valeo.ai at NeurIPS 2025
The Neural Information Processing Systems Conference (NeurIPS) is a major inter-disciplinary event that brings together researchers and practicioners in machine learning, computer vision, natural language processing, optimization, statistics, but also neuroscience, natural sciences, social sciences, etc. This year, at the 39th edition of NeurIPS, the valeo.ai team will present 5 papers in the main conference and 1 in the workshops. We are honored to announce that our IPA paper on efficient foundation model adaptation has received the outstanding paper award at the CCFM workshop. Our team contributed to the technical program committee with multiple reviewers out of whom 1 was awarded top reviewer and 2 as top area chairs.
The team will be at NeurIPS to present these works, exchange ideas, and share our exciting ongoing research. We look forward to seeing you in San Diego!

JAFAR: Jack up Any Feature at Any Resolution
Authors: Paul Couairon, Loick Chambon , Louis Serrano, Jean-Emmanuel Haugeard, Matthieu Cord, Nicolas Thome
[Paper] [Code]
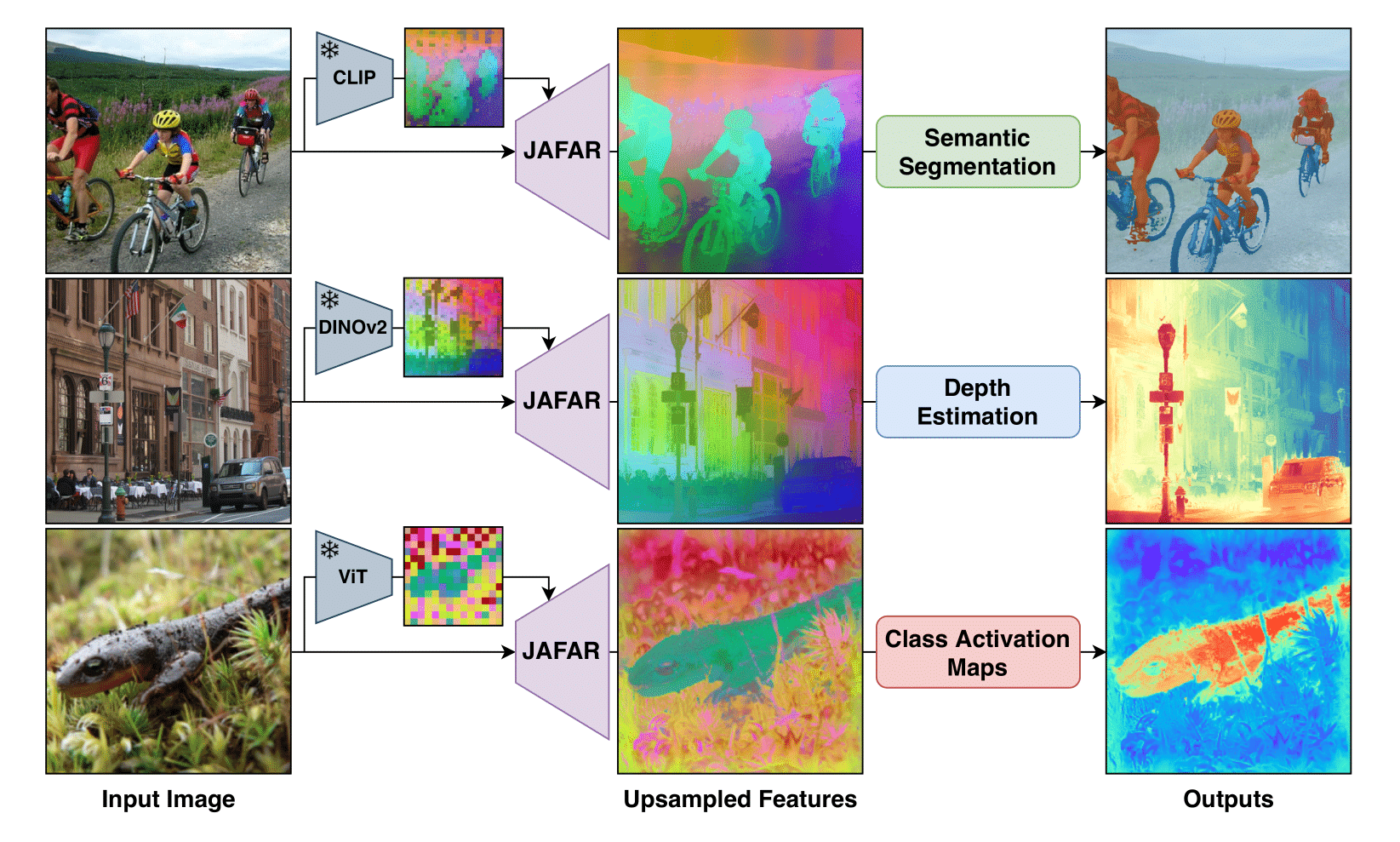
Foundation Vision Encoders have become essential for a wide range of dense vision tasks. However, their low-resolution spatial feature outputs necessitate feature upsampling to produce the high-resolution modalities required for downstream tasks. In this work, we introduce JAFAR—a lightweight and flexible feature upsampler that enhances the spatial resolution of visual features from any Foundation Vision Encoder to an arbitrary target resolution. JAFAR employs an attention-based module designed to promote semantic alignment between high-resolution queries—derived from low-level image features—and semantically enriched low-resolution keys, using Spatial Feature Transform (SFT) modulation. Notably, despite the absence of high-resolution supervision, we demonstrate that learning at low upsampling ratios and resolutions generalizes remarkably well to significantly higher output scales. Extensive experiments show that JAFAR effectively recovers fine-grained spatial details and consistently outperforms existing feature upsampling methods across a diverse set of downstream tasks.
DINO-Foresight: Looking into the Future with DINO
Authors: Efstathios Karypidis, Ioannis Kakogeorgiou, Spyros Gidaris, Nikos Komodakis
[Paper] [Code]
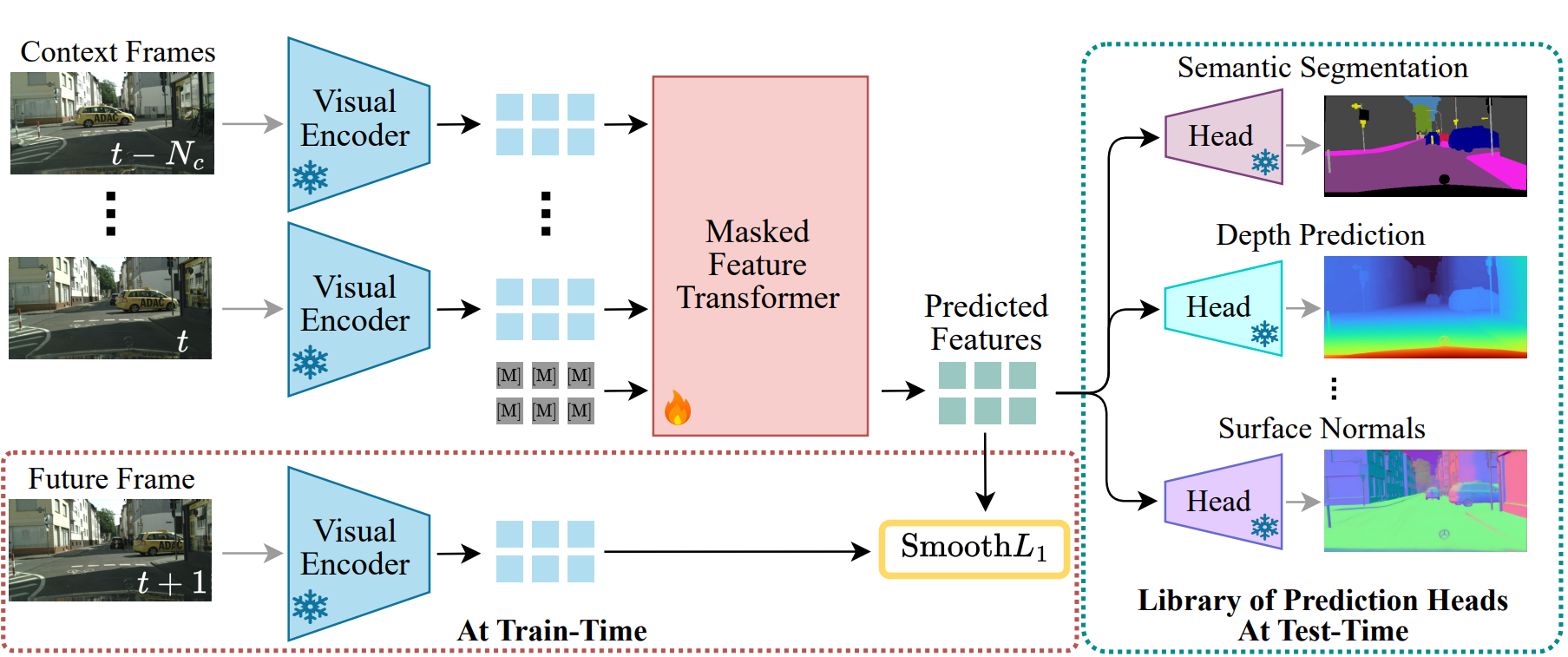
Predicting future dynamics is crucial for applications like autonomous driving and robotics, where understanding the environment is key. Existing pixel-level methods are computationally expensive and often focus on irrelevant details. To address these challenges, we introduce DINO-Foresight, a novel framework that operates in the semantic feature space of pretrained Vision Foundation Models (VFMs). Our approach trains a masked feature transformer in a self-supervised manner to predict the evolution of VFM features over time. By forecasting these features, we can apply off-the-shelf, task-specific heads for various scene understanding tasks. In this framework, VFM features are treated as a latent space, to which different heads attach to perform specific tasks for future-frame analysis. Extensive experiments show the very strong performance, robustness and scalability of our framework.
Learning to Steer: Input-dependent Steering for Multimodal LLMs
Authors: Jayneel Parekh, Pegah Khayatan, Mustafa Shukor, Arnaud Dapogny, Alasdair Newson, Matthieu Cord
[Paper] [Code]
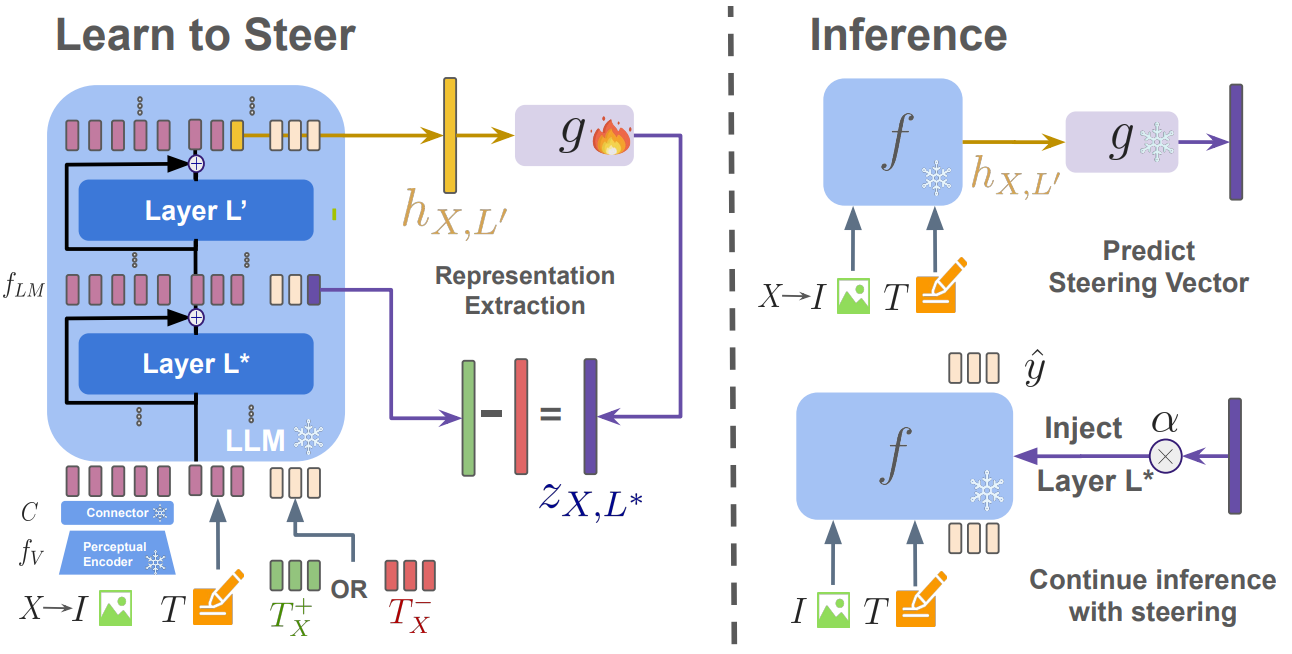
Steering has emerged as a practical approach to enable post-hoc guidance of LLMs towards enforcing a specific behavior. However, it remains largely underexplored for multimodal LLMs (MLLMs); furthermore, existing steering techniques, such as mean steering, rely on a single steering vector, applied independently of the input query. This paradigm faces limitations when the desired behavior is dependent on the example at hand. For example, a safe answer may consist in abstaining from answering when asked for an illegal activity, or may point to external resources or consultation with an expert when asked about medical advice. In this paper, we investigate a fine-grained steering that uses an input-specific linear shift. This shift is computed using contrastive input-specific prompting. However, the input-specific prompts required for this approach are not known at test time. Therefore, we propose to train a small auxiliary module to predict the input-specific steering vector. Our approach, dubbed as L2S (Learn-to-Steer), demonstrates that it reduces hallucinations and enforces safety in MLLMs, outperforming other static baselines.
Boosting Generative Image Modeling via Joint Image-Feature Synthesis
Authors: Theodoros Kouzelis, Efstathios Karypidis, Ioannis Kakogeorgiou, Spyros Gidaris, Nikos Komodakis
[Paper] [Code]
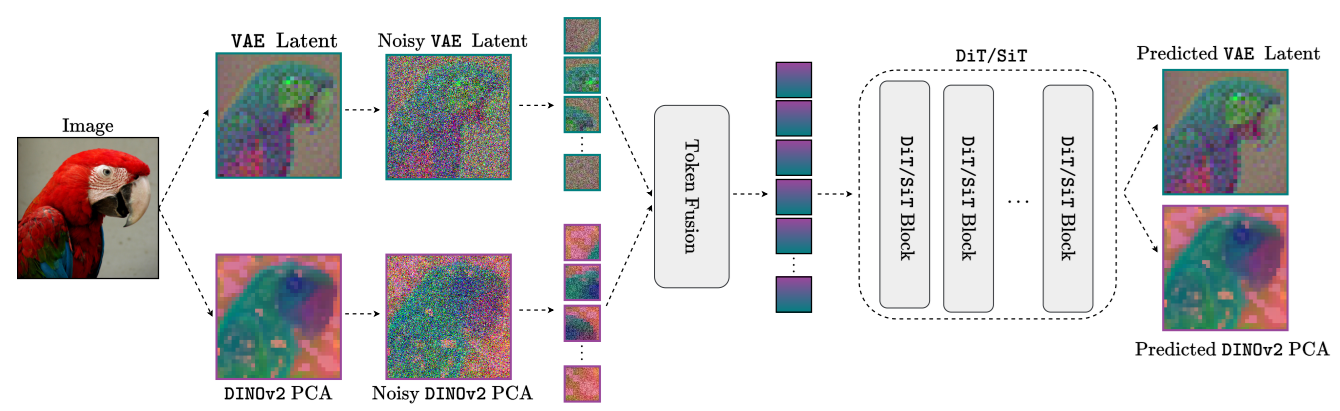
Latent diffusion models (LDMs) dominate high-quality image generation, yet integrating representation learning with generative modeling remains a challenge. We introduce a novel generative image modeling framework that seamlessly bridges this gap by leveraging a diffusion model to jointly model low-level image latents (from a variational autoencoder) and high-level semantic features (from a pretrained self-supervised encoder like DINO). Our latent-semantic diffusion approach learns to generate coherent image-feature pairs from pure noise, significantly enhancing both generative quality and training efficiency, all while requiring only minimal modifications to standard Diffusion Transformer architectures. By eliminating the need for complex distillation objectives, our unified design simplifies training and unlocks a powerful new inference strategy: Representation Guidance, which leverages learned semantics to steer and refine image generation. Evaluated in both conditional and unconditional settings, our method delivers substantial improvements in image quality and training convergence speed, establishing a new direction for representation-aware generative modeling.
Multi-Token Prediction Needs Registers
Authors: Anastasios Gerontopoulos, Spyros Gidaris, Nikos Komodakis
[Paper] [Code]
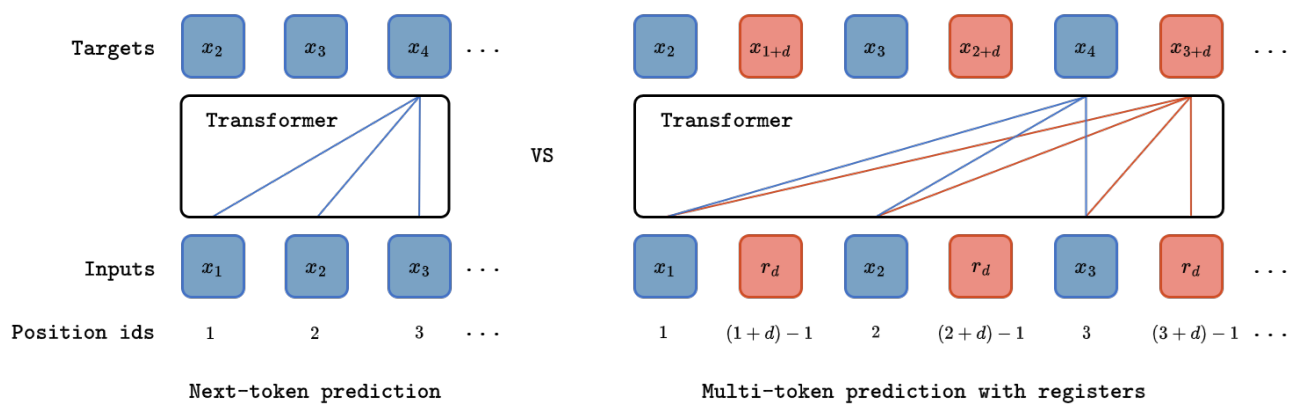
Multi-token prediction has emerged as a promising objective for improving language model pretraining, but its benefits have not consistently generalized to other settings such as fine-tuning. In this paper, we propose MuToR, a simple and effective approach to multi-token prediction that interleaves learnable register tokens into the input sequence, each tasked with predicting future targets. Compared to existing methods, MuToR offers several key advantages: it introduces only a negligible number of additional parameters, requires no architectural changes–ensuring compatibility with off-the-shelf pretrained language models–and remains aligned with the next-token pretraining objective, making it especially well-suited for supervised fine-tuning. Moreover, it naturally supports scalable prediction horizons. We demonstrate the effectiveness and versatility of MuToR across a range of use cases, including supervised fine-tuning, parameter-efficient fine-tuning (PEFT), and pretraining, on challenging generative tasks in both language and vision domains.
IPA: An Information-Preserving Input Projection Framework for Efficient Foundation Model Adaptation
NeurIPS 2025 Workshop on Continual and Compatible Foundation Model Updates (CCFM)
Authors: Yuan Yin, Shashanka Venkataramanan, Tuan-Hung Vu, Andrei Bursuc, Matthieu Cord
[Paper]
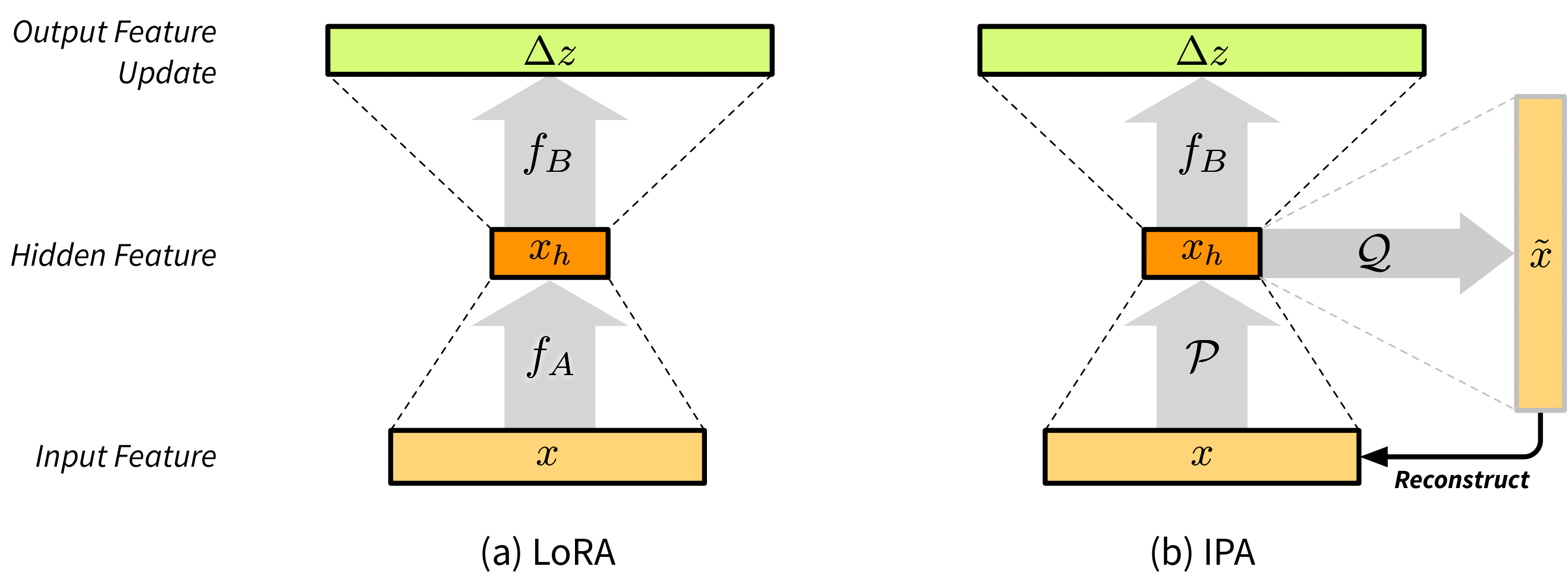
Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, reduce adaptation cost by injecting low-rank updates into pretrained weights. However, LoRA’s down-projection is randomly initialized and data-agnostic, discarding potentially useful information. Prior analyses show that this projection changes little during training, while the up-projection carries most of the adaptation, making the random input compression a performance bottleneck. We propose IPA, a feature-aware projection framework that explicitly preserves information in the reduced hidden space. In the linear case, we instantiate IPA with algorithms approximating top principal components, enabling efficient projector pretraining with negligible inference overhead. Across language and vision benchmarks, IPA consistently improves over LoRA and DoRA, achieving on average 1.5 points higher accuracy on commonsense reasoning and 2.3 points on VTAB-1k, while matching full LoRA performance with roughly half the trainable parameters when the projection is frozen.