Advancing Semantic Future Prediction through Multimodal Visual Sequence Transformers
Efstathios Karypidis Ioannis Kakogeorgiou Spyros Gidaris Nikos Komodakis
CVPR 2025
Abstract
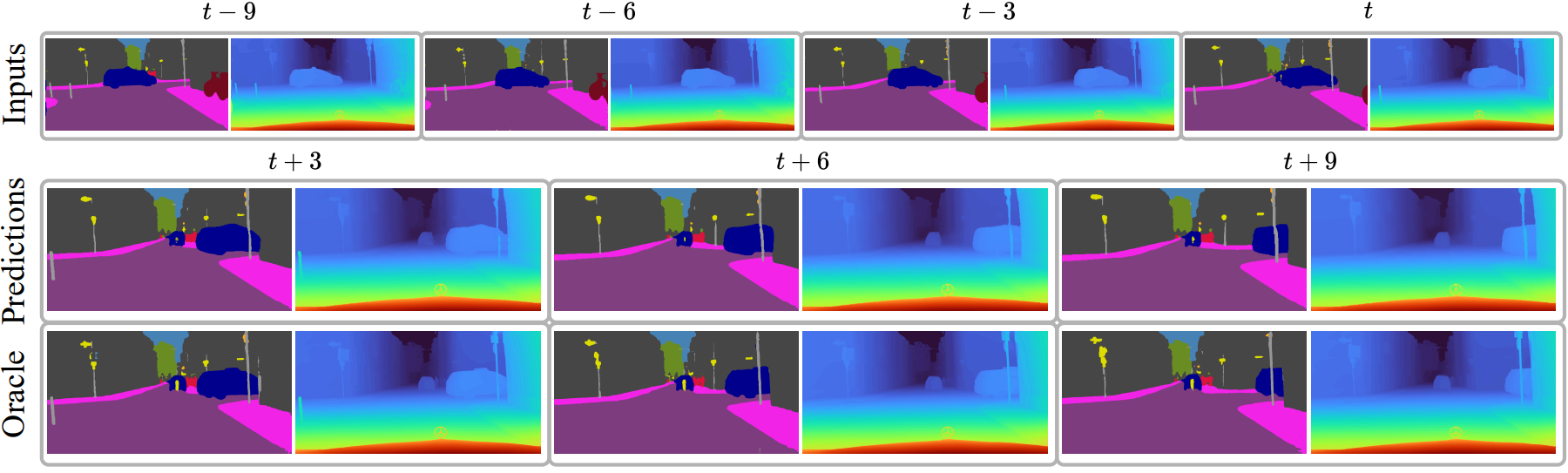
Semantic future prediction is important for autonomous systems navigating dynamic environments. This paper introduces FUTURIST, a method for multimodal future semantic prediction that uses a unified and efficient visual sequence transformer architecture. Our approach incorporates a multimodal masked visual modeling objective and a novel masking mechanism designed for multimodal training. This allows the model to effectively integrate visible information from various modalities, improving prediction accuracy. Additionally, we propose a VAE-free hierarchical tokenization process, which reduces computational complexity, streamlines the training pipeline, and enables end-to-end training with high-resolution, multimodal inputs. We validate FUTURIST on the Cityscapes dataset, demonstrating state-of-the-art performance in future semantic segmentation for both short- and mid-term forecasting.
BibTeX
@inproceedings{karypidis2025advancing,
title={Advancing Semantic Future Prediction through Multimodal Visual Sequence Transformers},
author={Karypidis, Efstathios and Kakogeorgiou, Ioannis and Gidaris, Spyros and Komodakis, Nikos},
booktitle={CVPR},
year={2025}
}