POP-3D: Open-Vocabulary 3D Occupancy Prediction from Images
Antonin Vobecky Oriane Siméoni David Hurych Spyros Gidaris
Andrei Bursuc Patrick Pérez Josef Sivic
NeurIPS 2023
Abstract
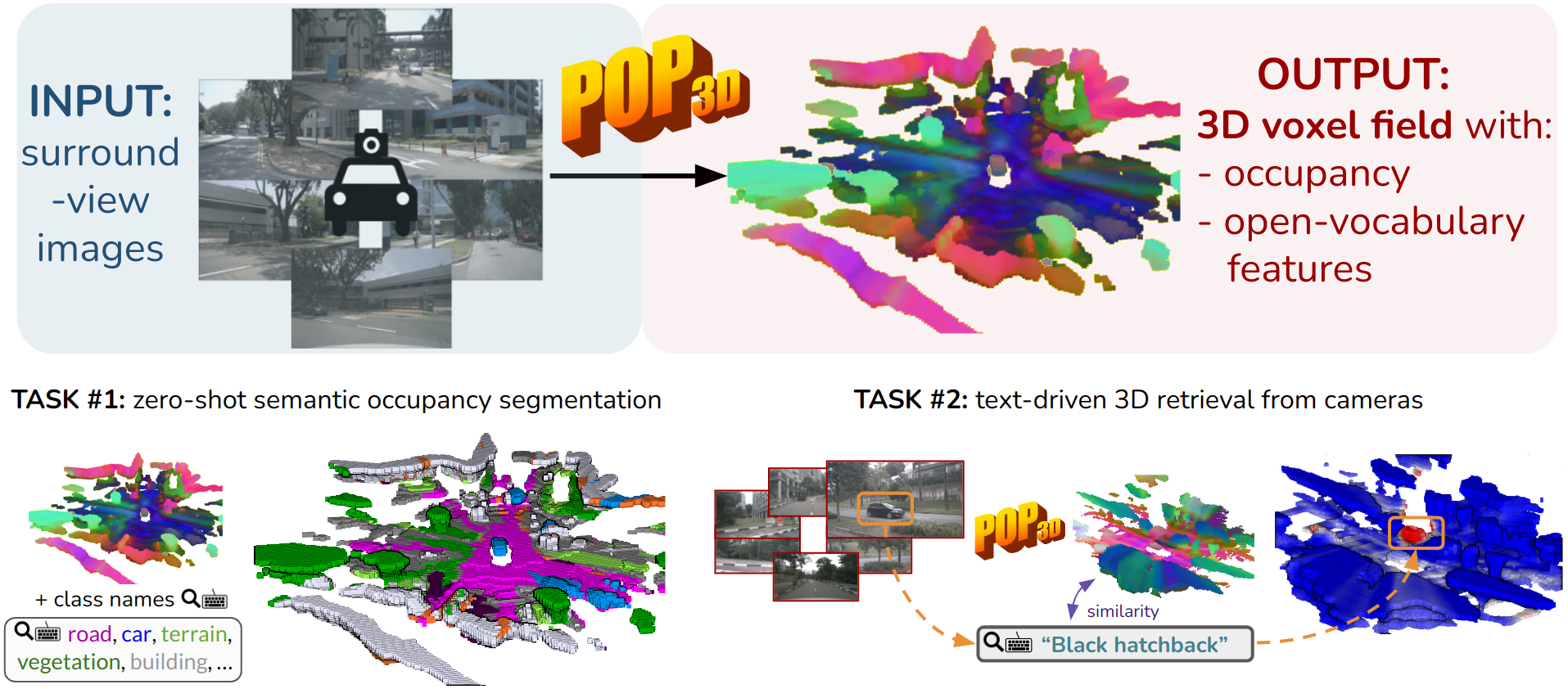
We describe an approach to predict open-vocabulary 3D semantic voxel occupancy map from input 2D images with the objective of enabling 3D grounding, segmentation and retrieval of free-form language queries. This is a challenging problem because of the 2D-3D ambiguity and the open-vocabulary nature of the target tasks, where obtaining annotated training data in 3D is difficult. The contributions of this work are three-fold. First, we design a new model architecture for open-vocabulary 3D semantic occupancy prediction. The architecture consists of a 2D-3D encoder together with occupancy prediction and 3D-language heads. The output is a dense voxel map of 3D grounded language embeddings enabling a range of open-vocabulary tasks. Second, we develop a tri-modal self-supervised learning algorithm that leverages three modalities: (i) images, (ii) language and (iii) LiDAR point clouds, and enables training the proposed architecture using a strong pre-trained vision-language model without the need for any 3D manual language annotations. Finally, we demonstrate quantitatively the strengths of the proposed model on several open-vocabulary tasks: Zero-shot 3D semantic segmentation using existing datasets; 3D grounding and retrieval of free-form language queries, using a small dataset that we propose as an extension of nuScenes.
BibTeX
@inproceedings{vobecky2023pop,
title={Pop-3d: Open-vocabulary 3d occupancy prediction from images},
author={Vobecky, Antonin and Sim{\'e}oni, Oriane and Hurych, David and Gidaris, Spyridon and Bursuc, Andrei and P{\'e}rez, Patrick and Sivic, Josef},
booktitle={NeurIPS},
year={2023}
}