MOCA: Self-supervised Representation Learning by Predicting Masked Online Codebook Assignments
TMLR 2024 and ICLR 2025
Abstract
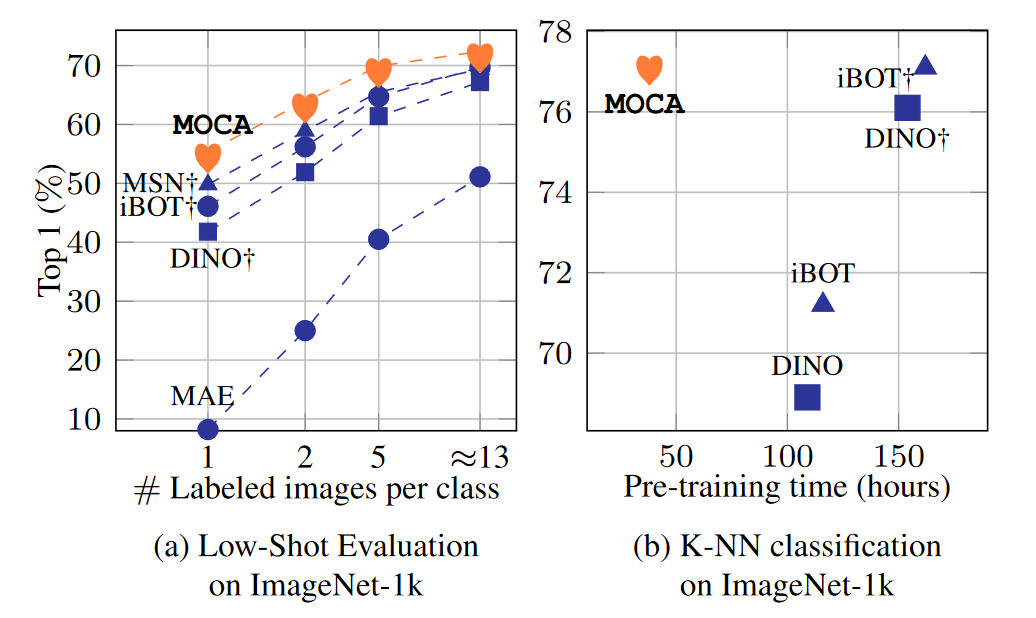
Self-supervised learning can be used for mitigating the greedy needs of Vision Transformer networks for very large fully-annotated datasets. Different classes of self-supervised learning offer representations with either good contextual reasoning properties, e.g., using masked image modeling strategies, or invariance to image perturbations, e.g., with contrastive methods. In this work, we propose a single-stage and standalone method, MOCA, which unifies both desired properties using novel mask-and-predict objectives defined with high-level features (instead of pixel-level details). Moreover, we show how to effectively employ both learning paradigms in a synergistic and computation-efficient way. Doing so, we achieve new state-of-the-art results on low-shot settings and strong experimental results in various evaluation protocols with a training that is at least 3 times faster than prior methods.
BibTeX
@inproceedings{gidaris2024moca,
title={MOCA: Self-supervised Representation Learning by Predicting Masked Online Codebook Assignments},
author={Gidaris, Spyros and Bursuc, Andrei and Simeoni, Oriane and Vobecky, Antonin and Komodakis, Nikos and Cord, Matthieu and P{\'e}rez, Patrick},
booktitle={TMLR},
year={2024}
}