PLOP: Probabilistic poLynomial Objects trajectory Prediction for autonomous driving
This post describes our recent work on probabilistic trajectory prediction for autonomous driving presented at CORL 2020. PLOP is a trajectory prediction method that intent to control an autonomous vehicle (ego vehicle) in urban environment while considering and predicting the intents of other road users (neighbors). We focus here on predicting multiple feasible future trajectories for both ego vehicle and neighbors through a probabilistic framework and rely on a conditional imitation learning algorithm, conditioned by a navigation command for the ego vehicle (e.g., ``turn right’’). Our model processes only onboard sensor data (camera and lidars) along with detections of past and presents objects relaxing the necessity of an HDMap and is computationally efficient as it can run in real time (25 fps) on an embedded board in the real vehicle. We evaluate our method offline on the publicly available dataset nuScenes (Caesar et al., 2020), achieving state-of-the-art performance, investigate the impact of our architecture choices on online simulated experiments and show preliminary insights for real vehicle control.
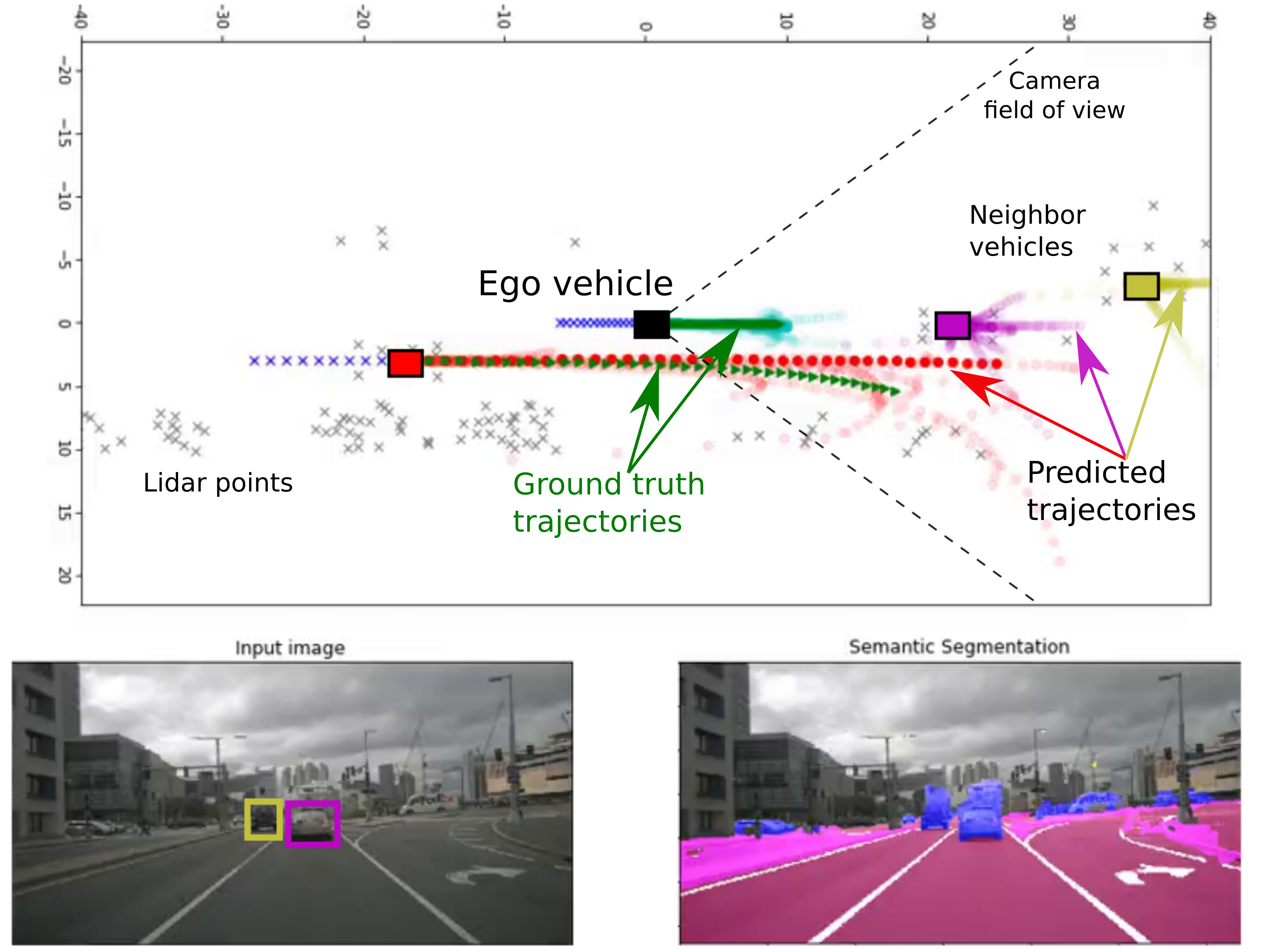
Predicting the future positions of other agents of the road, or of the autonomous vehicle itself, is critical for autonomous driving. This trajectory prediction must not only respect the rules of the road, but capture the interactions of the agents over time. It is also important to allow multiple possible predictions, as there is usually not a single valid trajectory.
Some approaches such as ChauffeurNet (Bansal et al., 2018) use a high-levelscene representation (road map, traffic lights, speed limit, route, dynamic bounding boxes, etc.). More recently, MultiPath (Chai et al., 2019) uses trajectory anchors, used in one-step object detection, extracted from the training data for ego vehicle prediction. (Hong et al., 2019) use a high level representation which includes some dynamic context. In contrast, we choose to leverage also low level sensor data, here Lidar point clouds and camera image. In that domain, recent approaches address the variation in agent behaviors by predicting multiple trajectories, often in a stochastic way. Many works, e.g., PRECOG (Rhinehart et al., 2019), MFP (Tang & Salakhutdinov, 2019), SocialGAN (Gupta et al., 2018) and others (Rhinehart et al., 2018), focus on this aspect through a probabilistic framework on the network output or latent representations, producing multiple trajectories for ego vehicle, nearby vehicles or both. (Phan-Minh et al., 2020) generate a trajectory set, then classify correct trajectories. (Marchetti et al., 2020) generate multiple futures from encodings of similar trajectories stored in a memory. (Ohn-Bar et al., 2020) learn a weighted mixture of expert policies trained to mimic agents with specific behaviors. In PRECOG, (Rhinehart et al., 2019) advance a probabilistic formulation that explicitly models interactions between agents, using latent variables to model their plausible reactions, with the possibility to precondition the trajectory of the ego vehicle by a goal.
PLOP method
Contributions
Our main goal is to produce a trajectory prediction which can be used to drive the ego vehicle relying on a conditional imitation learning algorithm, conditioned by a navigation command for the ego vehicle (e.g., “turn right”). To do so, we propose a single-shot, anchor-less trajectory prediction method, based on Mixture Desity Networks (MDNs) and polynomial trajectory constraints, relying only on on-board sensors which relaxes the HD map requirement and allow more flexibility for driving in the real world. The polynomial formulation ensures that the predicted trajectories are coherent and smooth, while providing more learning flexibility through the extra parameters. We find that this mitigates training instability and mode collapse that are common to MDNs (Cui et al., 2019). PLOP is trainable end-to-end from imitation learning, where data is relatively easier to obtain and it is computationally efficient during both training and inference as it predicts trajectory coefficients in a single step, without requiring a RNN-based decoder. The polynomial function trajectory coefficients eschew the need for anchors (Chai et al., 2019), whose quality can vary across datasets.
We propose an extensive evaluation of PLOP and show its effectiveness across datasets and settings. We conduct a comparison showing the improvement over state-of-the-art PRECOG (Rhinehart et al., 2019) on the public dataset nuScenes (Caesar et al., 2020);
Then for a better evaluation of the driving capacities of PLOP, we study closed loop performance for the ego vehicle, on simulation and with preliminary insights for real vehicle control.
Network architecture
PLOP takes as inputs: the ego and neighbor vehicles past positions represented as time sequences of x and y over the last 2 seconds, the frontal camera image of the ego vehicle, and 2 second history of bird’s eye views with a cell resolution of 1m square containing the lidar point cloud and the object detections information represented in Figure 2. The objects detections being the output of a state of the art perception algorithm.
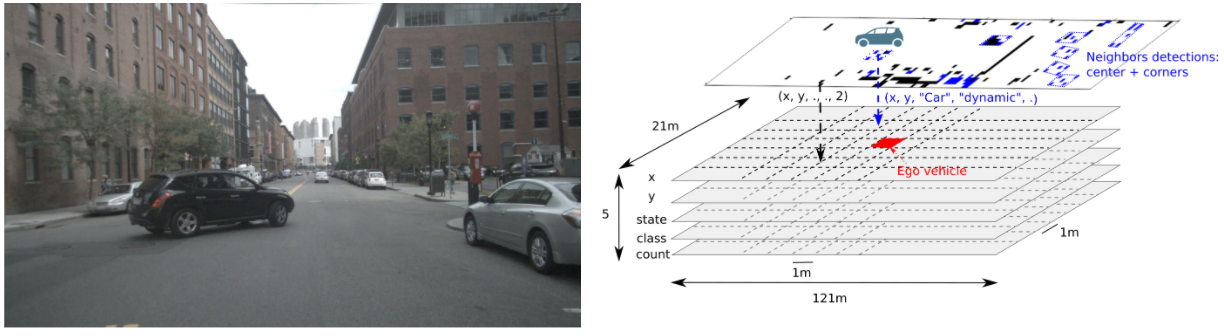
We pass these inputs through a multibranch neural network represented in Figure 3 to predict the ego vehicle future trajectory and two auxiliary tasks that are the future trajectory prediction for the neighbors vehicles and the semantic segmentation of the camera image.
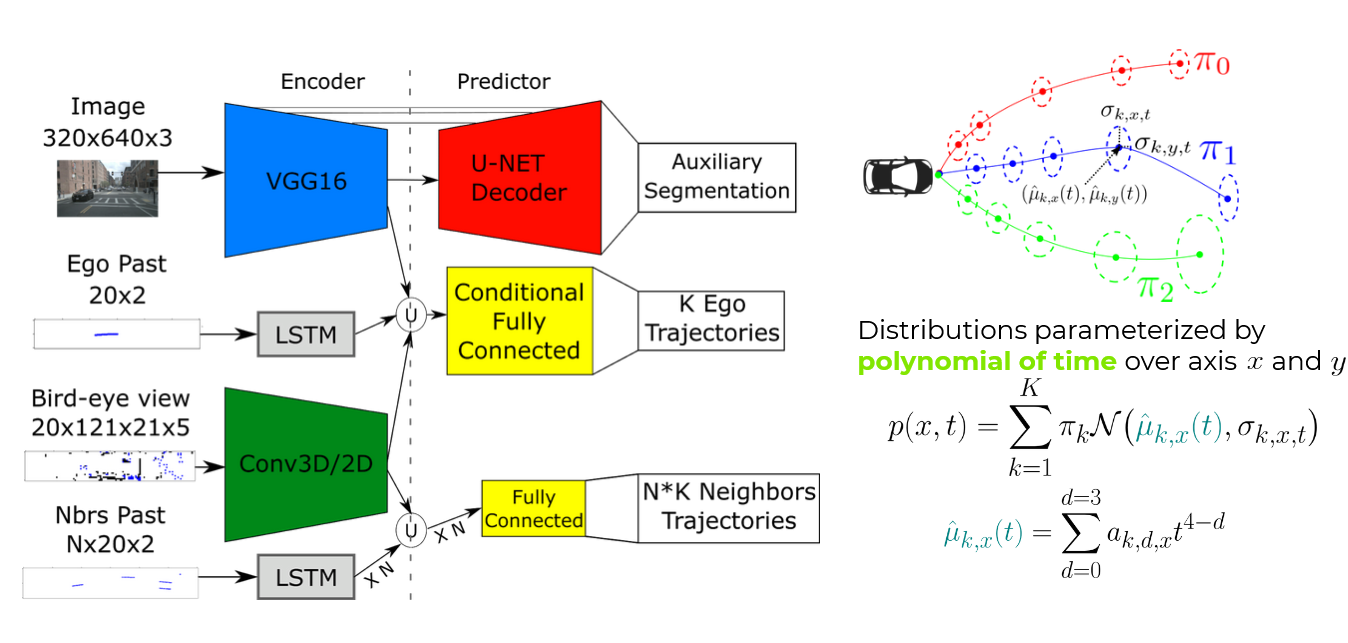
The front camera image features, the bird’s eye view features and the ego vehicle past positions features are passed down to conditional fully connected architecture to output multiple future trajectories for the ego vehicle regarding the current navigation order. The trajectories are predicted using MDNs where gaussian means are generated using polynomial functions of degree 4 over x and y
To improve the learning stability of our training and inject awareness about the scene layouts into the camera features we pass them through a U-Net decoder to output semantic segmentation and then use an auxiliary cross entropy loss. To improve the encoding of interactions between the differents agents of the scene in the bird’s eye features, we predict the future possible trajectories for each neighbor feeding the bird’s eye views encoding and its past positions encoded through a LSTM layer to a small fully connected network. The weights of LSTMs and fully connected layers are shared between all neighbors. This output allows us to get useful information about the ego vehicle environment that can be used online to improve the ego vehicle driving with safety collision checks for example.
Offline evaluation
To evaluate PLOP, we use the nuScenes dataset to train the trajectory loss along with the Audi (Geyer et al., 2019) dataset to train the semantic segmentation loss. We choose to compare our method with the DESIRE (Lee et al., 2017) baseline and against two state of the art methods that are PRECOG and ESP (Rhinehart et al., 2019) using the minimum Mean Squared Deviation metric to avoid penalizing valid trajectories that are not matching the ground truth. For one agent, meaning ego vehicle only, PRECOG and ESP have access to the future desired target position and PRECOG return significantly better results than PLOP but PLOP still reaches similar results as ESP. For multiple agents PLOP outperforms other presented methods . We note that the comparison if fairer for neighbor trajectories and the performance is relevant since they are by definition open loop.
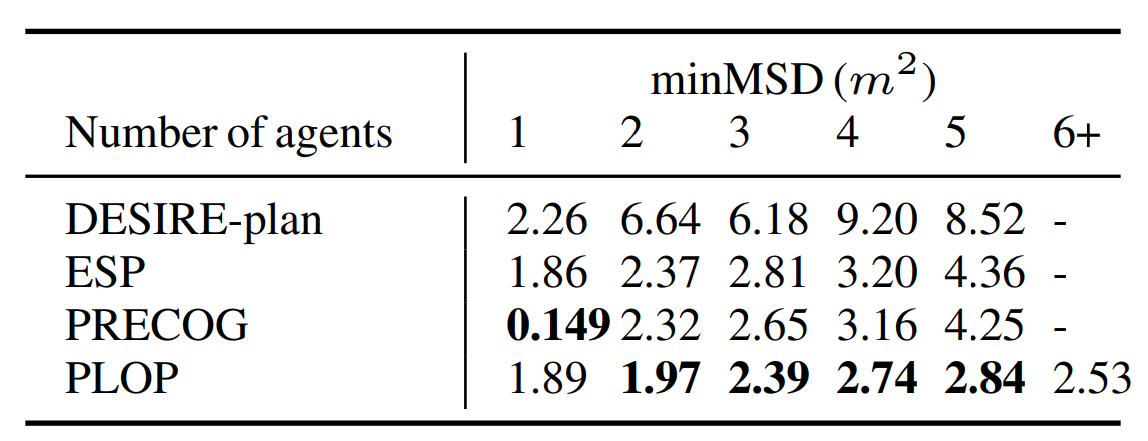
But we argue that such evaluation is not totally relevant for controling the ego vehicle in real conditions. Such metrics does not value the situations in which the errors are made, failing to brake at a traffic light is a critical error for example but it is quick and represent a very small part of the test set so it will impact very poorly the overall metrics. However, making a small constant error such as driving 2kph too slow over the whole test set set might be an acceptable and non impacting error but will lead to a considerable overall error. Also, using only offline metrics where the method can’t control the vehicle does not allow us to evaluate its capacities to react to its own mistakes.
Online Evaluation through simulation
To simulate driving, we developped a data driven simulator that allows us to use real driving data to simulate applying the prediction to the ego vehicle. We can generate the input data that corresponds to the new vehicle position after following the trajectory using reprojections (for the image and the pointcloud), then use it to predict a new trajectory, and so on. This allows us the measure the performance in closed loop, and in particular to count failures which would have resulted in a takeover. We rely on 3 metrics: lateral (>1m from expert), high speed (catching up to a vehicle 15% faster than the real vehicle up to 0.6s in the future) and low speed (> 20kph under the expert speed) errors count.
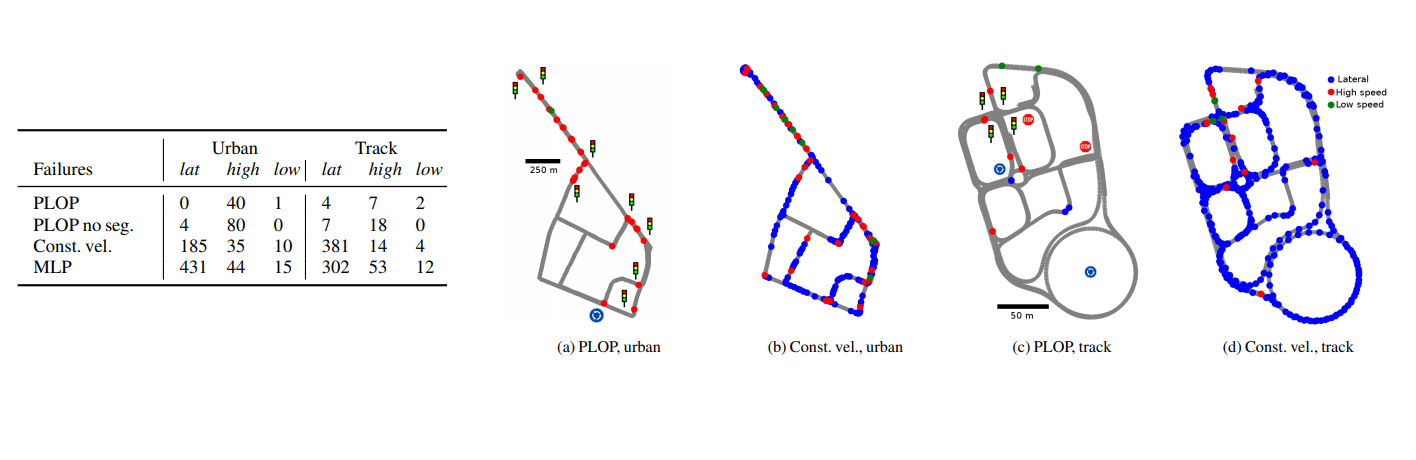
We trained PLOP on an internal dataset combining both open road and urban test track and compared PLOP, PLOP without auxiliary semantic loss, the constant velocity baseline and a MLP baseline in our simulator using test data. We note that semantic segmentation improve the driving performance and that MLP has better offline metrics than constant velocity approach but still perform worse due to the simulated driving conditions. As expected, offline metrics are not discriminating enough for the online behavior since the best model checkpoints in simulation are not necessarily the ones with the better offline metrics. An additionnal ablation study where we remove mandatory information (such as the camera image input) shows that it may even be dangerous to trust them blindly.
Conclusion
In this work, we demonstrate the interest of our multi-input multimodal approach PLOP for vehicle trajectory prediction in an urban environment. Our architecture leverages frontal camera and Lidar inputs, to produce multiple trajectories using reparameterized Mixture Density Networks, with an auxiliary semantic segmentation task. We show that we can improve open loop state-of-the-art performance in a multi-agent system, by evaluating the vehicle trajectories from the nuScenes dataset. We also provide a simulated closed loop evaluation, to go towards real vehicle online application. Please check out our paper along with supplementary materials for greater details about our approach and experiments and feel free to contact us for any question.
References
- Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuScenes: A Multimodal Dataset for Autonomous Driving. In cvpr, 2020.
- Mayank Bansal, Alex Krizhevsky, and Abhijit S. Ogale. ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Worst. CoRR, 2018.
- Yuning Chai, Benjamin Sapp, Mayank Bansal, and Dragomir Anguelov. MultiPath: Multiple Probabilistic Anchor Trajectory Hypotheses for Behavior Prediction. Oct 2019.
- Joey Hong, Benjamin Sapp, and James Philbin. Rules of the Road: Predicting Driving Behavior with a Convolutional Model of Semantic Interactions. CoRR, 2019.
- Nicholas Rhinehart, Rowan McAllister, Kris Kitani, and Sergey Levine. Precog: Prediction conditioned on goals in visual multi-agent settings. In iccv, 2019.
- Charlie Tang, and Russ R Salakhutdinov. Multiple futures prediction. In Advances in Neural Information Processing Systems, 2019.
- Agrim Gupta, Justin Johnson, Li Fei-Fei, Silvio Savarese, and Alexandre Alahi. Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks. CoRR, 2018.
- Nicholas Rhinehart, Rowan McAllister, and Sergey Levine. Deep Imitative Models for Flexible Inference, Planning, and Control. CoRR, 2018.
- Tung Phan-Minh, Elena Corina Grigore, Freddy A Boulton, Oscar Beijbom, and Eric M Wolff. Covernet: Multimodal behavior prediction using trajectory sets. In cvpr, 2020.
- Francesco Marchetti, Federico Becattini, Lorenzo Seidenari, and Alberto Del Bimbo. Mantra: Memory augmented networks for multiple trajectory prediction. In cvpr, 2020.
- Eshed Ohn-Bar, Aditya Prakash, Aseem Behl, Kashyap Chitta, and Andreas Geiger. Learning Situational Driving. In cvpr, 2020.
- Henggang Cui, Vladan Radosavljevic, Fang-Chieh Chou, Tsung-Han Lin, Thi Nguyen, Tzu-Kuo Huang, Jeff Schneider, and Nemanja Djuric. Multimodal trajectory predictions for autonomous driving using deep convolutional networks. In icra, 2019.
- Jakob Geyer, Yohannes Kassahun, Mentar Mahmudi, Xavier Ricou, Rupesh Durgesh, Andrew S. Chung, Lorenz Hauswald, Viet Hoang Pham, Maximilian Mühlegg, Sebastian Dorn, Tiffany Fernandez, Martin Jänicke, Sudesh Mirashi, Chiragkumar Savani, Martin Sturm, Oleksandr Vorobiov, and Peter Schuberth. A2D2: AEV Autonomous Driving Dataset. 2019.
- Namhoon Lee, Wongun Choi, Paul Vernaza, Chris Choy, Philip Torr, and Manmohan Chandraker. DESIRE: Distant Future Prediction in Dynamic Scenes with Interacting Agents. In , Jul 2017.