xMUDA: Cross-Modal Unsupervised Domain Adaptation for 3D Semantic Segmentation
Maximilian Jaritz Tuan-Hung Vu Raoul de Charette Émilie Wirbel Patrick Pérez
CVPR 2020
Abstract
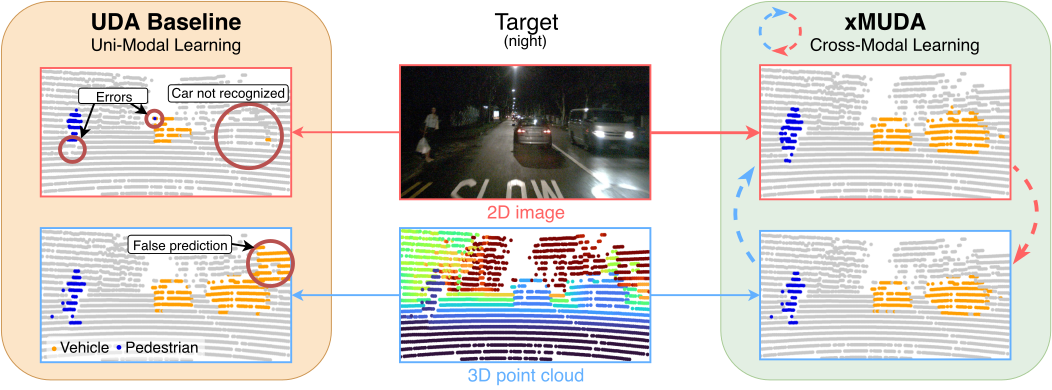
Unsupervised Domain Adaptation (UDA) is crucial to tackle the lack of annotations in a new domain. There are many multi-modal datasets, but most UDA approaches are uni-modal. In this work, we explore how to learn from multi-modality and propose cross-modal UDA (xMUDA) where we assume the presence of 2D images and 3D point clouds for 3D semantic segmentation. This is challenging as the two input spaces are heterogeneous and can be impacted differently by domain shift. In xMUDA, modalities learn from each other through mutual mimicking, disentangled from the segmentation objective, to prevent the stronger modality from adopting false predictions from the weaker one. We evaluate on new UDA scenarios including day-to-night, country-to-country and dataset-to-dataset, leveraging recent autonomous driving datasets. xMUDA brings large improvements over uni-modal UDA on all tested scenarios, and is complementary to state-of-the-art UDA techniques. Code is available at: https://github.com/valeoai/xmuda
Video
BibTeX
@inproceedings{jaritz2020xmuda,
title={xMUDA: Cross-Modal Unsupervised Domain Adaptation for 3D Semantic Segmentation},
author={Jaritz, Maximilian and Vu, Tuan-Hung and Charette, Raoul de and Wirbel, Emilie and P{\'e}rez, Patrick},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={12605--12614},
year={2020}
}