valeo.ai at NeurIPS 2023
The Neural Information Processing Systems Conference (NeurIPS) is a major inter-disciplinary event that brings together researchers and practicioners in machine learning, computer vision, natural language processing, optimization, statistics, but also neuroscience, natural sciences, social sciences, etc. This year, at the thirty-seventh edition of NeurIPS, the valeo.ai team will present 4 papers in the main conference and 1 in the workshops.
Notably, we explore perception via different sensors, e.g., audio, on the path towards increasingly autonomous systems. We also study the interaction between different sensing modalities (images, language, Lidar point clouds) and advance a tri-modal self-supervised learning algorithm for 3D semantic voxel occupancy prediction from a rig of cameras mounted on a vehicle. We further show how to obtain robust deep models starting from pre-trained foundation models finetuned with reinforcement learning from human feedback. Finally, we analyze different generative models (diffusion models, GANs) and advance a unification framework considering them as instances of Particle Models.
We will be happy to discuss more about these projects and ideas, and share our exciting ongoing research. Take a quick view of our papers below and come meet us at the posters or catch us for a coffee in the hallways.
Resilient Multiple Choice Learning: A learned scoring scheme with application to audio scene analysis
Authors: Victor Letzelter, Mathieu Fontaine, Mickaël Chen, Patrick Pérez, Slim Essid, Gaël Richard
[Paper] [Code] [Project page]
In this work, we tackle ambiguous machine learning tasks, where single predictions don’t suffice due to the task’s nature or inherent uncertainties. We introduce a robust multi-hypotheses framework that is capable of deterministically offering a range of plausible predictions at inference time. Our experiments on both synthetic data and real-world audio data affirm the potential and versatility of our method. Check out the paper and the code for more details.
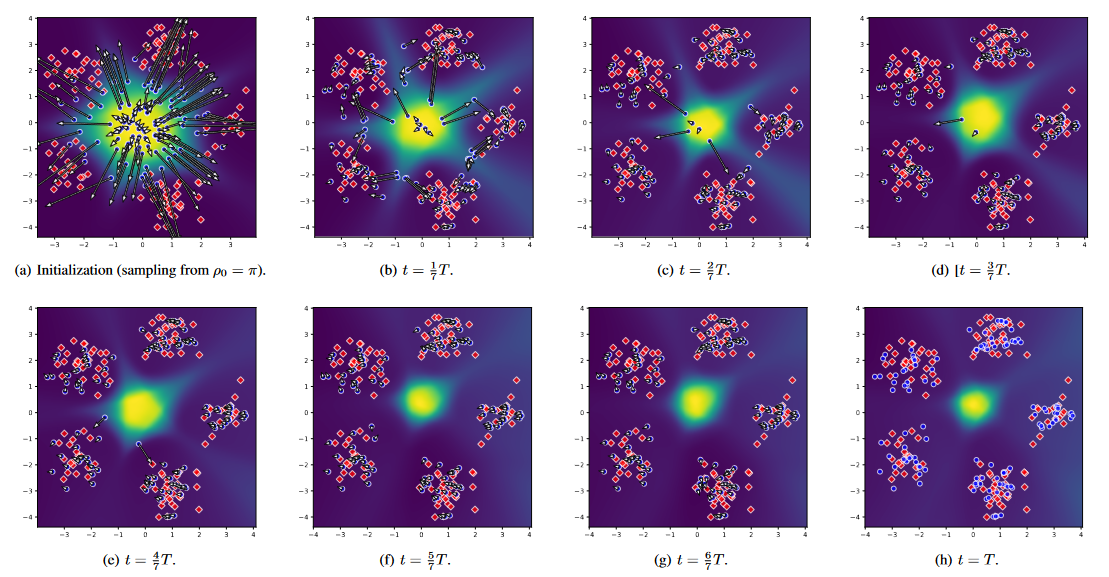
This problem involves estimating a conditional distribution that is dependent on the input. The accompanying animation illustrates the early stages in the evolution of our model’s learning process, highlighting how it progressively refines its predictions (represented by shaded blue points) to the actual data distribution (indicated by green points), which varies with the input ‘t’.
POP-3D: Open-Vocabulary 3D Occupancy Prediction from Images
Authors: Antonin Vobecky, Oriane Siméoni, David Hurych, Spyros Gidaris, Andrei Bursuc, Patrick Pérez, Josef Sivic
[Paper] [Code] [Project page]
POP-3D is an approach to predict open-vocabulary 3D semantic voxel occupancy map from input 2D images to enable 3D grounding, segmentation, and retrieval of free-form language queries.

We design a new model architecture for open-vocabulary 3D semantic occupancy prediction. The architecture consists of a 2D-3D encoder together with occupancy prediction and 3D-language heads. The output is a dense voxel map of 3D grounded language embeddings enabling a range of open-vocabulary tasks. Next, we develop a tri-modal self-supervised learning algorithm that leverages three modalities: (i) images, (ii) language, and (iii) LiDAR point clouds and enables training the proposed architecture using a strong pre-trained vision-language model without the need for any 3D manual language annotations.
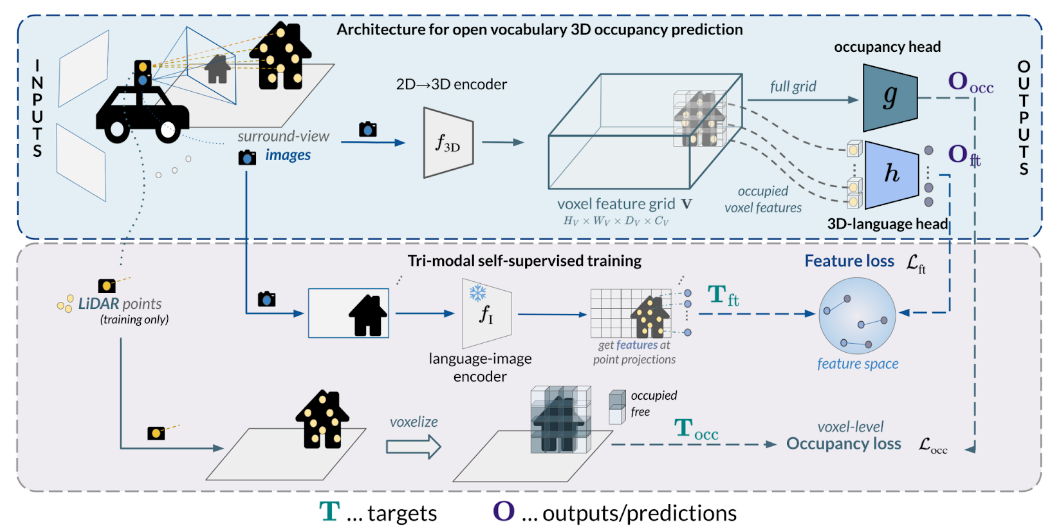
Finally, we demonstrate the strengths of the proposed model quantitatively on several open-vocabulary tasks: Zero-shot 3D semantic segmentation using existing datasets; 3D grounding, and retrieval of free-form language queries, using a small dataset that we propose as an extension of nuScenes.

Rewarded soups: towards Pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards
Authors: Alexandre Ramé, Guillaume Couairon, Mustafa Shukor, Corentin Dancette, Jean-Baptiste Gaya, Laure Soulier, Matthieu Cord
[Paper] [Code] [Project page]
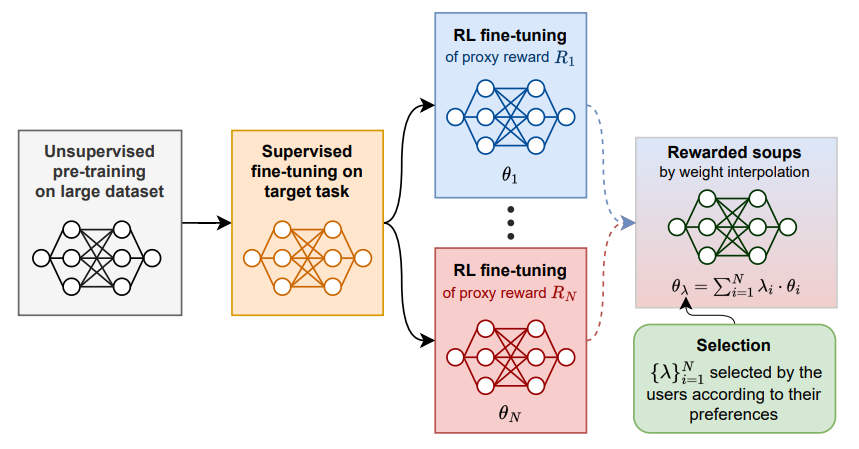
Foundation models are first pre-trained on vast unsupervised datasets and then fine-tuned on labeled data. Reinforcement learning, notably from human feedback (RLHF), can further align the network with the intended usage. Yet the imperfections in the proxy reward may hinder the training and lead to suboptimal results; the diversity of objectives in real-world tasks and human opinions exacerbate the issue. This paper proposes embracing the heterogeneity of diverse rewards by following a multi-policy strategy. Rather than focusing on a single a priori reward, we aim for Pareto-optimal generalization across the entire space of preferences. To this end, we propose rewarded soup, first specializing multiple networks independently (one for each proxy reward) and then interpolating their weights linearly. This succeeds empirically because we show that the weights remain linearly connected when fine-tuned on diverse rewards from a shared pre-trained initialization. We demonstrate the effectiveness of our approach for text-to-text (summarization, Q&A, helpful assistant, review), text-image (image captioning, text-to-image generation, visual grounding, VQA), and control (locomotion) tasks. We hope to enhance the alignment of deep models, and how they interact with the world in all its diversity.
Unifying GANs and Score-Based Diffusion as Generative Particle Models
Authors: Jean-Yves Franceschi, Mike Gartrell, Ludovic Dos Santos, Thibaut Issenhuth, Emmanuel de Bézenac, Mickaël Chen, Alain Rakotomamonjy
[Paper] [Code (coming soon)]
By describing the trajectories of GAN outputs during training with particle evolution equations, we propose an unifying framework for GAN and Diffusion Models. We provide a new insights on the role of the generator network, and as proof of concept validating our theories, we propose methods to train a generator with score-based gradient instead of a discriminator, or to use a discriminator’s gradient flow to generate instead of training a generator.
Evaluating the structure of cognitive tasks with transfer learning
NeurIPS Workshop on AI for Scientific Discovery: From Theory to Practice
Authors: Bruno Aristimunha, Raphael Y. de Camargo, Walter H. Lopez Pinaya, Sylvain Chevallier, Alexandre Gramfort, Cedric Rommel
[Paper] [Code (coming soon)]
Electroencephalography (EEG) decoding is a challenging task due to the limited availability of labeled data. While transfer learning is a promising technique to address this challenge, it assumes that transferable data domains and tasks are known, which is not the case in this setting. This work investigates the transferability of deep learning representations between different EEG decoding tasks.
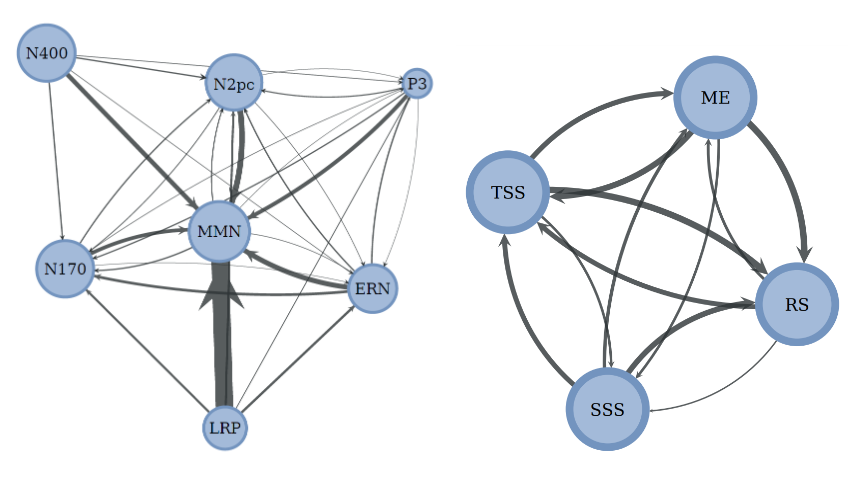
We conduct extensive experiments using state-of-the-art decoding models on two recently released EEG datasets, ERPCore and M3CV, containing over 140 subjects and 11 distinct cognitive tasks.
From an EEG processing perspective, our results can be used to leverage related datasets for alleviating EEG data scarcity with transfer learning. We show that even with a linear probing transfer method, we are able to boost by up to 28% the performance of some tasks. From a neuroscientific standpoint, our transfer maps provide insights into the hierarchical relations between cognitive tasks, hence enhancing our understanding of how these tasks are connected. We discover for example evidence that certain decoding paradigms elicit specific and narrow brain activities, while others benefit from pre-training on a broad range of representations.