A Simple Recipe for Language-guided Domain Generalized Segmentation
Mohammad Fahes Tuan-Hung Vu Andrei Bursuc Patrick Pérez Raoul de Charette
CVPR 2024
Abstract
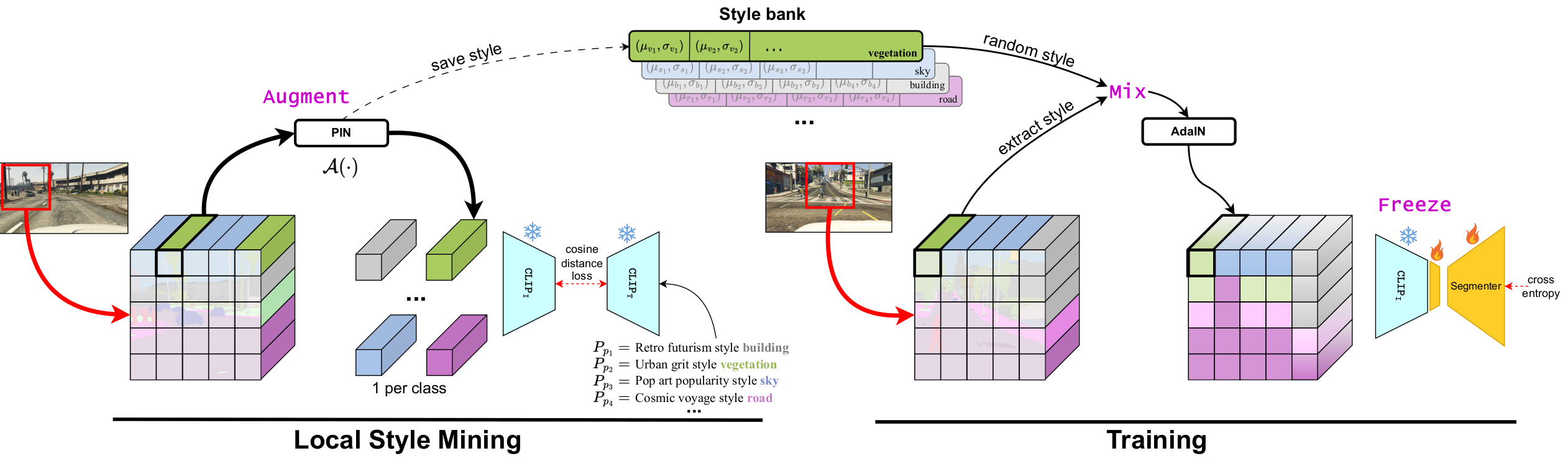
Generalization to new domains not seen during training is one of the long-standing goals and challenges in deploying neural networks in real-world applications. Existing generalization techniques necessitate substantial data augmentation, potentially sourced from external datasets, and aim at learning invariant representations by imposing various alignment constraints. Large-scale pretraining has recently shown promising generalization capabilities, along with the potential of bridging different modalities. For instance, the recent advent of vision-language models like CLIP has opened the doorway for vision models to exploit the textual modality. In this paper, we introduce a simple framework for generalizing semantic segmentation networks by employing language as the source of randomization. Our recipe comprises three key ingredients: i) the preservation of the intrinsic CLIP robustness through minimal fine-tuning, ii) language-driven local style augmentation, and iii) randomization by locally mixing the source and augmented styles during training. Extensive experiments report state-of-the-art results on various generalization benchmarks.
BibTeX
@inproceedings{fahes2024simple,
title={A Simple Recipe for Language-guided Domain Generalized Segmentation},
author={Fahes, Mohammad and Vu, Tuan-Hung and Bursuc, Andrei and P{\'e}rez, Patrick and de Charette, Raoul},
booktitle={CVPR},
year={2024}
}