BEVContrast: Self-Supervision in BEV Space for Automotive Lidar Point Clouds
Corentin Sautier Gilles Puy Alexandre Boulch Renaud Marlet Vincent Lepetit
3DV 2024
Abstract
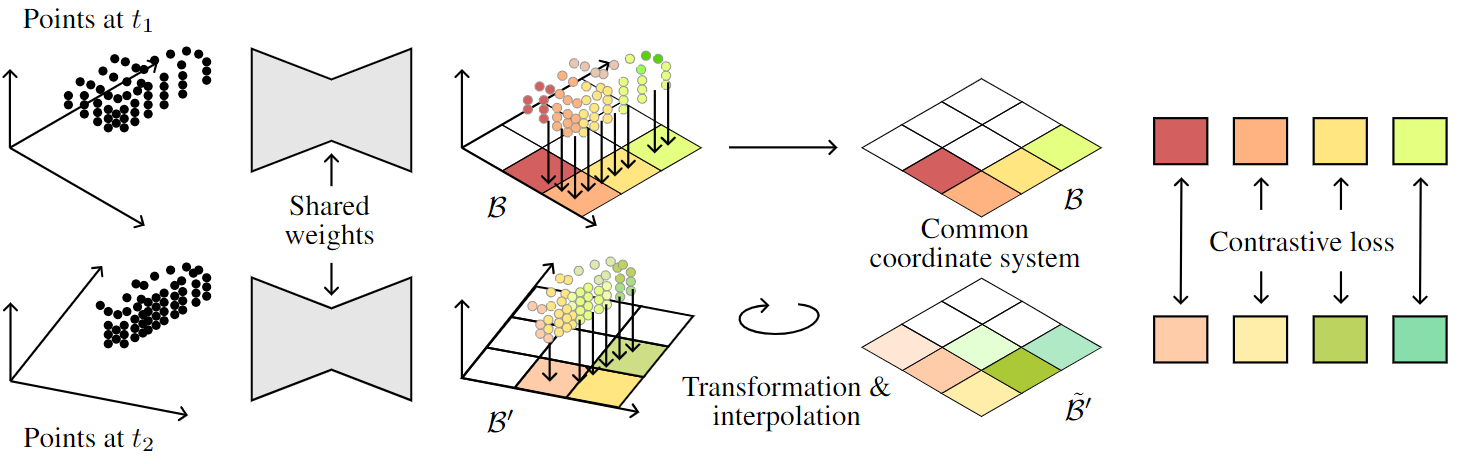
We present a surprisingly simple and efficient method for self-supervision of 3D backbone on automotive Lidar point clouds. We design a contrastive loss between features of Lidar scans captured in the same scene. Several such approaches have been proposed in the literature from PointConstrast, which uses a contrast at the level of points, to the state-of-the-art TARL, which uses a contrast at the level of segments, roughly corresponding to objects. While the former enjoys a great simplicity of implementation, it is surpassed by the latter, which however requires a costly pre-processing. In BEVContrast, we define our contrast at the level of 2D cells in the Bird's Eye View plane. Resulting cell-level representations offer a good trade-off between the point-level representations exploited in PointContrast and segment-level representations exploited in TARL: we retain the simplicity of PointContrast (cell representations are cheap to compute) while surpassing the performance of TARL in downstream semantic segmentation.
BibTeX
@inproceedings{bevcontrast,
title={{BEVContrast}: Self-Supervision in BEV Space for Automotive Lidar Point Clouds},
author={Corentin Sautier and Gilles Puy and Alexandre Boulch and Renaud Marlet and Vincent Lepetit},
booktitle={3DV},
year={2024}
}