Semantic Palette: Guiding Scene Generation with Class Proportions
Guillaume Le Moing Tuan-Hung Vu Himalaya Jain Patrick Pérez Matthieu Cord
CVPR 2021
Abstract
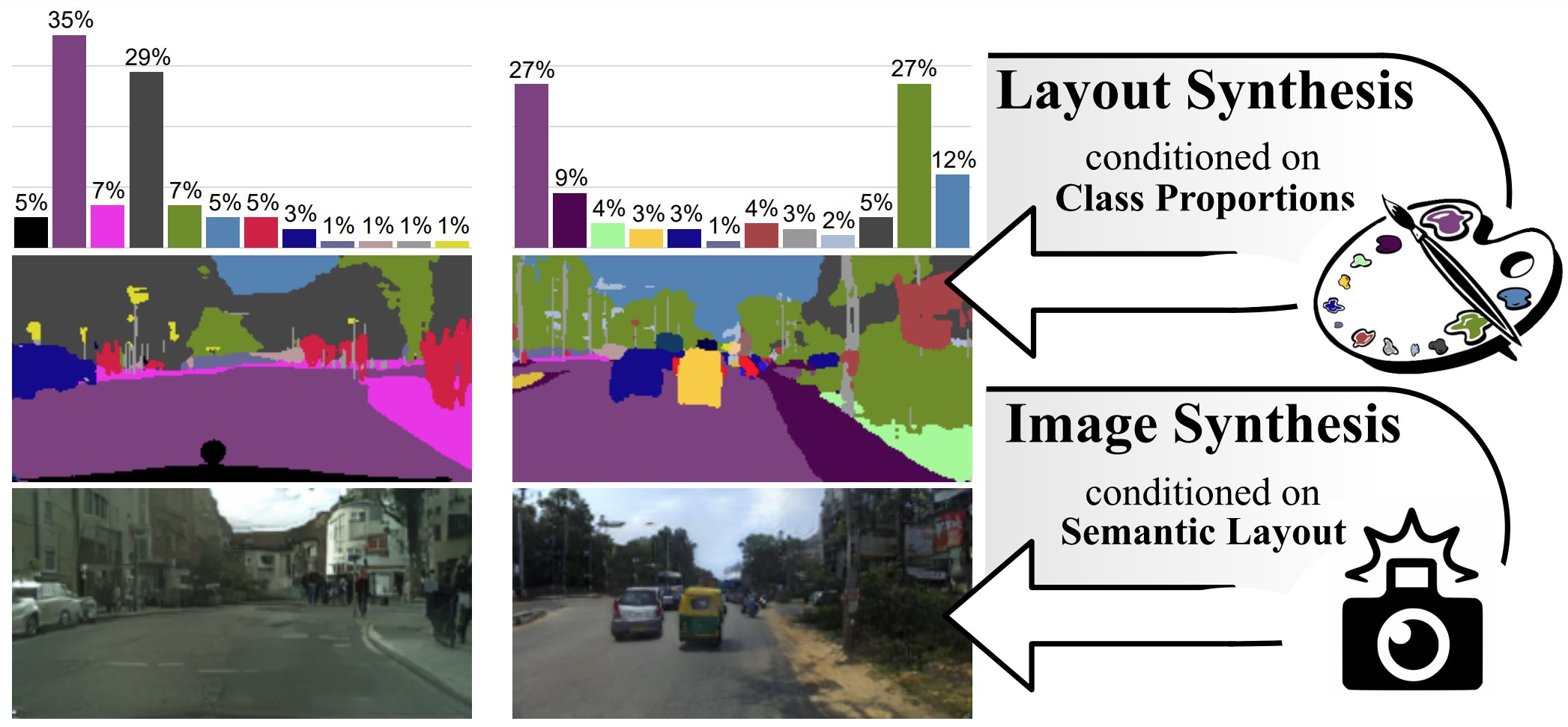
Despite the recent progress of generative adversarial networks (GANs) at synthesizing photo-realistic images, producing complex urban scenes remains a challenging problem. Previous works break down scene generation into two consecutive phases: unconditional semantic layout synthesis and image synthesis conditioned on layouts. In this work, we propose to condition layout generation as well for higher semantic control: given a vector of class proportions, we generate layouts with matching composition. To this end, we introduce a conditional framework with novel architecture designs and learning objectives, which effectively accommodates class proportions to guide the scene generation process. The proposed architecture also allows partial layout editing with interesting applications. Thanks to the semantic control, we can produce layouts close to the real distribution, helping enhance the whole scene generation process. On different metrics and urban scene benchmarks, our models outperform existing baselines. Moreover, we demonstrate the merit of our approach for data augmentation: semantic segmenters trained on real layout-image pairs along with additional ones generated by our approach outperform models only trained on real pairs.
Video
BibTeX
@inproceedings{lemoing2021semanticpalette,
title={Semantic Palette: Guiding Scene Generation with Class Proportions},
author={Le Moing, Guillaume and Vu, Tuan-Hung and Jain, Himalaya and P{\'e}rez, Patrick and Cord, Mathieu},
booktitle={CVPR},
year={2021}
}