DiffHPE: Robust, Coherent 3D Human Pose Lifting with Diffusion
Cédric Rommel Eduardo Valle Mickaël Chen Souhaiel Khalfaoui Renaud Marlet Matthieu Cord Patrick Pérez
ICCV 2023
Abstract
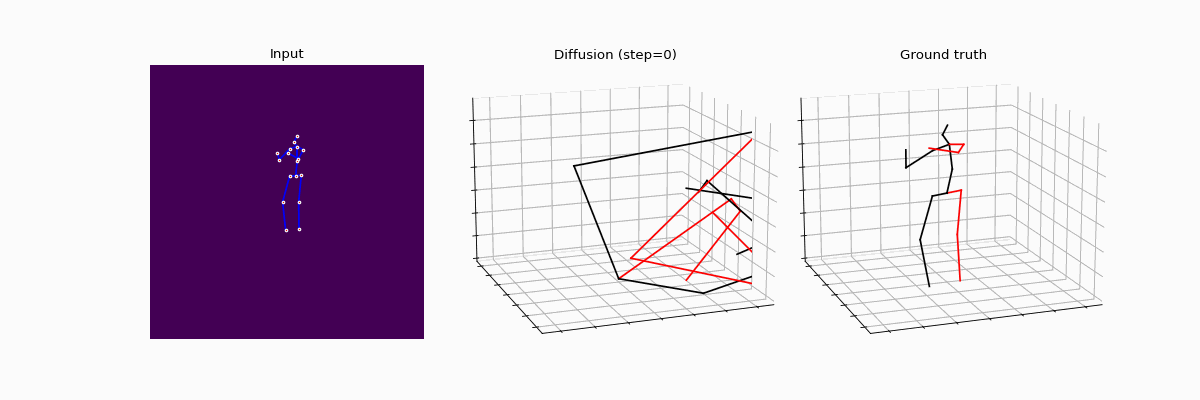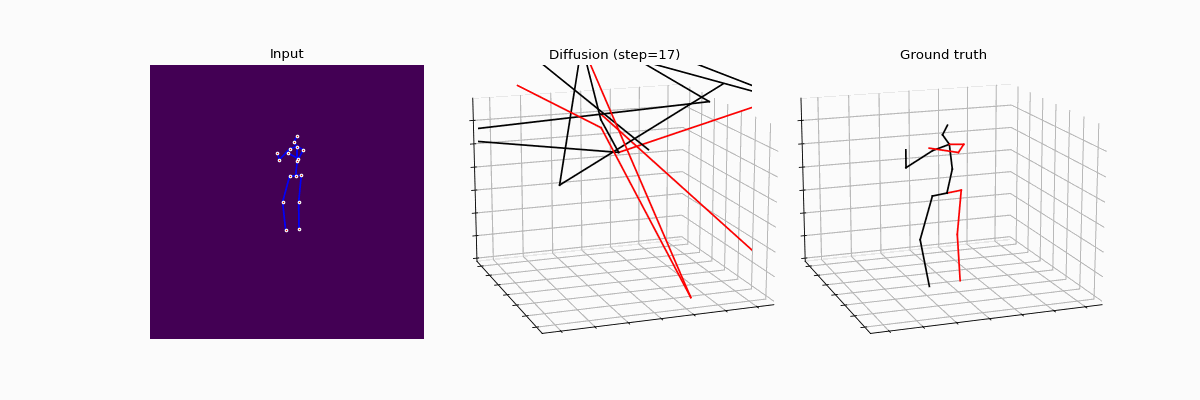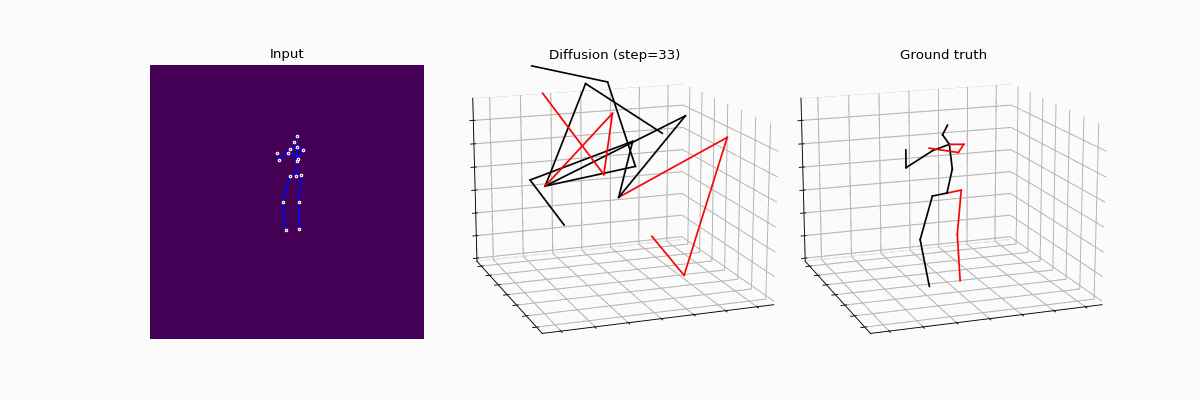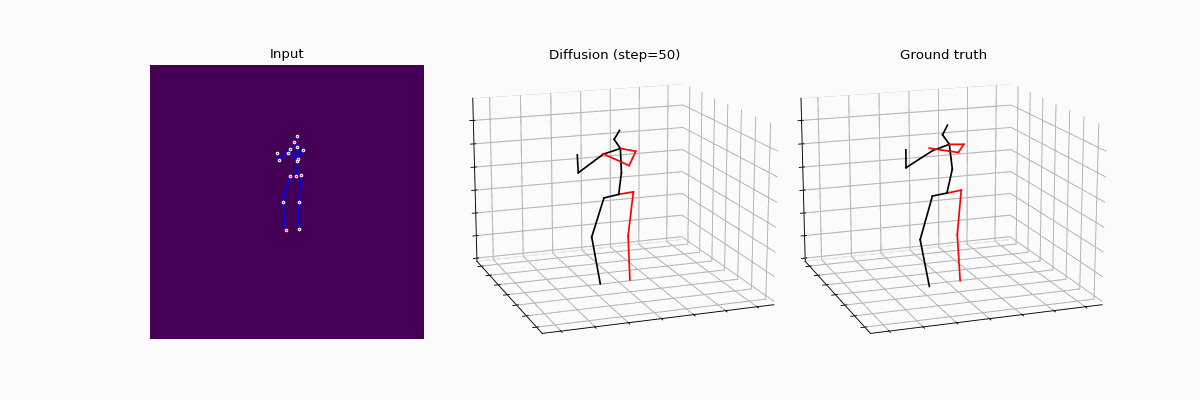
We present an innovative approach to 3D Human Pose Estimation (3D-HPE) by integrating cutting-edge diffusion models, which have revolutionized diverse fields, but are relatively unexplored in 3D-HPE. We show that diffusion models enhance the accuracy, robustness, and coherence of human pose estimations. We introduce DiffHPE, a novel strategy for harnessing diffusion models in 3D-HPE, and demonstrate its ability to refine standard supervised 3D-HPE. We also show how diffusion models lead to more robust estimations in the face of occlusions, and improve the time-coherence and the sagittal symmetry of predictions. Using the Human3.6M dataset, we illustrate the effectiveness of our approach and its superiority over existing models, even under adverse situations where the occlusion patterns in training do not match those in inference. Our findings indicate that while standalone diffusion models provide commendable performance, their accuracy is even better in combination with supervised models, opening exciting new avenues for 3D-HPE research.
BibTeX
@INPROCEEDINGS{rommel2023diffhpe,
title={DiffHPE: Robust, Coherent 3D Human Pose Lifting with Diffusion},
author={Rommel, C{\'e}dric and Valle, Eduardo and Chen, Micka{\"e}l and Khalfaoui, Souhaiel and Marlet, Renaud and Cord, Matthieu and P{\'e}rez, Patrick},
booktitle={International Conference on Computer Vision Workshops (ICCVW)},
year = {2023}
}