GIFT: A Framework for Global Interpretable Faithful Textual Explanations of Vision Classifiers
TMLR 2026
Abstract
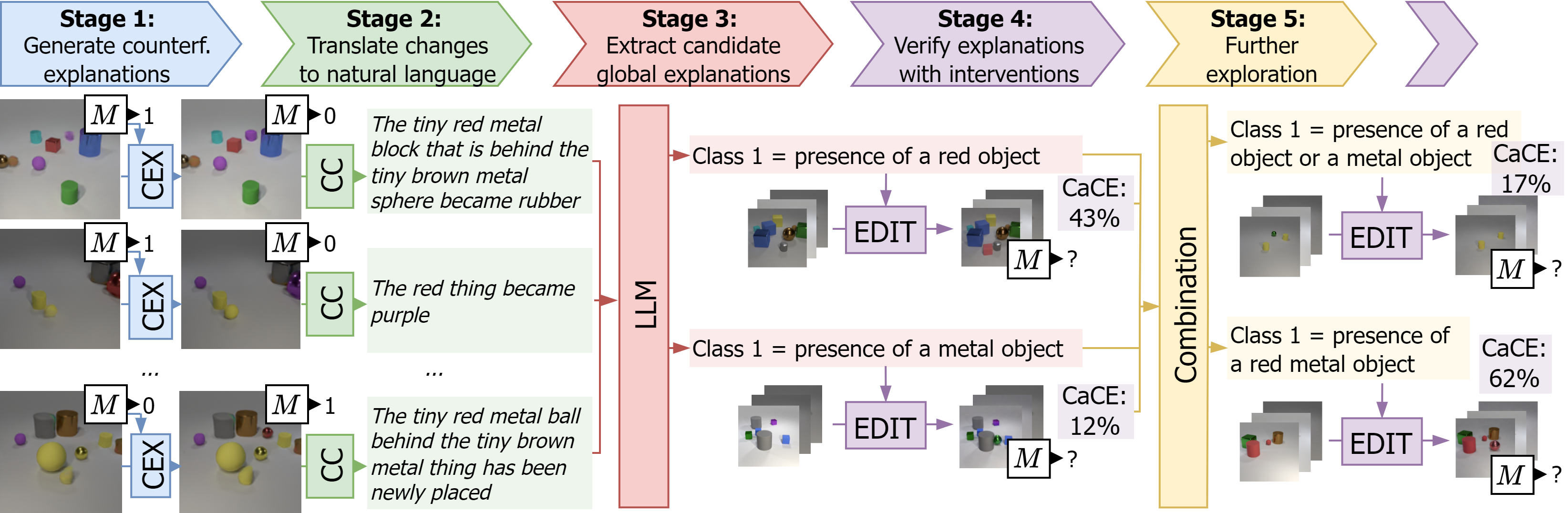
Understanding deep models is crucial for deploying them in safety-critical applications. We introduce GIFT, a framework for deriving post-hoc, global, interpretable, and faithful textual explanations for vision classifiers. GIFT starts from local faithful visual counterfactual explanations and employs (vision) language models to translate those into global textual explanations. Crucially, GIFT provides a verification stage measuring the causal effect of the proposed explanations on the classifier decision. Through experiments across diverse datasets, including CLEVR, CelebA, and BDD, we demonstrate that GIFT effectively reveals meaningful insights, uncovering tasks, concepts, and biases used by deep vision classifiers. Our code, data, and models are released at https://github.com/valeoai/GIFT.
BibTeX
@inproceedings{zablocki2026gift,
title = {GIFT: A Framework for Global Interpretable Faithful Textual Explanations of Vision Classifiers},
author = {Eloi Zablocki and
Valentin Gerard and
Amaia Cardiel and
Eric Gaussier and
Matthieu Cord and
Eduardo Valle},
journal = {TMLR},
year = {2026}
}