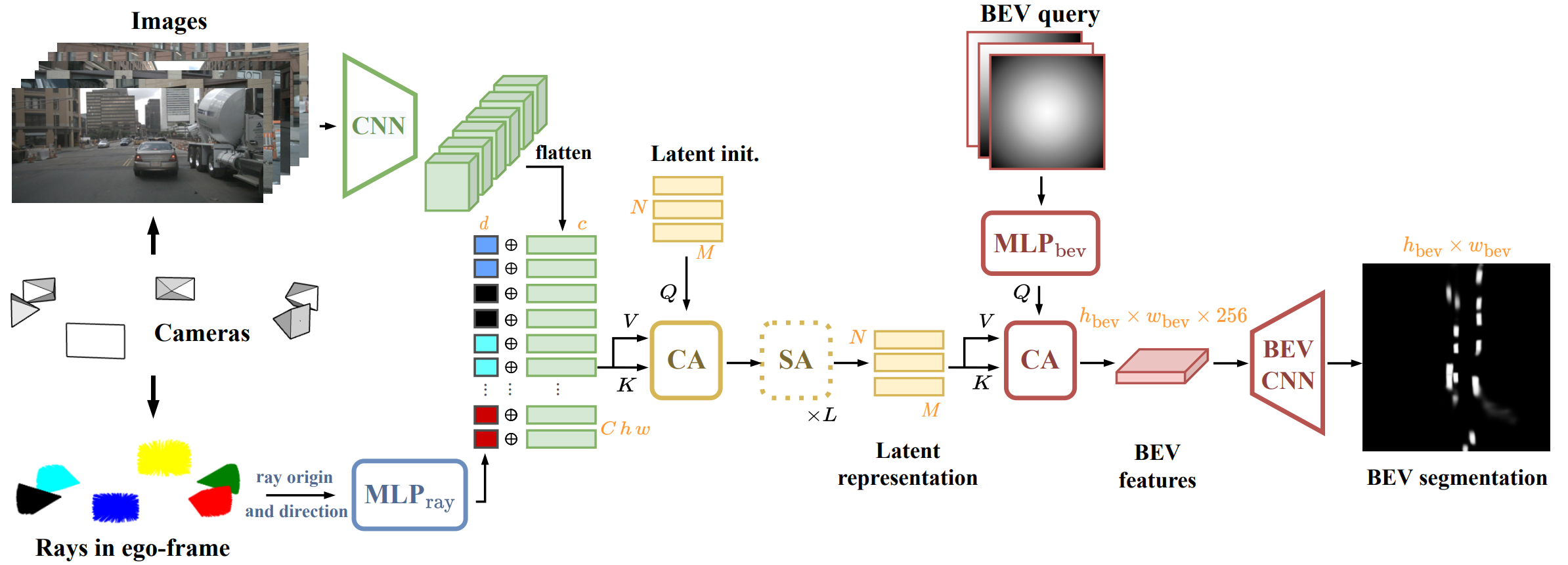
Recent works in autonomous driving have widely adopted the bird's-eye-view (BEV) semantic map as an intermediate representation of the world. Online prediction of these BEV maps involves non-trivial operations such as multi-camera data extraction as well as fusion and projection into a common top-view grid. This is usually done with error-prone geometric operations (e.g., homography or back-projection from monocular depth estimation) or expensive direct dense mapping between image pixels and pixels in BEV (e.g., with MLP or attention). In this work, we present 'LaRa', an efficient encoder-decoder, transformer-based model for vehicle semantic segmentation from multiple cameras. Our approach uses a system of cross-attention to aggregate information over multiple sensors into a compact, yet rich, collection of latent representations. These latent representations, after being processed by a series of self-attention blocks, are then reprojected with a second cross-attention in the BEV space. We demonstrate that our model outperforms on nuScenes the best previous works using transformers.
BibTeX
@inproceedings{lara2022,
author = {Florent Bartoccioni and
{\'{E}}loi Zablocki and
Andrei Bursuc and
Patrick P{\'{e}}rez and
Matthieu Cord and
Karteek Alahari},
title = {LaRa: Latents and Rays for Multi-Camera Bird's-Eye-View Semantic Segmentation},
booktitle = {CoRL},
year = {2022}
}