JAFAR: Jack up Any Feature at Any Resolution
Paul Couairon* Loick Chambon* Louis Serrano Jean-Emmanuel Haugeard Matthieu Cord Nicolas Thome
*Equal Contribution
NeurIPS 2025
Abstract
Foundation Vision Encoders have become essential for a wide range of dense vision tasks. However, their low-resolution spatial feature outputs necessitate feature upsampling to produce the high-resolution modalities required for downstream tasks. In this work, we introduce JAFAR—a lightweight and flexible feature upsampler that enhances the spatial resolution of visual features from any Foundation Vision Encoder to an arbitrary target resolution. JAFAR employs an attention-based module designed to promote semantic alignment between high-resolution queries—derived from low-level image features—and semantically enriched low-resolution keys, using Spatial Feature Transform (SFT) modulation. Notably, despite the absence of high-resolution supervision, we demonstrate that learning at low upsampling ratios and resolutions generalizes remarkably well to significantly higher output scales. Extensive experiments show that JAFAR effectively recovers fine-grained spatial details and consistently outperforms existing feature upsampling methods across a diverse set of downstream tasks.
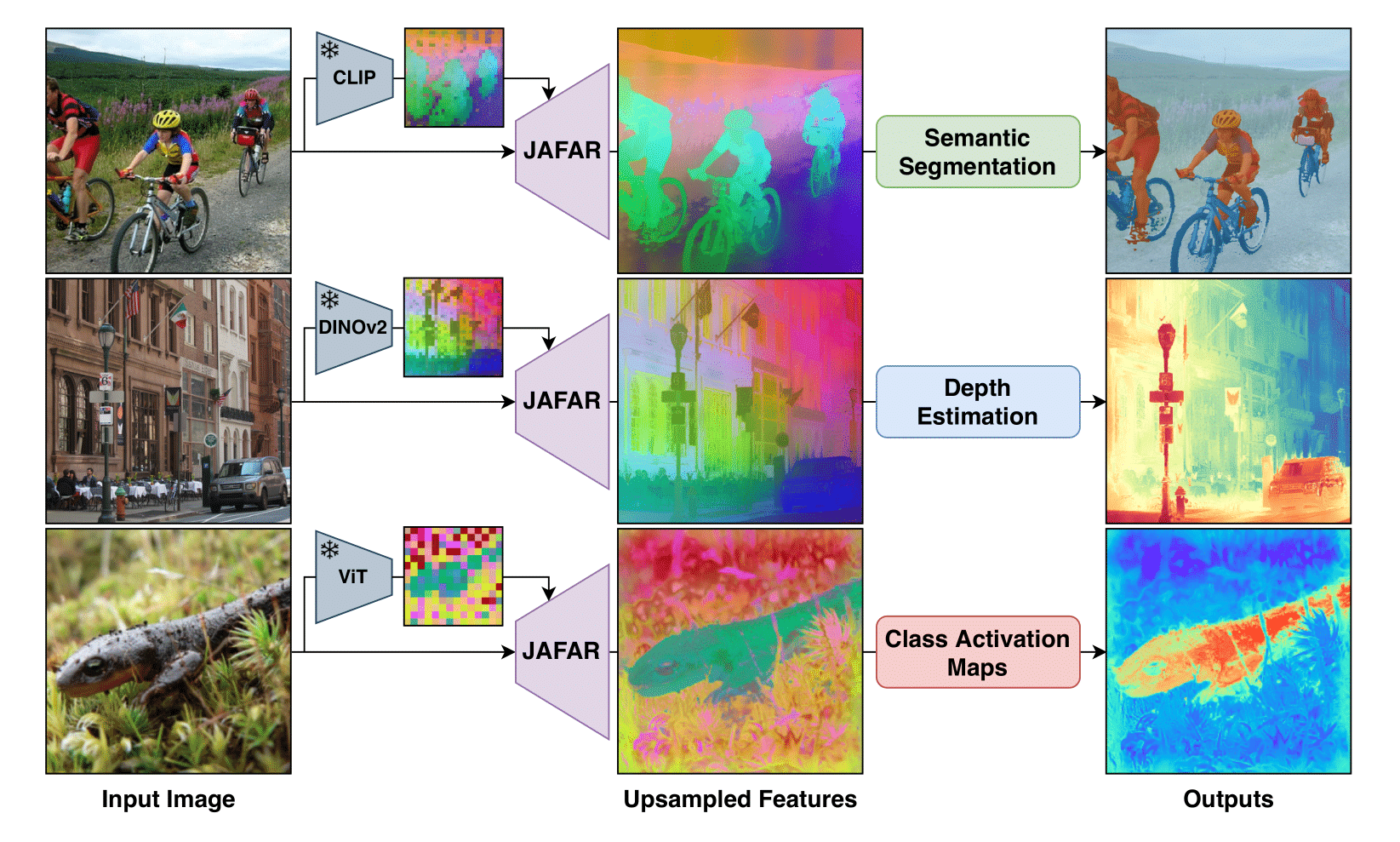
Results
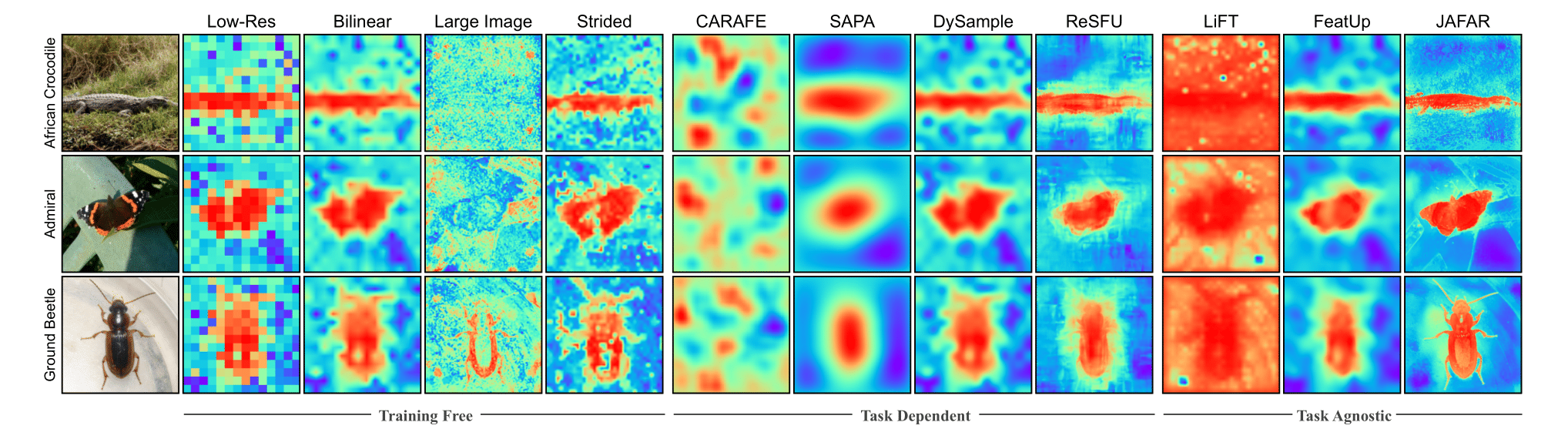
Once trained, JAFAR can efficiently upsample any backbone features to any resolution. Visually the features are sharper and more detailed than the original features leading to better performance on downstream tasks.
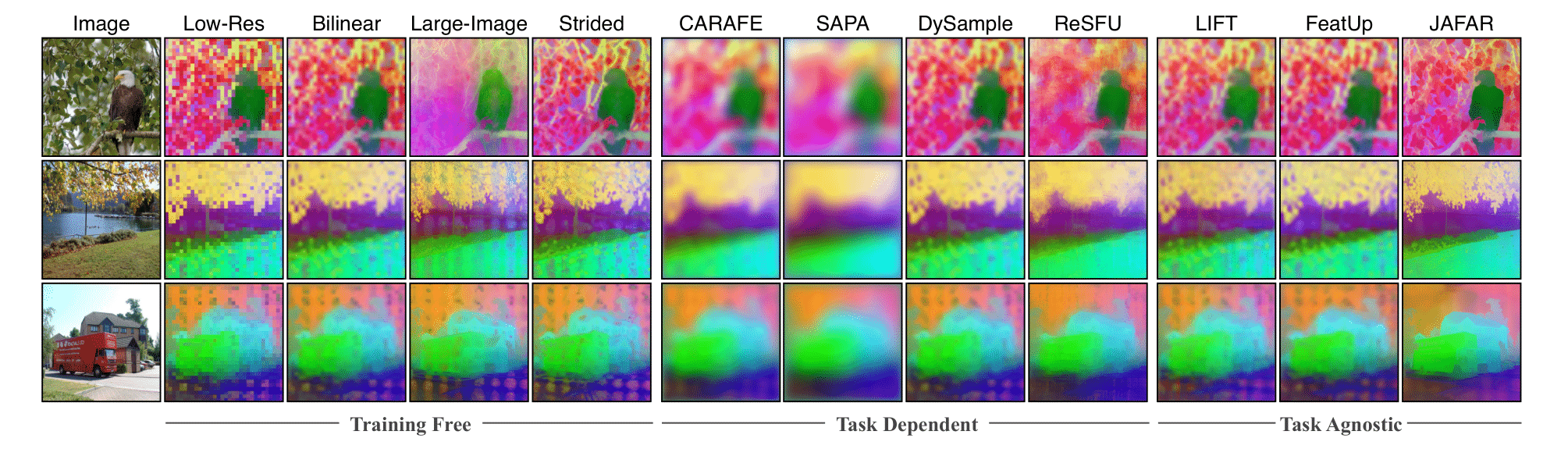
Below we present results on various tasks, comparing JAFAR with other upsamplers such as Bilinear, FeatUp, and LiFT. More comparisons can be found in the paper.
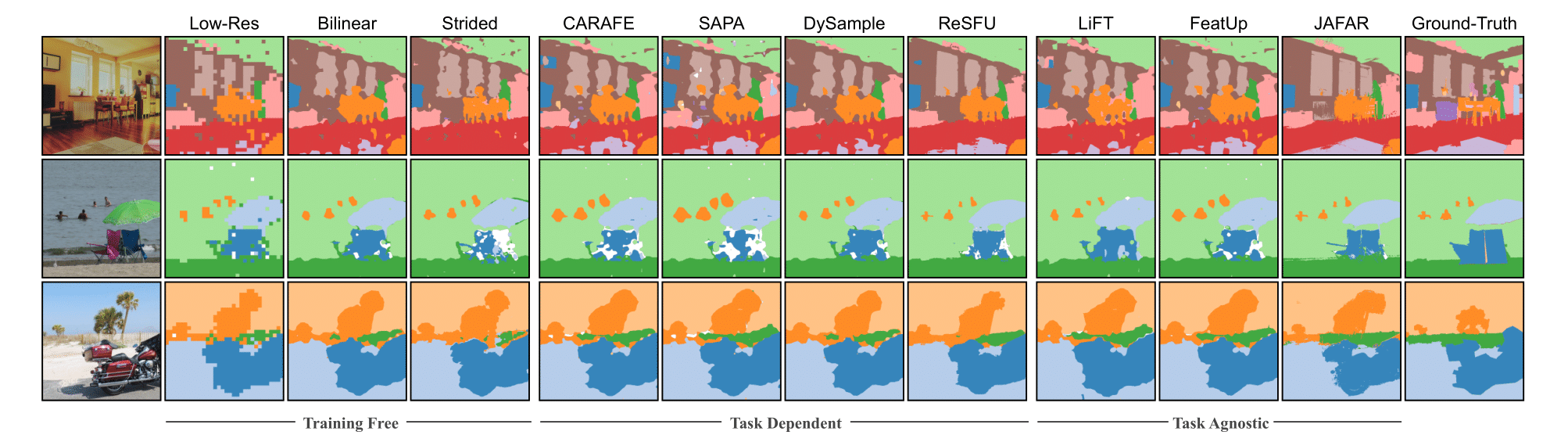
Semantic Segmentation
We perform a linear probing on upsampled features from various upsamplers on many datasets: VOC, COCO, ADE20k, and Cityscapes. The results show that JAFAR consistently outperforms other methods across all datasets.
| Method | COCO mIoU (↑) | VOC mIoU (↑) | ADE20k mIoU (↑) | Cityscapes mIoU (↑) |
|---|---|---|---|---|
| Training-Free | ||||
| Bilinear | 59.03 | 80.70 | 39.23 | 59.37 |
| Task-Agnostic | ||||
| FeatUp | 60.10 | 81.08 | 38.82 | 56.06 |
| LiFT | 58.18 | 78.06 | 38.73 | 58.75 |
| JAFAR (ours) | 60.78 (+1.75) | 84.44 (+3.74) | 40.49 (+1.26) | 61.47 (+2.10) |
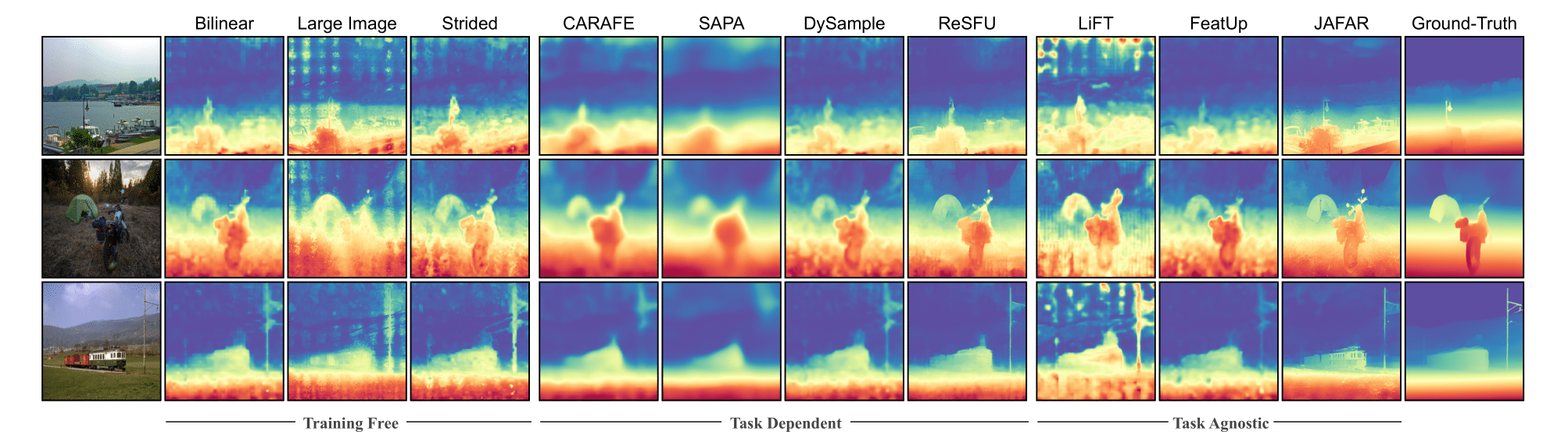
Depth Estimation
For depth estimation, we evaluate the upsampled features using δ₁ and RMSE metrics. JAFAR again shows superior performance compared to other methods.
| Method | δ₁ (↑) | RMSE (↓) |
|---|---|---|
| Training-Free | ||
| Bilinear | 59.92 | 0.66 |
| Task-Agnostic | ||
| FeatUp | 61.69 | 0.64 |
| LiFT | 57.04 | 0.70 |
| JAFAR (ours) | 62.18 (+2.26) | 0.62 (-0.04) |
Class Activation Maps
When evaluating Class Activation Maps (CAMs), JAFAR demonstrates improved alignment and granularity in the visualizations, indicating better feature representation.
| Method | A.D (↓) | A.I (↑) | A.G (↑) | ADCC (↑) |
|---|---|---|---|---|
| Training-Free | ||||
| Bilinear | 19.0 | 18.5 | 3.4 | 61.7 |
| Task-Agnostic | ||||
| FeatUp | 15.3 | 24.0 | 4.3 | 64.3 |
| LiFT | 66.9 | 8.7 | 2.3 | 53.0 |
| JAFAR (ours) | 17.4 (-1.6) | 30.9 (+12.4) | 6.5 (+3.1) | 73.3 (+11.6) |
Vehicle Segmentation
Even on more complicated tasks and pipelines, JAFAR shows significant improvements.

| Upsampling | SimpleBeV mIoU (↑) | PointBeV mIoU (↑) | BeVFormer mIoU (↑) |
|---|---|---|---|
| Training-Free | |||
| Low-Res | 31.75 | 34.89 | 33.72 |
| Bilinear | 33.67 | 36.01 | 34.18 |
| Task-Agnostic | |||
| FeatUp | 33.95 | 35.38 | 34.01 |
| JAFAR (ours) | 36.59 (+2.92) | 37.20 (+1.19) | 36.54 (+2.36) |
Zero-shot Open Vocabulary
We also clearly see improvements in zero-shot open vocabulary tasks.
| Upsampling | VOC mIoU (↑) | ADE mIoU (↑) | City mIoU (↑) |
|---|---|---|---|
| Training-Free | |||
| Bilinear | 27.87 | 11.03 | 21.56 |
| Task-Agnostic | |||
| FeatUp | 32.27 | 13.03 | 24.76 |
| JAFAR (ours) | 35.70 (+7.83) | 13.61 (+2.58) | 25.26 (+3.70) |
BibTeX
@inproceedings{couairon2025jafar,
title={JAFAR: Jack up Any Feature at Any Resolution},
author={Paul Couairon and Loick Chambon and Louis Serrano and Jean-Emmanuel Haugeard and Matthieu Cord and Nicolas Thome},
year={2025},
url={https://jafar-upsampler.github.io},
booktitle={NeurIPS},
}