The BRAVO Semantic Segmentation Challenge Results in UNCV2024
Tuan-Hung Vu Eduardo Valle Andrei Bursuc Tommie Kerssies Daan de Geus Gijs Dubbelman Long Qian Bingke Zhu Yingying Chen Ming Tang Jinqiao Wang Tomáš Vojíř Jan Šochman Jiří Matas Michael Smith Frank Ferrie Shamik Basu Christos Sakaridis Luc Van Gool
ECCV 2024
Abstract
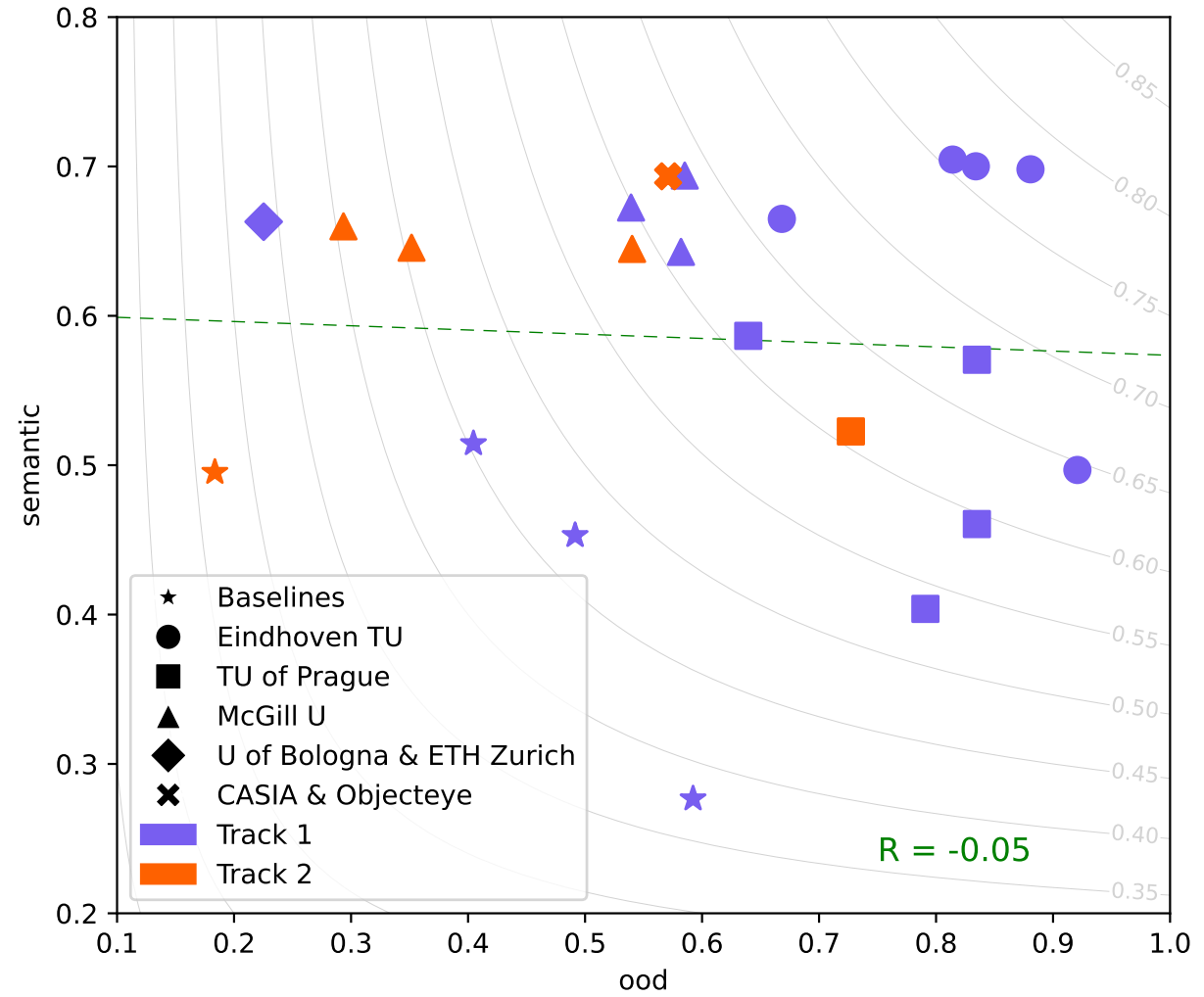
We propose the unified BRAVO challenge to benchmark the reliability of semantic segmentation models under realistic perturbations and unknown out-of-distribution (OOD) scenarios. We define two categories of reliability: (1) semantic reliability, which reflects the model's accuracy and calibration when exposed to various perturbations; and (2) OOD reliability, which measures the model's ability to detect object classes that are unknown during training. The challenge attracted nearly 100 submissions from international teams representing notable research institutions. The results reveal interesting insights into the importance of large-scale pre-training and minimal architectural design in developing robust and reliable semantic segmentation models.
BibTeX
@inproceedings{vu2024bravo,
title={The BRAVO Semantic Segmentation Challenge Results in UNCV2024},
author={Vu, Tuan-Hung and Valle, Eduardo and Bursuc, Andrei and Kerssies, Tommie and de Geus, Daan and Dubbelman, Gijs and Qian, Long and Zhu, Bingke and Chen, Yingying and Tang, Ming and Wang, Jinqiao and Vojíř, Tomáš and Šochman, Jan and Matas, Jiří and Smith, Michael and Ferrie, Frank and Basu, Shamik and Sakaridis, Christos and Van Gool, Luc},
booktitle={ECCV},
year={2024}
}