What to Hide from Your Students: Attention-Guided Masked Image Modeling
Ioannis Kakogeorgiou Spyros Gidaris Bill Psomas Yannis Avrithis Andrei Bursuc Konstantinos Karantzalos Nikos Komodakis
ECCV 2022
Abstract
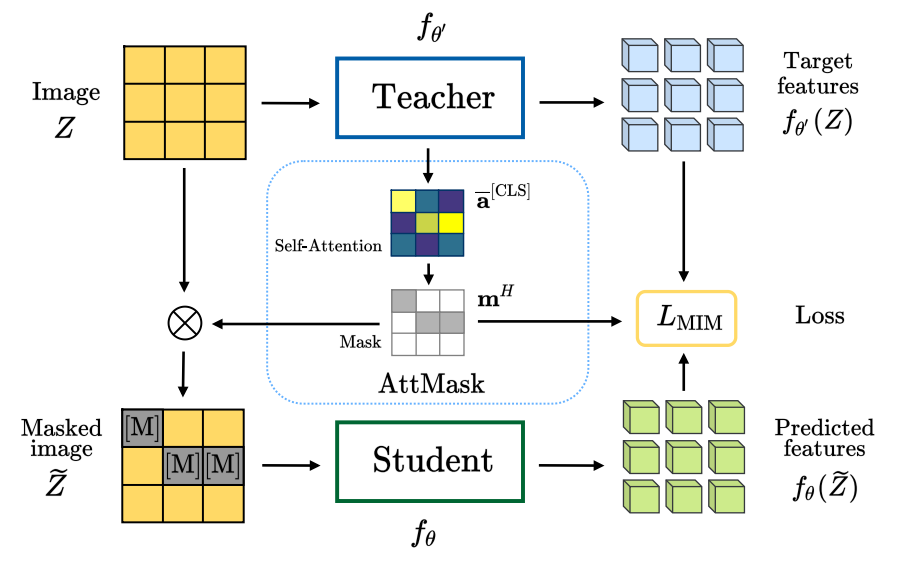
Transformers and masked language modeling are quickly being adopted and explored in computer vision as vision transformers and masked image modeling (MIM). In this work, we argue that image token masking differs from token masking in text, due to the amount and correlation of tokens in an image. In particular, to generate a challenging pretext task for MIM, we advocate a shift from random masking to informed masking. We develop and exhibit this idea in the context of distillation-based MIM, where a teacher transformer encoder generates an attention map, which we use to guide masking for the student. We thus introduce a novel masking strategy, called attention-guided masking (AttMask), and we demonstrate its effectiveness over random masking for dense distillation-based MIM as well as plain distillation-based self-supervised learning on classification tokens. We confirm that AttMask accelerates the learning process and improves the performance on a variety of downstream tasks.
BibTeX
@inproceedings{kakogeorgiou2022hide,
title={What to Hide from Your Students: Attention-Guided Masked Image Modeling},
author={Kakogeorgiou, Ioannis and Gidaris, Spyros and Psomas, Bill and Avrithis, Yannis and Bursuc, Andrei and Karantzalos, Konstantinos and Komodakis, Nikos},
booktitle={ECCV},
year={2022}
}