CLIP’s Visual Embedding Projector is a Few-shot Cornucopia
Mohammad Fahes Tuan-Hung Vu Andrei Bursuc Patrick Pérez Raoul de Charette
WACV 2026
Abstract
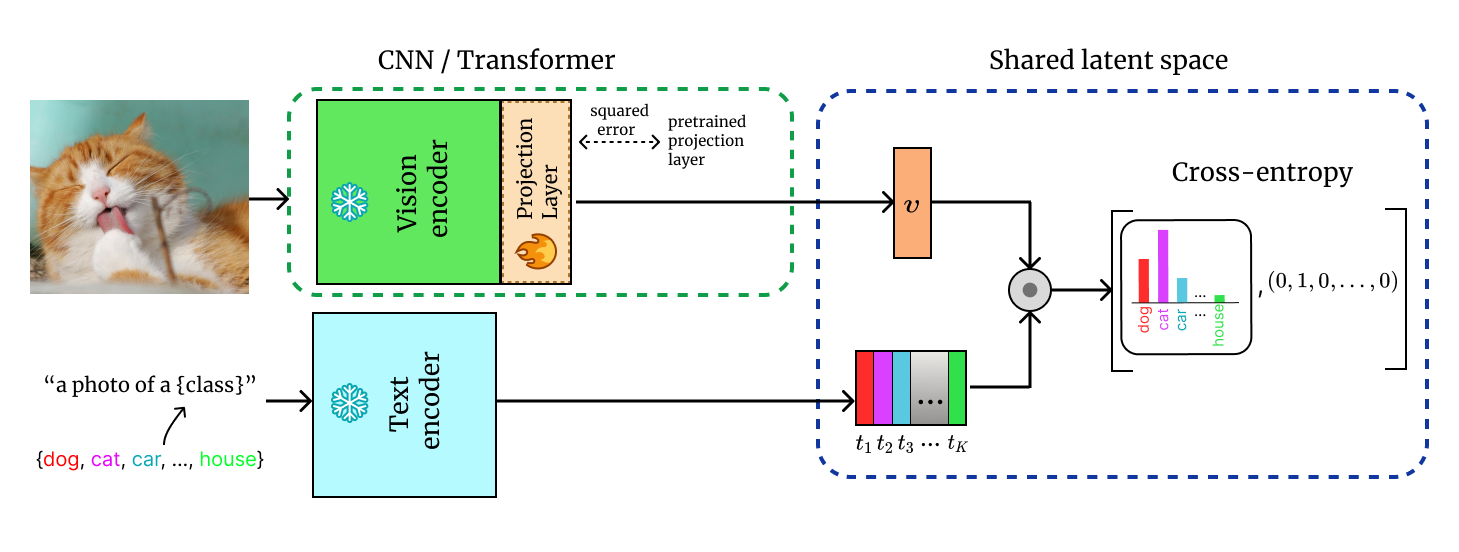
We consider the problem of adapting a contrastively pretrained vision-language model like CLIP (Radford et al., 2021) for few-shot classification. The existing literature addresses this problem by learning a linear classifier of the frozen visual features, optimizing word embeddings, or learning external feature adapters. This paper introduces an alternative way for CLIP adaptation without adding 'external' parameters to optimize. We find that simply fine-tuning the last projection matrix of the vision encoder leads to strong performance compared to the existing baselines. Furthermore, we show that regularizing training with the distance between the fine-tuned and pretrained matrices adds reliability for adapting CLIP through this layer. Perhaps surprisingly, this approach, coined ProLIP, yields performances on par or better than state of the art on 11 few-shot classification benchmarks, few-shot domain generalization, cross-dataset transfer and test-time adaptation.
BibTeX
@inproceedings{fahes2026prolip,
title={CLIP’s Visual Embedding Projector is a Few-shot Cornucopia},
author={Fahes, Mohammad and Vu, Tuan-Hung and Bursuc, Andrei and P{\'e}rez, Patrick and de Charette, Raoul},
booktitle={WACV},
year={2026}
}