valeo.ai at NeurIPS 2024
The Neural Information Processing Systems Conference (NeurIPS) is a major inter-disciplinary event that brings together researchers and practicioners in machine learning, computer vision, natural language processing, optimization, statistics, but also neuroscience, natural sciences, social sciences, etc. This year, at the thirty-eigth edition of NeurIPS, the valeo.ai team will present 7 papers in the main conference.
We will be happy to discuss more about these projects and ideas, and share our exciting ongoing research. Take a quick view of our papers below and come meet us at the posters or catch us for a coffee in the hallways.
No Train, all Gain: Self-Supervised Gradients Improve Deep Frozen Representations
Authors: Walter Simoncini Spyros Gidaris Andrei Bursuc Yuki M. Asano
[Paper] [Code] [Project page]
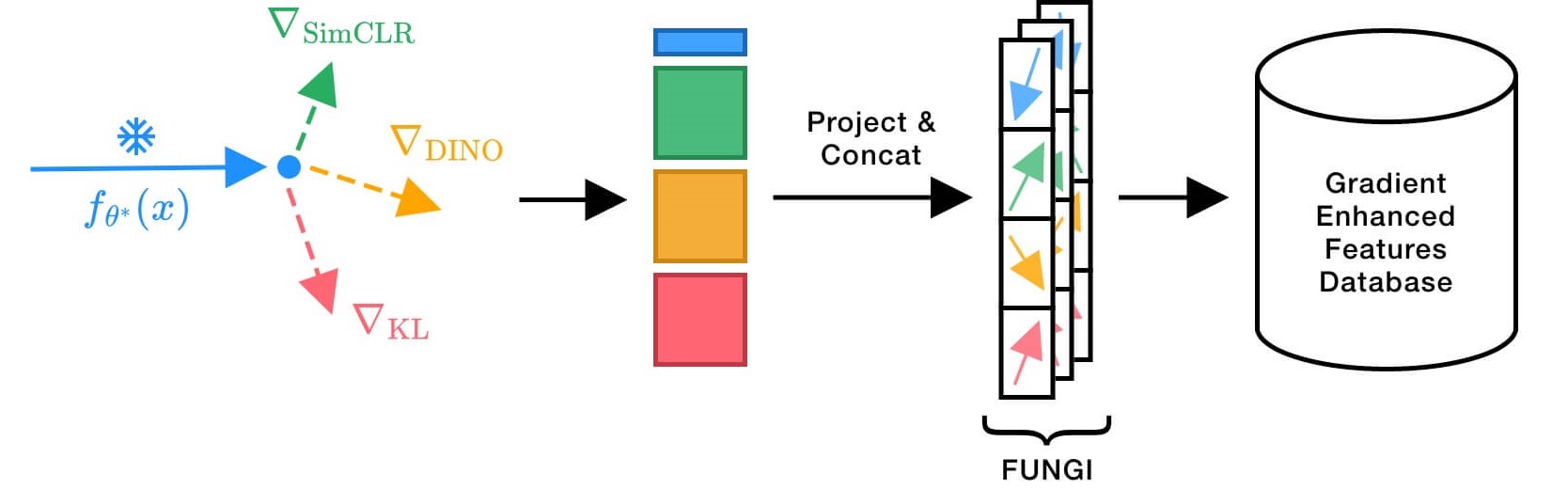
This paper introduces FUNGI: Features from UNsupervised GradIents, a method to enhance the features of vision encoders by leveraging self-supervised gradients. Our method is simple: given any pretrained model, we first compute gradients from various self-supervised objectives for each input. These are projected to a lower dimension and then concatenated with the model’s embedding. The resulting features are evaluated on k-nearest neighbor classification over 11 datasets from vision, 5 from natural language processing, and 2 from audio. Across backbones spanning various sizes and pretraining strategies, FUNGI features provide consistent performance improvements over the embeddings. We also show that using FUNGI features can benefit linear classification and image retrieval, and that they significantly improve the retrieval-based in-context scene understanding abilities of pretrained models, for example improving upon DINO by +17% for semantic segmentation — without any training.
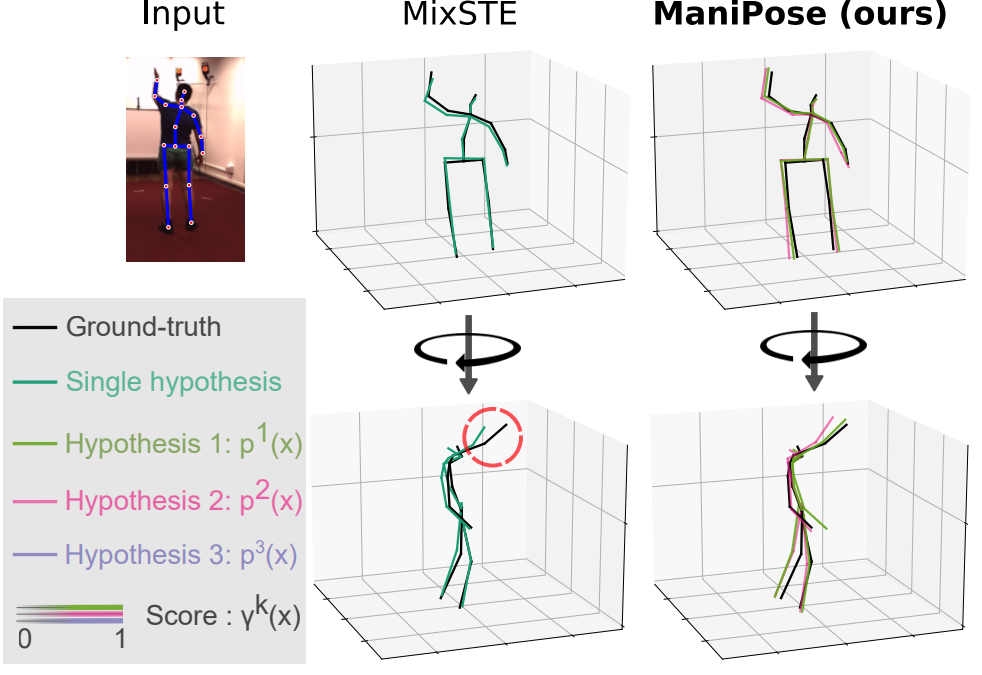
ManiPose: Manifold-Constrained Multi-Hypothesis 3D Human Pose Estimation
Authors: Cédric Rommel Victor Letzelter Nermin Samet Renaud Marlet Matthieu Cord Patrick Pérez Eduardo Valle
[Paper] [Code] [Project page]
We propose ManiPose, a manifold-constrained multi-hypothesis model for human-pose 2D-to-3D lifting. We provide theoretical and empirical evidence that, due to the depth ambiguity inherent to monocular 3D human pose estimation, traditional regression models suffer from pose-topology consistency issues, which standard evaluation metrics (MPJPE, P-MPJPE and PCK) fail to assess. ManiPose addresses depth ambiguity by proposing multiple candidate 3D poses for each 2D input, each with its estimated plausibility. Unlike previous multi-hypothesis approaches, ManiPose forgoes generative models, greatly facilitating its training and usage. By constraining the outputs to lie on the human pose manifold, ManiPose guarantees the consistency of all hypothetical poses, in contrast to previous works. We showcase the performance of ManiPose on real-world datasets, where it outperforms state-of-the-art models in pose consistency by a large margin while being very competitive on the MPJPE metric.
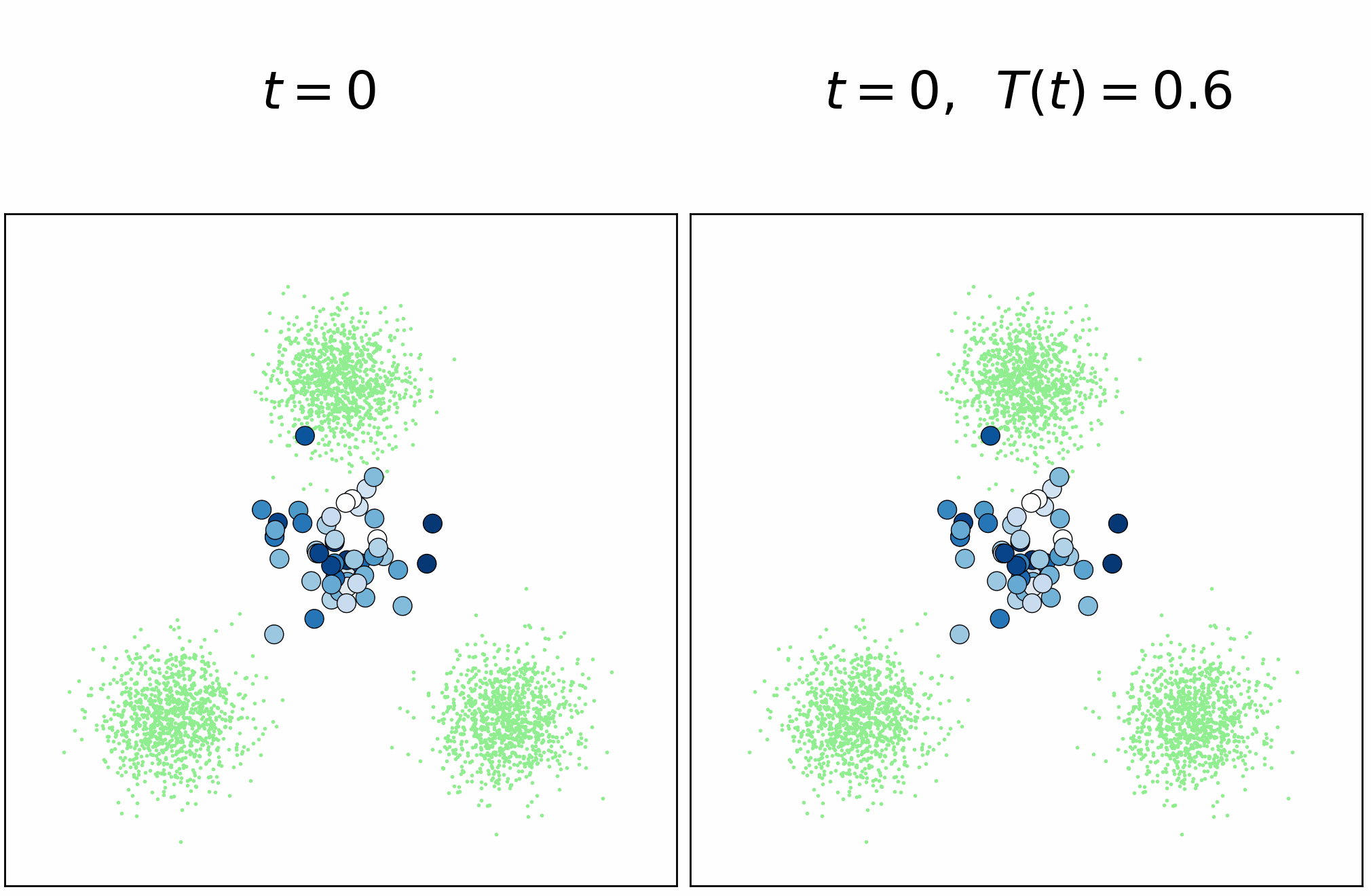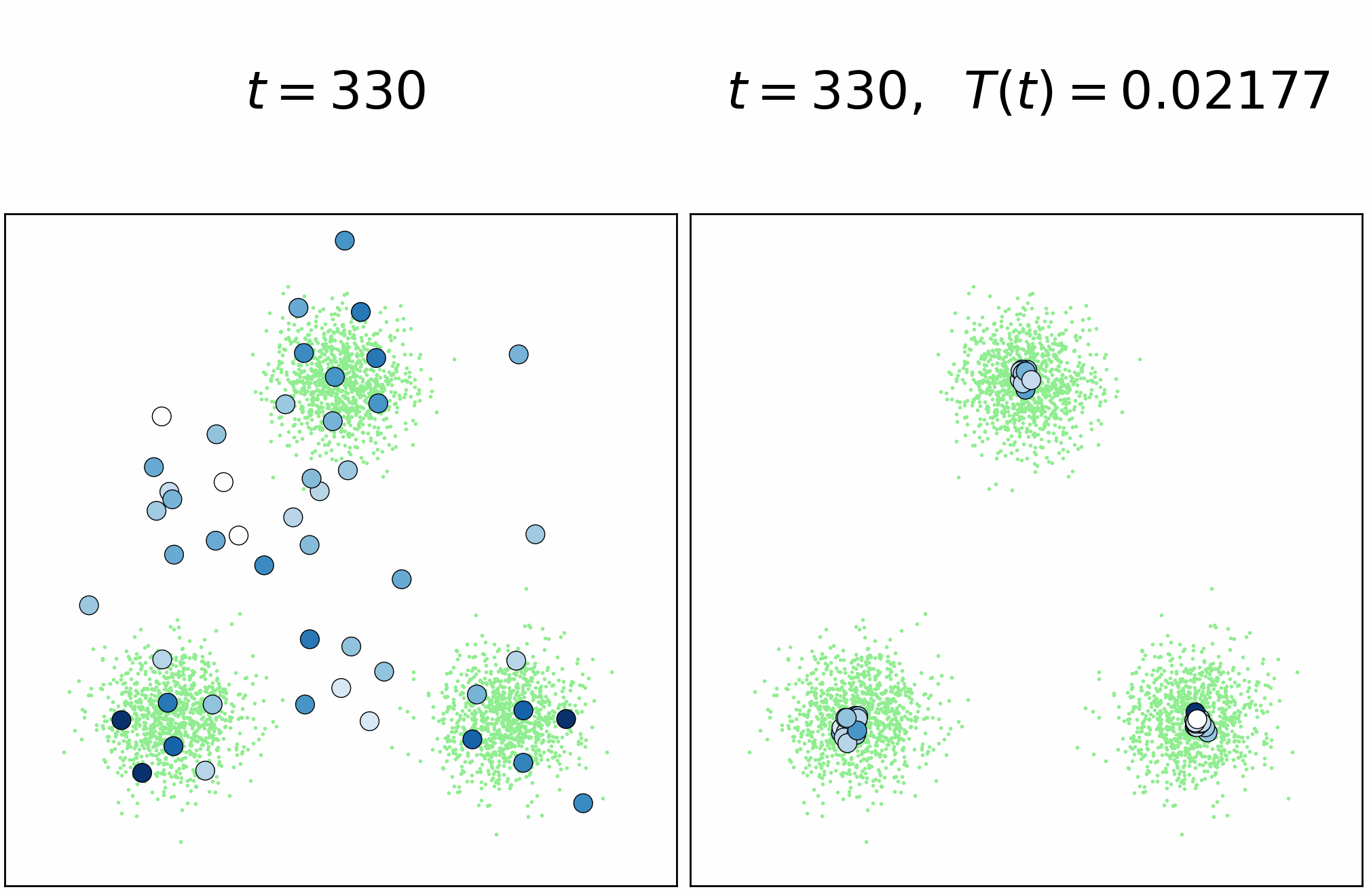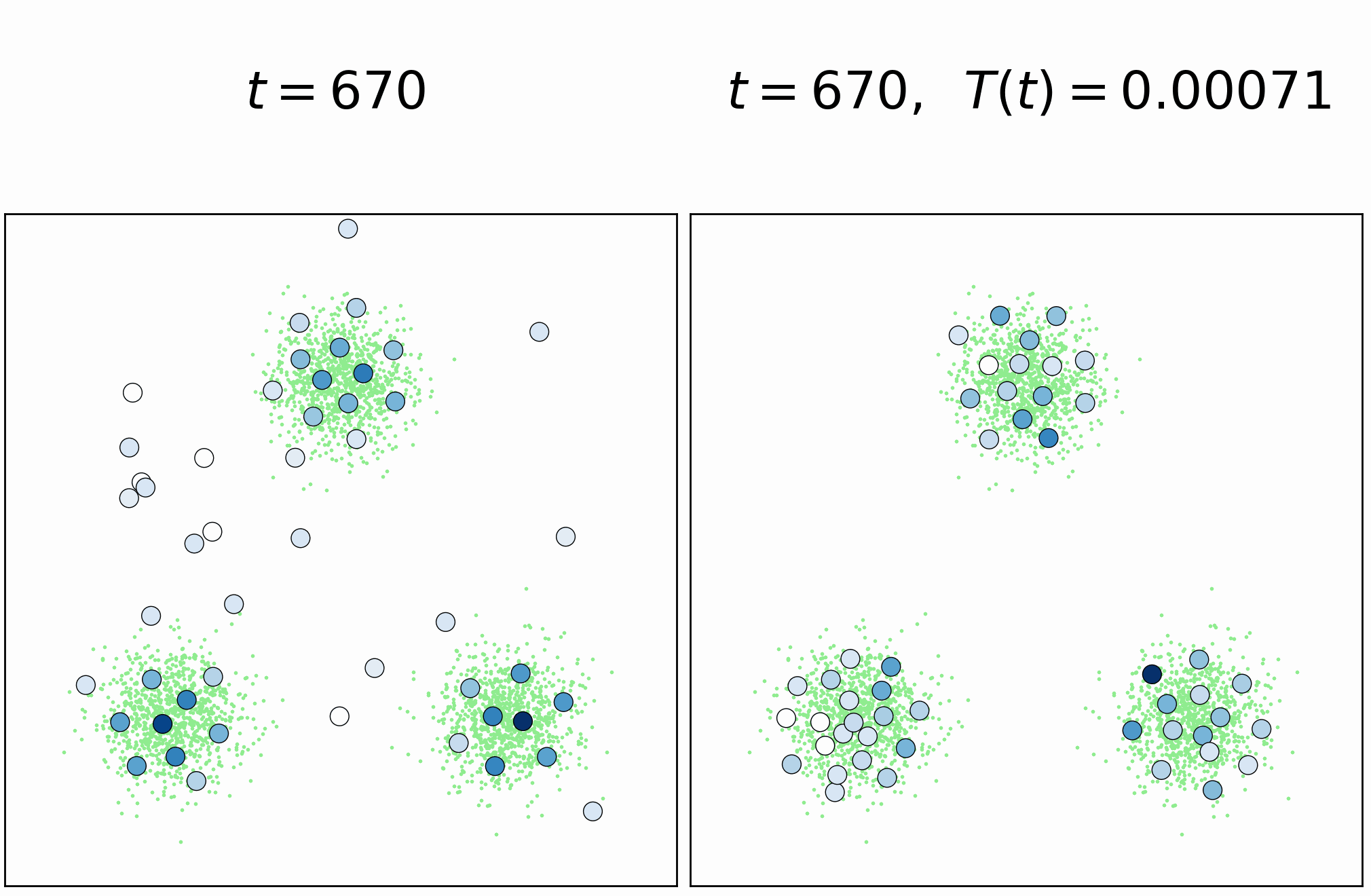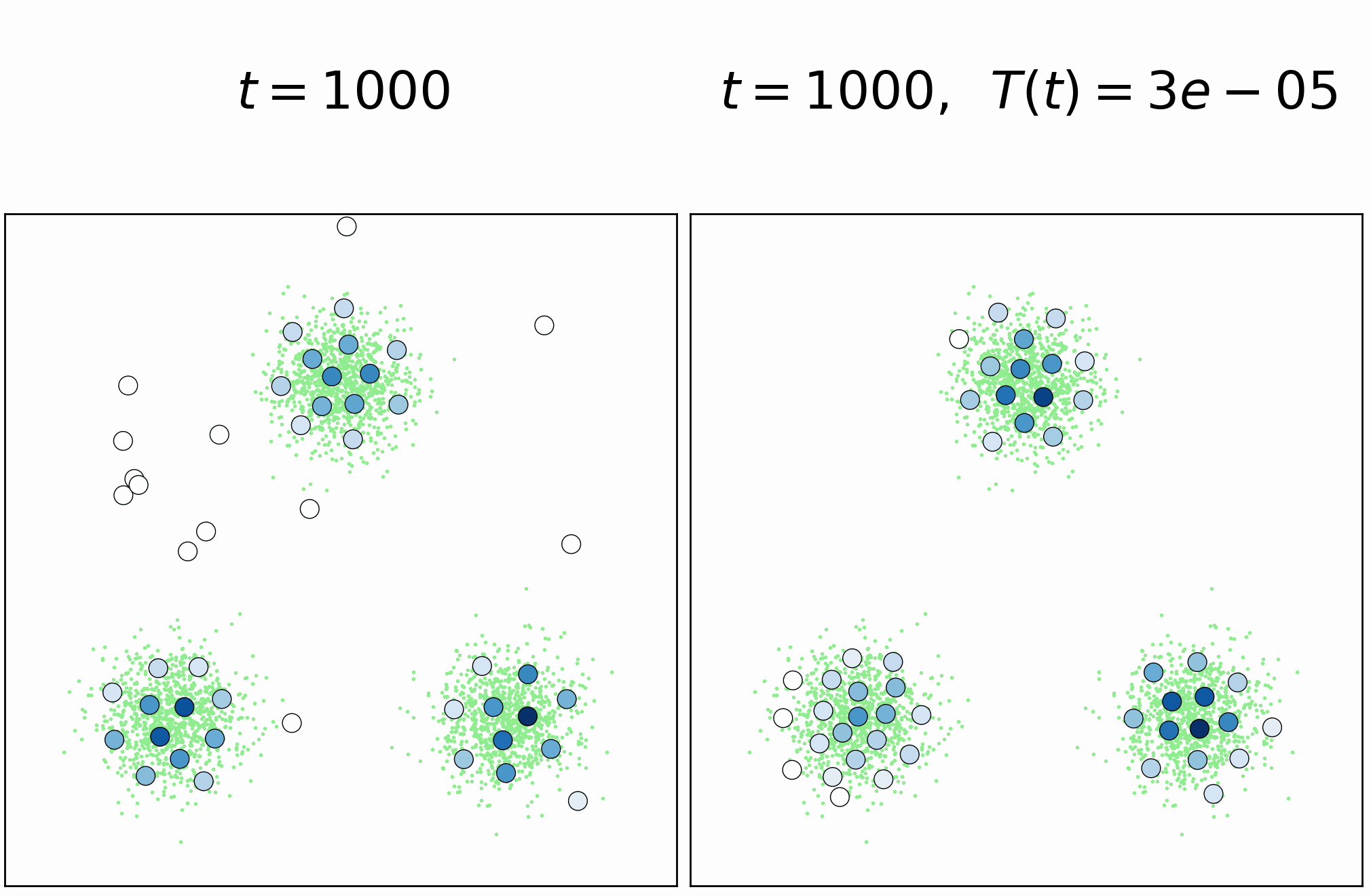
Annealed Multiple Choice Learning: Overcoming limitations of Winner-takes-all with annealing
Authors: David Perera Victor Letzelter Théo Mariotte Adrien Cortés Mickael Chen Slim Essid Gaël Richard
[Paper] [Code] [Project page]
We introduce Annealed Multiple Choice Learning (aMCL) which combines simulated annealing with MCL. MCL is a learning framework handling ambiguous tasks by predicting a small set of plausible hypotheses. These hypotheses are trained using the Winner-takes-all (WTA) scheme, which promotes the diversity of the predictions. However, this scheme may converge toward an arbitrarily suboptimal local minimum, due to the greedy nature of WTA. We overcome this limitation using annealing, which enhances the exploration of the hypothesis space during training. We leverage insights from statistical physics and information theory to provide a detailed description of the model training trajectory. Additionally, we validate our algorithm by extensive experiments on synthetic datasets, on the standard UCI benchmark, and on speech separation.
GEPS: Boosting Generalization in Parametric PDE Neural Solvers through Adaptive Conditioning
Authors: Armand Kassaï Koupaï Jorge Mifsut-Benet Yuan Yin Jean-Noël Vittaut Patrick Gallinari
[Paper] [Code] [Project page]
Solving parametric partial differential equations (PDEs) presents significant challenges for data-driven methods due to the sensitivity of spatio-temporal dynamics to variations in PDE parameters. Machine learning approaches often struggle to capture this variability. To address this, data-driven approaches learn parametric PDEs by sampling a very large variety of trajectories with varying PDE parameters. We first show that incorporating conditioning mechanisms for learning parametric PDEs is essential and that among them, \textit{adaptive conditioning}, allows stronger generalization. As existing adaptive conditioning methods do not scale well with respect to the number of PDE parameters, we propose GEPS, a simple adaptation mechanism to boost GEneralization in Pde Solvers via a first-order optimization and low-rank rapid adaptation of a small set of context parameters. We demonstrate the versatility of our approach for both fully data-driven and for physics-aware neural solvers. Validation performed on a whole range of spatio-temporal forecasting problems demonstrates excellent performance for generalizing to unseen conditions including initial conditions, PDE coefficients, forcing terms and solution domain.
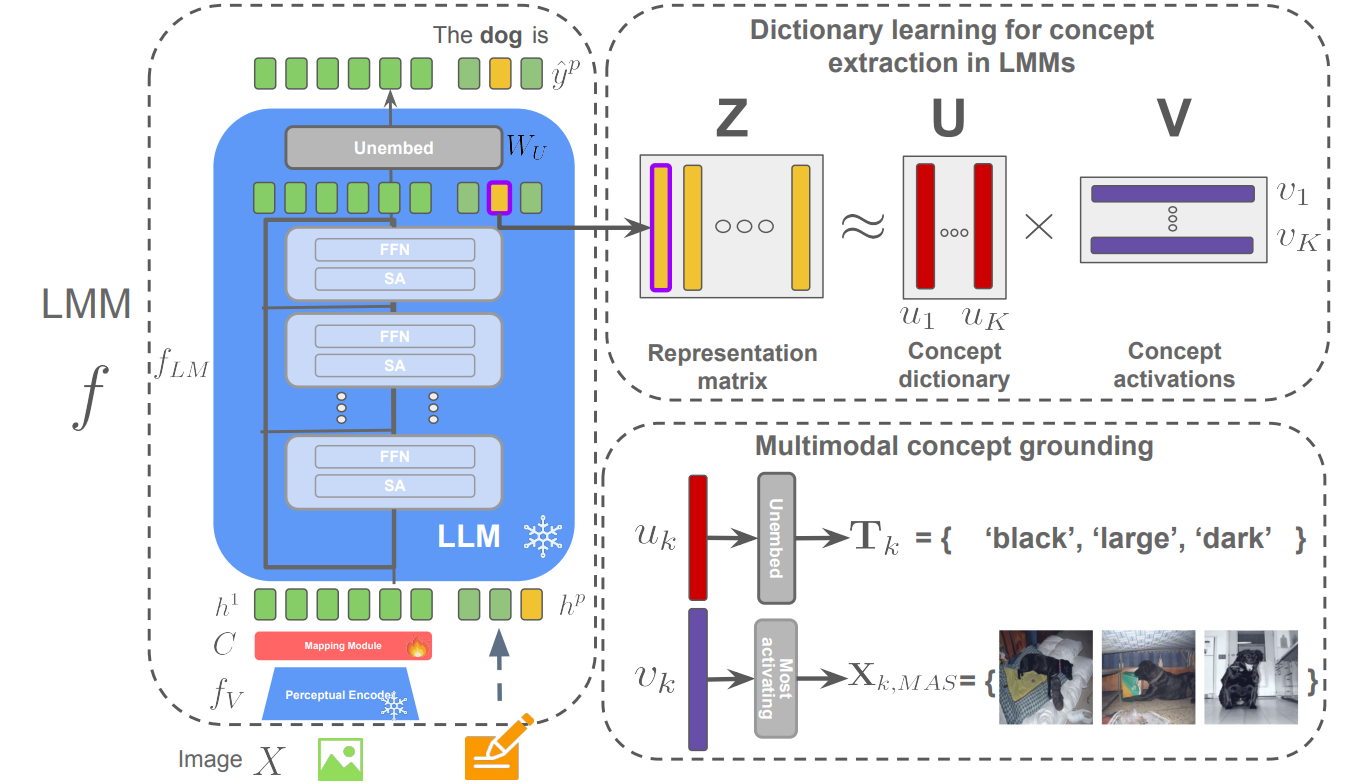
A Concept-Based Explainability Framework for Large Multimodal Models
Authors: Jayneel Parekh Pegah Khayatan Mustafa Shukor Alasdair Newson Matthieu Cord
[Paper] [Code] [Project page]
Large multimodal models (LMMs) combine unimodal encoders and large language models (LLMs) to perform multimodal tasks. Despite recent advancements towards the interpretability of these models, understanding internal representations of LMMs remains largely a mystery. In this paper, we present a novel framework for the interpretation of LMMs. We propose a dictionary learning based approach, applied to the representation of tokens. The elements of the learned dictionary correspond to our proposed concepts. We show that these concepts are well semantically grounded in both vision and text. Thus we refer to these as “multi-modal concepts”. We qualitatively and quantitatively evaluate the results of the learnt concepts. We show that the extracted multimodal concepts are useful to interpret representations of test samples. Finally, we evaluate the disentanglement between different concepts and the quality of grounding concepts visually and textually.
DiffCut: Catalyzing Zero-Shot Semantic Segmentation with Diffusion Features and Recursive Normalized Cut
Authors: Paul Couairon Mustafa Shukor Jean-Emmanuel Haugeard Matthieu Cord Nicolas Thome/a>
[Paper] [Code] [Project page]
Foundation models have emerged as powerful tools across various domains including language, vision, and multimodal tasks. While prior works have addressed unsupervised image segmentation, they significantly lag behind supervised models. In this paper, we use a diffusion UNet encoder as a foundation vision encoder and introduce DiffCut, an unsupervised zero-shot segmentation method that solely harnesses the output features from the final self-attention block. Through extensive experimentation, we demonstrate that the utilization of these diffusion features in a graph based segmentation algorithm, significantly outperforms previous state-of-the-art methods on zero-shot segmentation. Specifically, we leverage a recursive Normalized Cut algorithm that softly regulates the granularity of detected objects and produces well-defined segmentation maps that precisely capture intricate image details. Our work highlights the remarkably accurate semantic knowledge embedded within diffusion UNet encoders that could then serve as foundation vision encoders for downstream tasks.

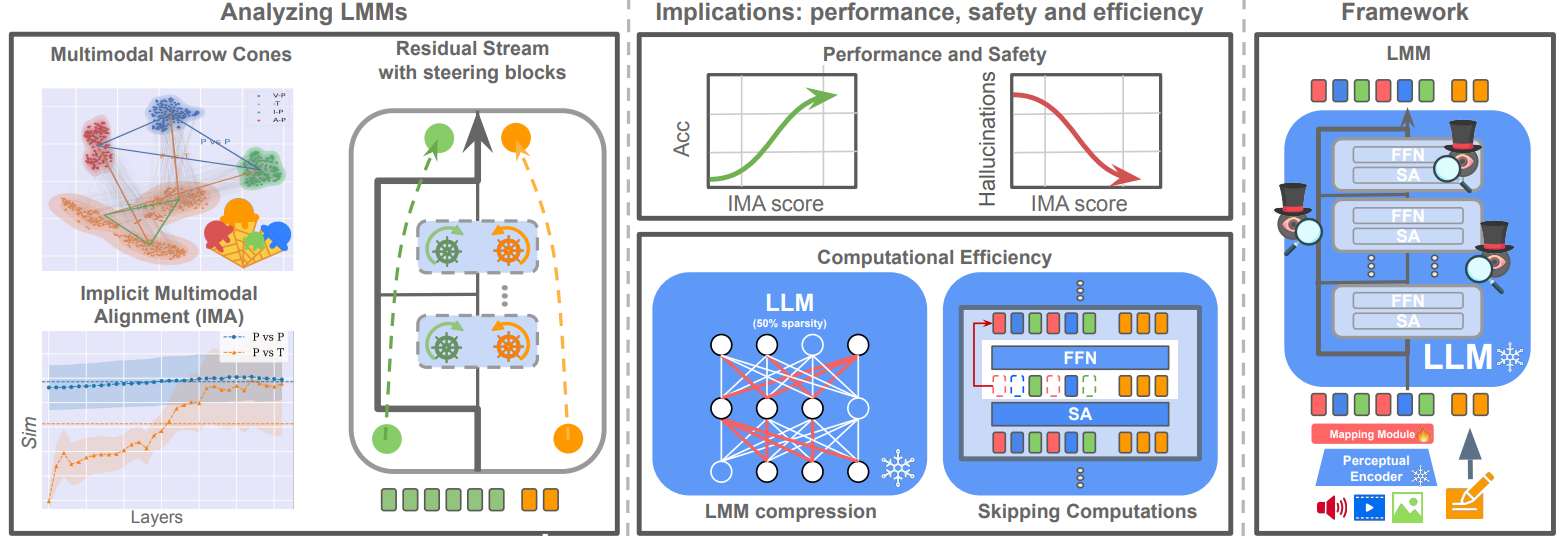
Implicit Multimodal Alignment: On the Generalization of Frozen LLMs to Multimodal Inputs
Authors: Mustafa Shukor Matthieu Cord
[Paper] [Code] [Project page]
Large Language Models (LLMs) have demonstrated impressive performance on multimodal tasks, without any multimodal finetuning. They are the building block for Large Multimodal Models, yet, we still lack a proper understanding of their success. In this work, we expose frozen LLMs to image, video, audio and text inputs and analyse their internal representation aiming to understand their generalization beyond textual inputs. Findings. Perceptual tokens (1) are easily distinguishable from textual ones inside LLMs, with significantly different representations, and complete translation to textual tokens does not exist. Yet, (2) both perceptual and textual tokens activate similar LLM weights. Despite being different, (3) perceptual and textual tokens are implicitly aligned inside LLMs, we call this the implicit multimodal alignment (IMA), and argue that this is linked to architectural design, helping LLMs to generalize. This provide more evidence to believe that the generalization of LLMs to multimodal inputs is mainly due to their architecture. Implications. (1) We find a positive correlation between the implicit alignment score and the task performance, suggesting that this could act as a proxy metric for model evaluation and selection. (2) A negative correlation exists regarding hallucinations, revealing that this problem is mainly due to misalignment between the internal perceptual and textual representations. (3) Perceptual tokens change slightly throughout the model, thus, we propose different approaches to skip computations (e.g. in FFN layers), and significantly reduce the inference cost. (4) Due to the slowly changing embeddings across layers, and the high overlap between textual and multimodal activated weights, we compress LLMs by keeping only 1 subnetwork that works well across a wide range of multimodal tasks.