valeo.ai at ECCV 2024
The European Conference on Computer Vision (ECCV) is a biennial landmark conference for the increasingly large community of researchers in computer vision and machine learning from both academia and industry. At the 2024 edition the valeo.ai team will present five papers in the main conference and four in the workshops. We are also organizing two tutorials (Bayesian Odyssey and Time is precious: Self-Supervised Learning Beyond Images), the Uncertainty Quantification for Computer Vision workshop, a talk at the OmniLabel workshop, and the BRAVO challenge. Our team has also contributed to the reviewing process, with seven reviewers, three area chairs, and two outstanding reviewer awards. The team will be at ECCV to present these works and will be happy to discuss more about these projects and ideas, and share our exciting ongoing research.

Train Till You Drop: Towards Stable and Robust Source-free Unsupervised 3D Domain Adaptation
Authors: Bjoern Michele Alexandre Boulch Tuan-Hung Vu Gilles Puy Renaud Marlet Nicolas Courty
[Paper] [Code] [Project page]
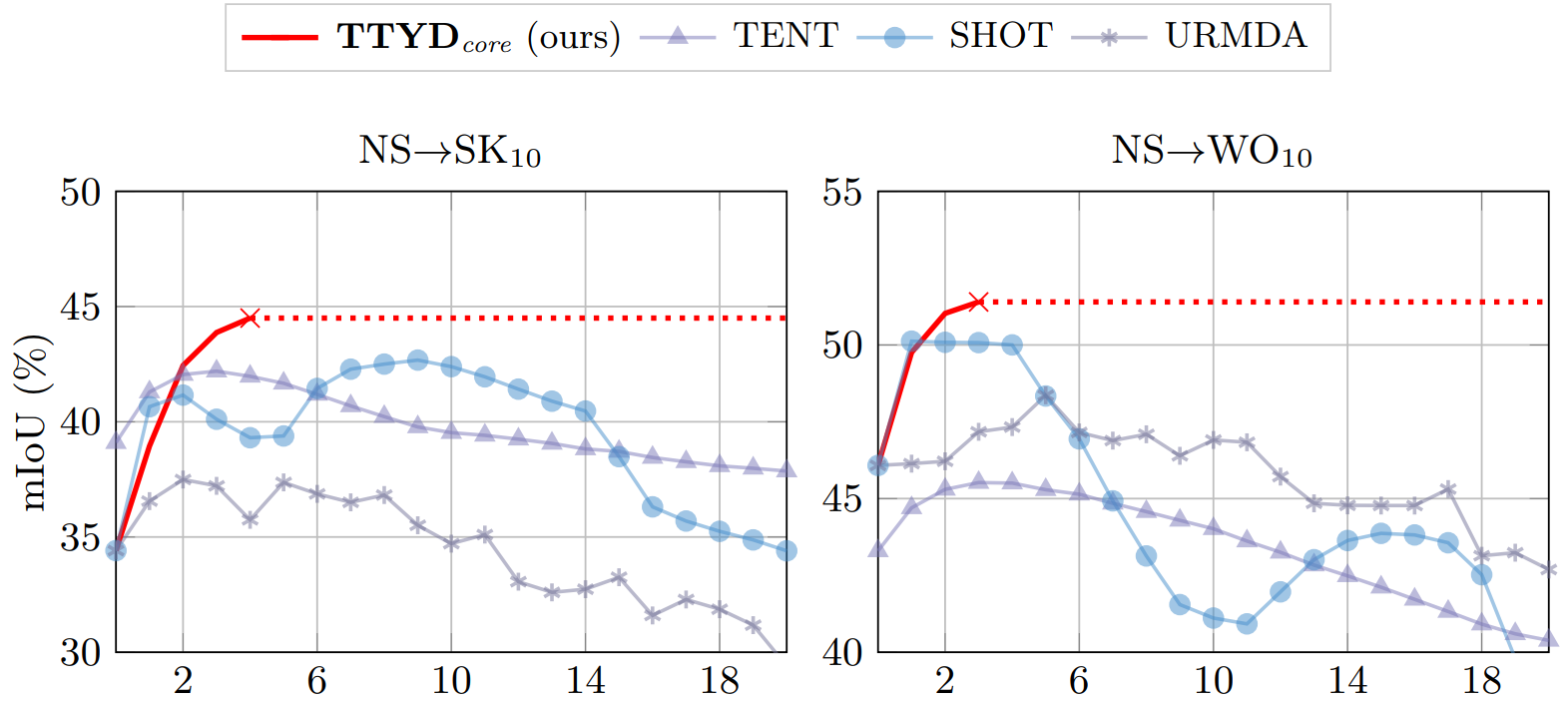
We tackle the challenging problem of source-free unsupervised domain adaptation (SFUDA) for 3D semantic segmentation. It amounts to performing domain adaptation on an unlabeled target domain without any access to source data; the available information is a model trained to achieve good performance on the source domain. A common issue with existing SFUDA approaches is that performance degrades after some training time, which is a by-product of an under-constrained and ill-posed problem. We discuss two strategies to alleviate this issue. First, we propose a sensible way to regularize the learning problem. Second, we introduce a novel criterion based on agreement with a reference model. It is used (1) to stop the training when appropriate and (2) as validator to select hyperparameters without any knowledge on the target domain. Our contributions are easy to implement and readily amenable for all SFUDA methods, ensuring stable improvements over all baselines. We validate our findings on various 3D lidar settings, achieving state-of-the-art performance.
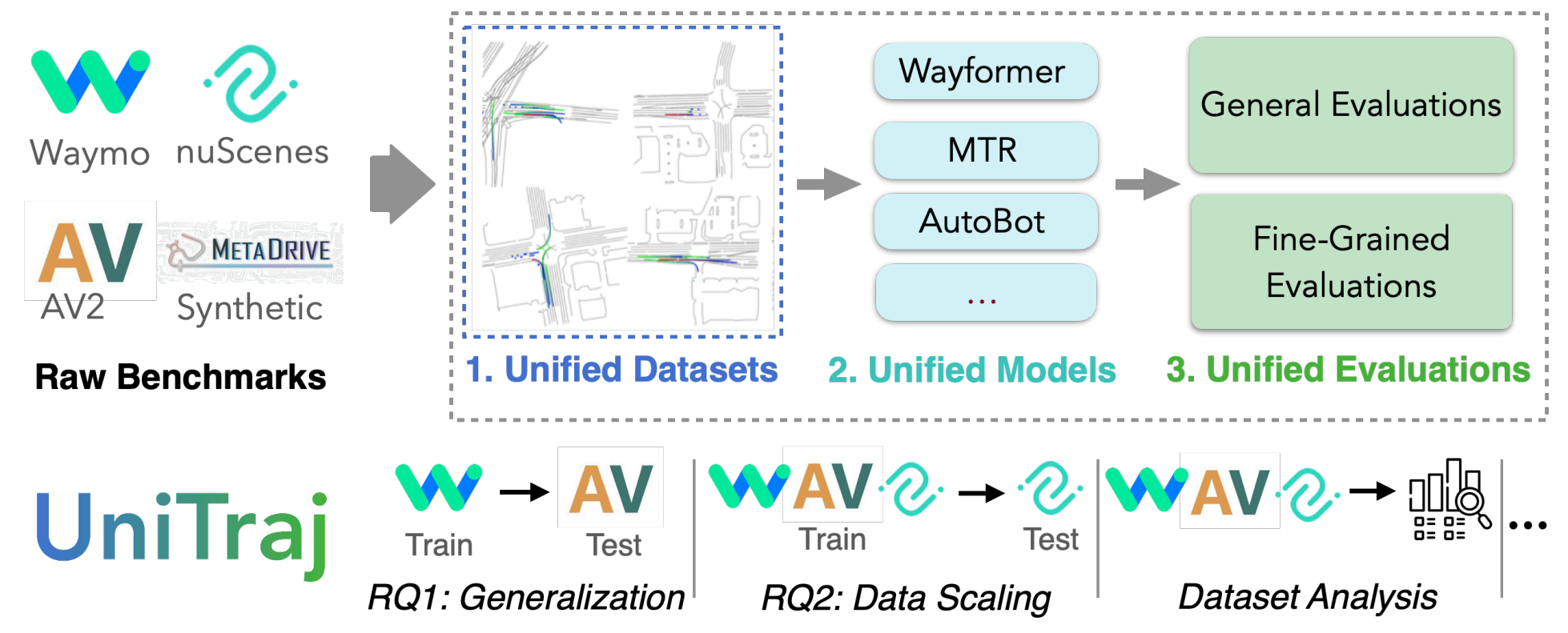
UniTraj: A Unified Framework for Scalable Vehicle Trajectory Prediction
Authors: Lan Feng Mohammadhossein Bahari Kaouther Messaoud Ben Amor Éloi Zablocki Matthieu Cord Alexandre Alahi
[Paper] [Code] [Project page] [Video]
Vehicle trajectory prediction has increasingly relied on data-driven solutions, but their ability to scale to different data domains and the impact of larger dataset sizes on their generalization remain under-explored. While these questions can be studied by employing multiple datasets, it is challenging due to several discrepancies, e.g., in data formats, map resolution, and semantic annotation types. To address these challenges, we introduce UniTraj, a comprehensive framework that unifies various datasets, models, and evaluation criteria, presenting new opportunities for the vehicle trajectory prediction field. In particular, using UniTraj, we conduct extensive experiments and find that model performance significantly drops when transferred to other datasets. However, enlarging data size and diversity can substantially improve performance, leading to a new state-of-the-art result for the nuScenes dataset. We provide insights into dataset characteristics to explain these findings.
Lost and Found: Overcoming Detector Failures in Online Multi-Object Tracking
Authors: Lorenzo Vaquero Yihong Xu Xavier Alameda-Pineda Víctor M. Brea Manuel Mucientes
[Paper] [Code] [Project page]
Multi-object tracking (MOT) endeavors to precisely estimate the positions and identities of multiple objects over time. The prevailing approach, tracking-by-detection (TbD), first detects objects and then links detections, resulting in a simple yet effective method. However, contemporary detectors may occasionally miss some objects in certain frames, causing trackers to cease tracking prematurely. To tackle this issue, we propose BUSCA, meaning ‘to search’, a versatile framework compatible with any online TbD system, enhancing its ability to persistently track those objects missed by the detector, primarily due to occlusions. Remarkably, this is accomplished without modifying past tracking results or accessing future frames, i.e., in a fully online manner. BUSCA generates proposals based on neighboring tracks, motion, and learned tokens. Utilizing a decision Transformer that integrates multimodal visual and spatiotemporal information, it addresses the object-proposal association as a multi-choice question-answering task. BUSCA is trained independently of the underlying tracker, solely on synthetic data, without requiring fine-tuning. Through BUSCA, we showcase consistent performance enhancements across five different trackers and establish a new state-of-the-art baseline across three different benchmarks.

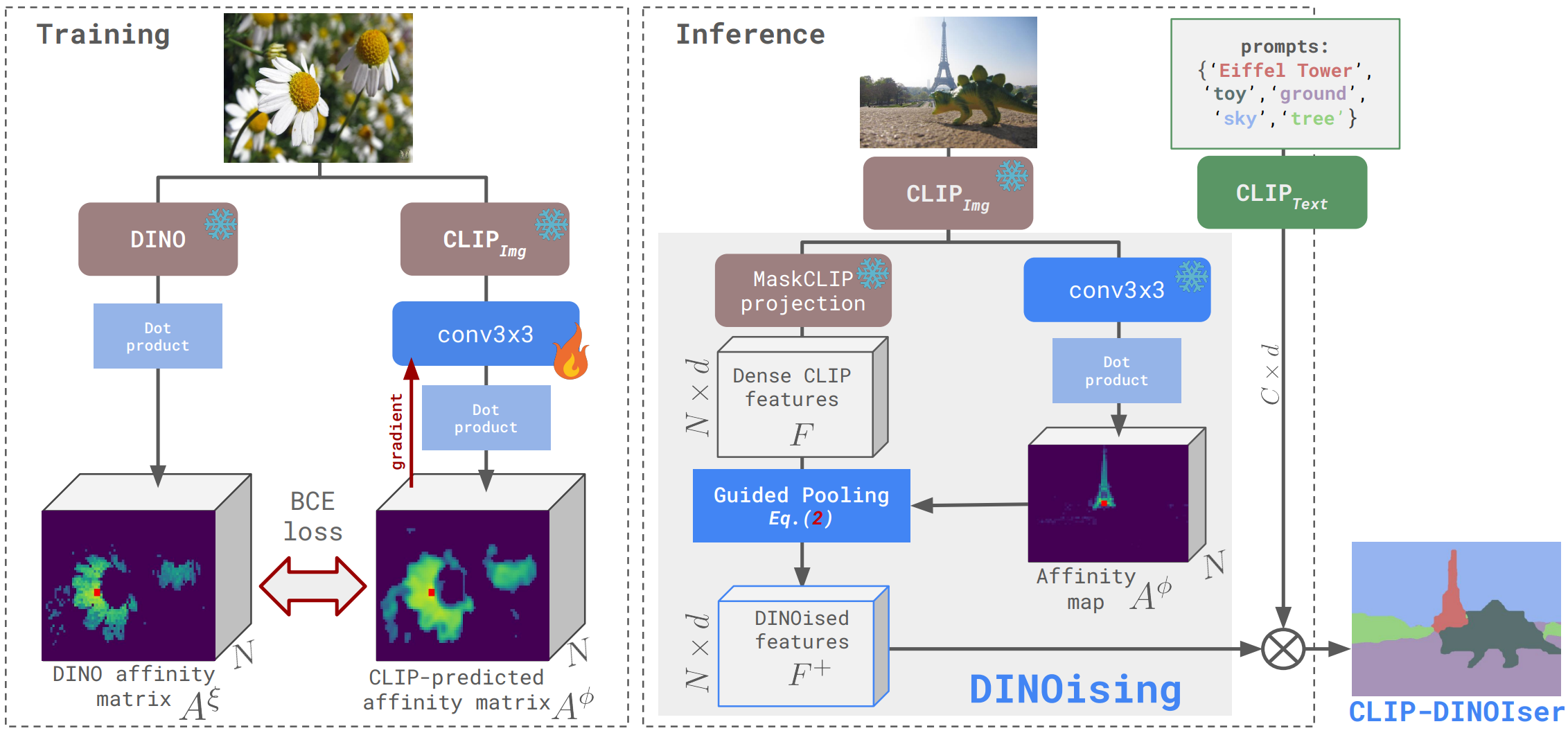
CLIP-DINOiser: Teaching CLIP a few DINO tricks for open-vocabulary semantic segmentation
Authors: Monika Wysoczańska Oriane Siméoni Michaël Ramamonjisoa Andrei Bursuc Tomasz Trzciński Patrick Pérez
[Paper] [Code] [Project page]
The popular CLIP model displays impressive zero-shot capabilities thanks to its seamless interaction with arbitrary text prompts. However, its lack of spatial awareness makes it unsuitable for dense computer vision tasks, e.g., semantic segmentation, without an additional fine-tuning step that often uses annotations and can potentially suppress its original open-vocabulary properties. Meanwhile, self-supervised representation methods have demonstrated good localization properties without human-made annotations nor explicit supervision. In this work, we take the best of both worlds and propose an open-vocabulary semantic segmentation method, which does not require any annotations.

We propose to locally improve dense MaskCLIP features, which are computed with a simple modification of CLIP’s last pooling layer, by integrating localization priors extracted from self-supervised features from DINO. By doing so, we greatly improve the performance of MaskCLIP and produce smooth outputs. Moreover, we show that the used self-supervised feature properties can directly be learnt from CLIP features. Our method CLIP-DINOiser needs only a single forward pass of CLIP and two light convolutional layers at inference, no extra supervision nor extra memory and reaches state-of-the-art results on challenging and fine-grained benchmarks such as COCO, Pascal Context, Cityscapes and ADE20k.
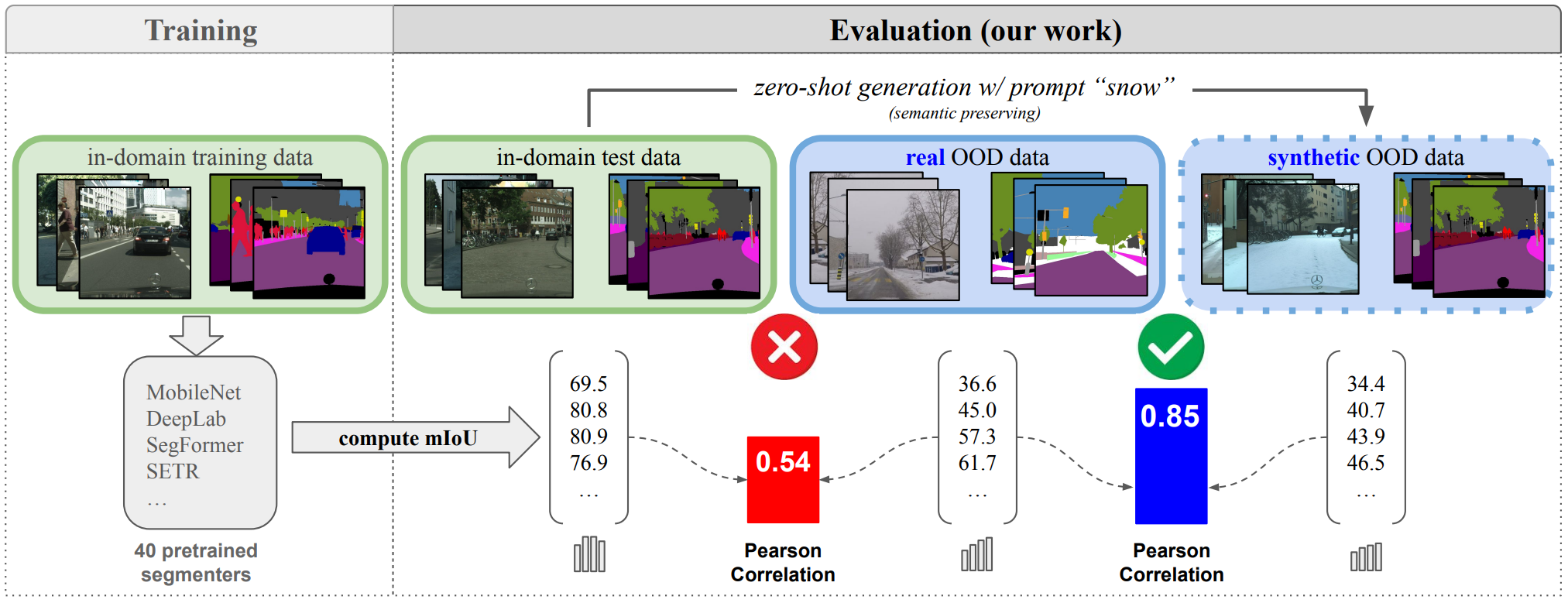
Reliability in Semantic Segmentation: Can We Use Synthetic Data
Authors: Thibaut Loiseau Tuan-Hung Vu Mickael Chen Patrick Pérez Matthieu Cord
[Paper] [Code] [Project page]
Assessing the reliability of perception models to covariate shifts and out-of-distribution (OOD) detection is crucial for safety-critical applications such as autonomous vehicles. By nature of the task, however, the relevant data is difficult to collect and annotate. In this paper, we challenge cutting-edge generative models to automatically synthesize data for assessing reliability in semantic segmentation. By fine-tuning Stable Diffusion, we perform zero-shot generation of synthetic data in OOD domains or inpainted with OOD objects. Synthetic data is employed to provide an initial assessment of pretrained segmenters, thereby offering insights into their performance when confronted with real edge cases. Through extensive experiments, we demonstrate a high correlation between the performance on synthetic data and the performance on real OOD data, showing the validity approach. Furthermore, we illustrate how synthetic data can be utilized to enhance the calibration and OOD detection capabilities of segmenters.
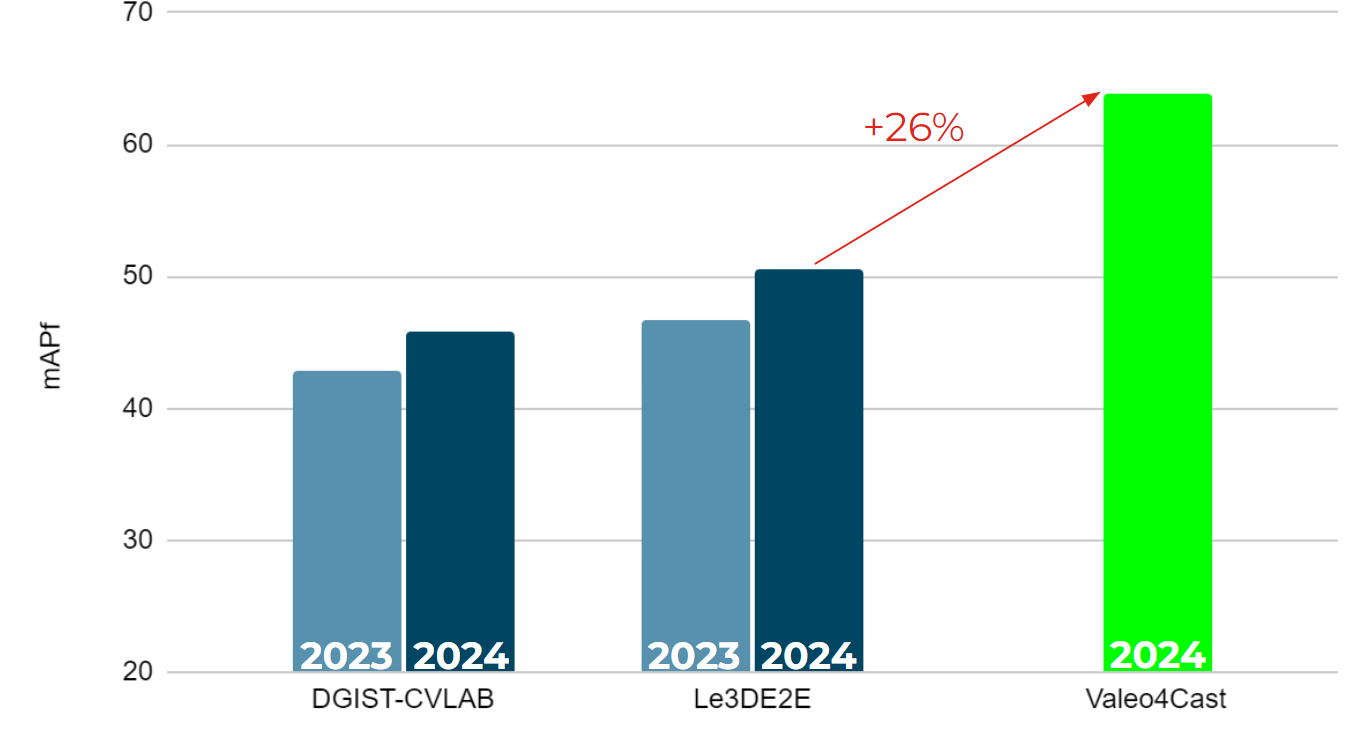
Valeo4Cast: A Modular Approach to End-to-End Forecasting
Winning solution in Argoverse 2 Unified Detection, Tracking and Forecasting Challenge
Authors: Yihong Xu, Éloi Zablocki, Alexandre Boulch, Gilles Puy, Mickaël Chen, Florent Bartoccioni, Nermin Samet, Oriane Siméoni, Spyros Gidaris, Tuan-Hung Vu, Andrei Bursuc, Eduardo Valle, Renaud Marlet, Matthieu Cord
[Paper] [leaderboard] [page]
Motion forecasting is crucial in autonomous driving systems to anticipate the future trajectories of surrounding agents such as pedestrians, vehicles, and traffic signals. In end-to-end forecasting, the model must jointly detect from sensor data (cameras or LiDARs) the position and past trajectories of the different elements of the scene and predict their future location. We depart from the current trend of tackling this task via end-to-end training from perception to forecasting and we use a modular approach instead. Following a recent study, we individually build and train detection, tracking, and forecasting modules. We then only use consecutive finetuning steps to integrate the modules better and alleviate compounding errors. Our study reveals that this simple yet effective approach significantly improves performance on the end-to-end forecasting benchmark. Consequently, our solution ranks first in the Argoverse 2 end-to-end Forecasting Challenge held at CVPR 2024 Workshop on Autonomous Driving (WAD), with 63.82 mAPf. We surpass forecasting results by +17.1 points over last year’s winner and by +13.3 points over this year’s runner-up. This remarkable performance in forecasting can be explained by our modular paradigm, which integrates finetuning strategies and significantly outperforms the end-to-end-trained counterparts.
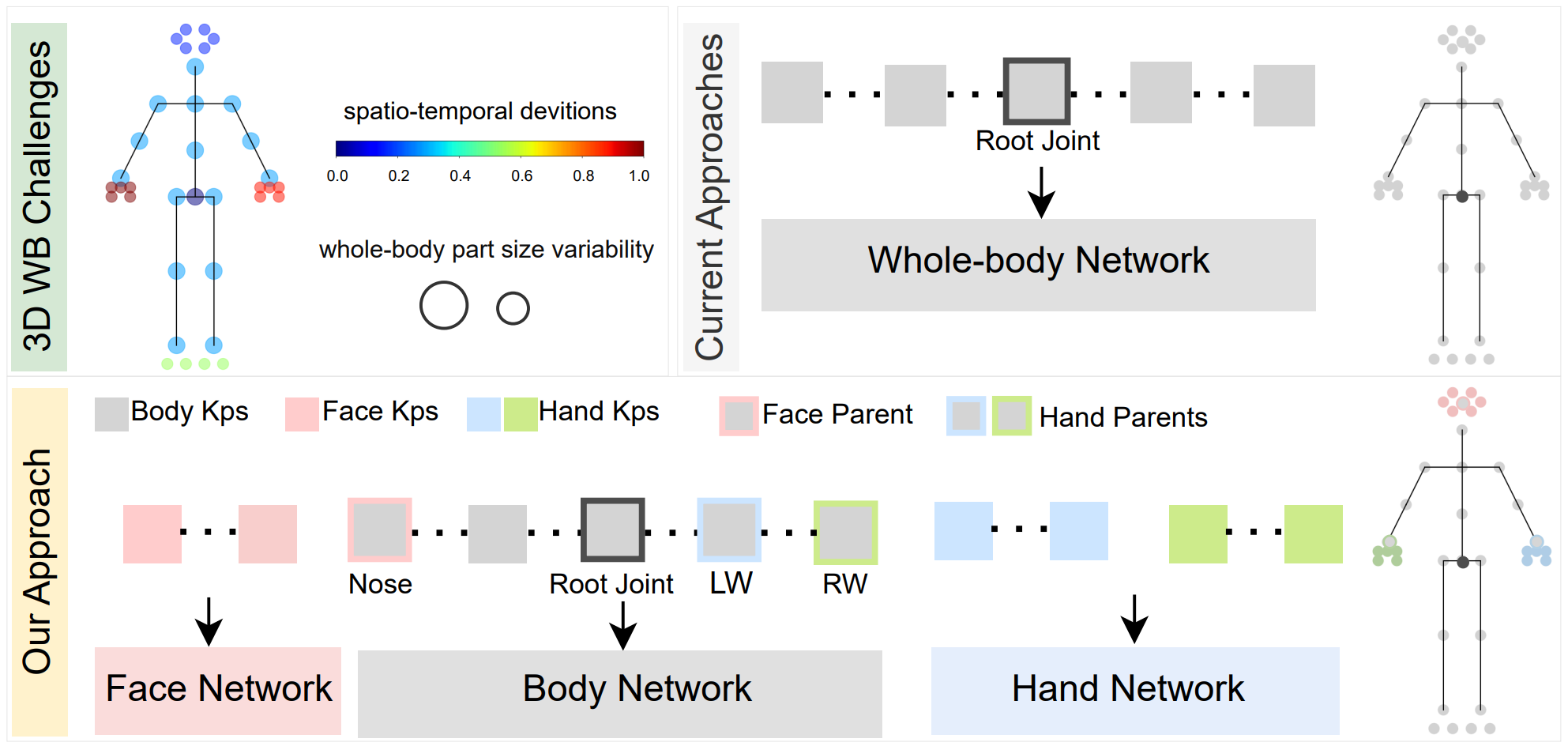
PAFUSE: Part-based Diffusion for 3D Whole-Body Pose Estimation
ECCV 2024 Workshop Towards a Complete Analysis of People (T-CAP)
Authors: Nermin Samet Cédric Rommel David Picard Eduardo Valle
[Paper] [Code] [Project page]
We introduce a novel approach for 3D whole-body pose estimation, addressing the challenge of scale- and deformability- variance across body parts brought by the challenge of extending the 17 major joints on the human body to fine-grained keypoints on the face and hands. In addition to addressing the challenge of exploiting motion in unevenly sampled data, we combine stable diffusion to a hierarchical part representation which predicts the relative locations of fine-grained keypoints within each part (e.g., face) with respect to the part’s local reference frame. On the H3WB dataset, our method greatly outperforms the current state of the art, which fails to exploit the temporal information. We also show considerable improvements compared to other spatiotemporal 3D human-pose estimation approaches that fail to account for the body part specificities.
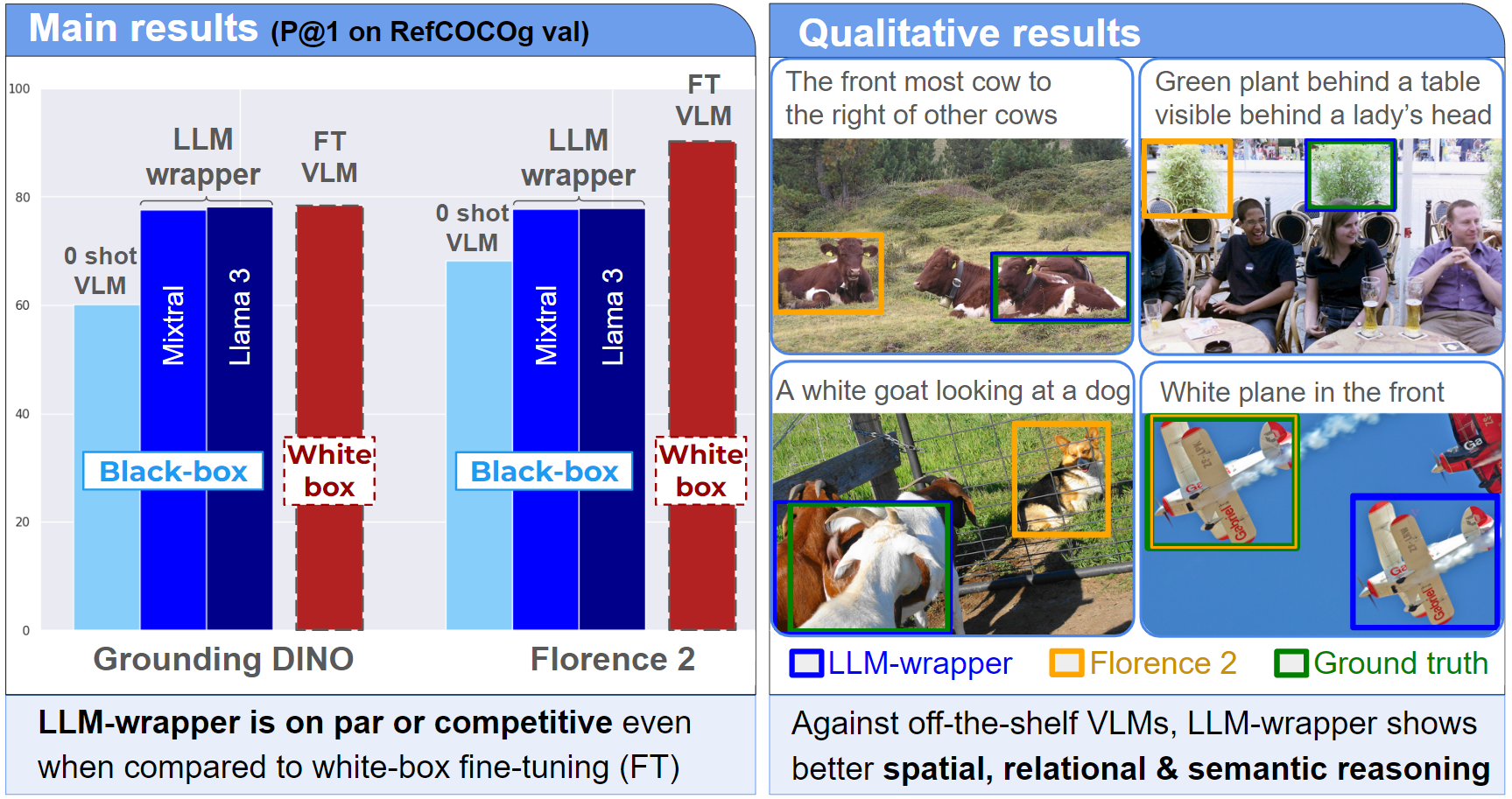
LLM-wrapper: Black-Box Semantic-Aware Adaptation of Vision-Language Foundation Models
ECCV 2024 Workshop on Emergent Visual Abilities and Limits of Foundation Models (Eval-FoMo)
Authors: Amaia Cardiel Éloi Zablocki Oriane Siméoni Elias Ramzi Matthieu Cord
[Paper] [Project page]
Vision Language Models (VLMs) have shown impressive performances on numerous tasks but their zero-shot capabilities can be limited compared to dedicated or fine-tuned models. Yet, fine-tuning VLMs comes with strong limitations as it requires a ‘white-box’ access to the model’s architecture and weights while some recent models are proprietary (e.g., Grounding DINO 1.5). It also requires expertise to design the fine-tuning objectives and optimize the hyper-parameters, which are specific to each VLM and downstream task. In this work, we propose LLM-wrapper, a novel approach to adapt VLMs in a ‘black-box’ and semantic-aware manner by leveraging large language models (LLMs) so as to reason on their outputs.

We demonstrate the effectiveness of LLM-wrapper on Referring Expression Comprehension (REC), a challenging open-vocabulary task that requires spatial and semantic reasoning. Our approach significantly boosts the performance of off-the-shelf models, yielding results that are on par or competitive when compared with classic VLM fine-tuning (cf ‘FT VLM’ in our main results). Despite a few failure cases due to the LLM ‘blindness’ (cf Qualitative results, bottom right)), LLM-wrapper shows better semantic, spatial and relational reasoning, as illustrated in our qualitative results below.
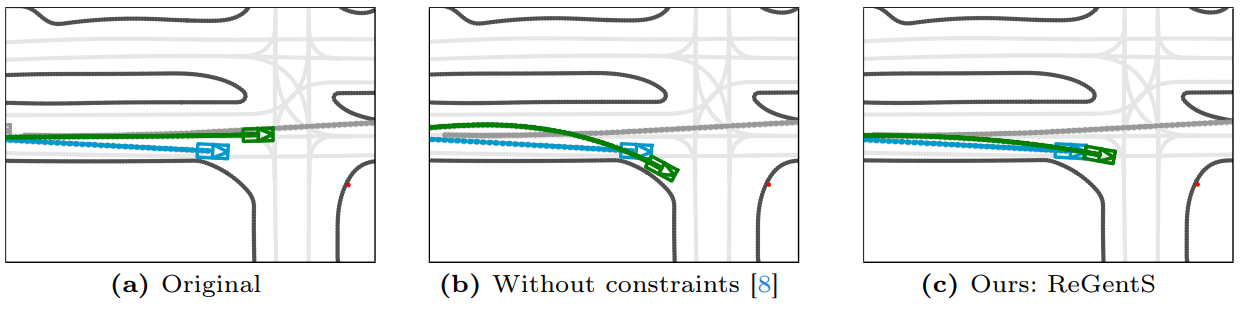
ReGentS: Real-World Safety-Critical Driving Scenario Generation Made Stable
Authors: Yuan Yin Pegah Khayatan Éloi Zablocki Alexandre Boulch Matthieu Cord
[Paper] [Project page]
Machine learning based autonomous driving systems often face challenges with safety-critical scenarios that are rare in real-world data, hindering their large-scale deployment. While increasing real-world training data coverage could address this issue, it is costly and dangerous. This work explores generating safety-critical driving scenarios by modifying complex real-world regular scenarios through trajectory optimization. We propose ReGentS, which stabilizes generated trajectories and introduces heuristics to avoid obvious collisions and optimization problems. Our approach addresses unrealistic diverging trajectories and unavoidable collision scenarios that are not useful for training robust planner. We also extend the scenario generation framework to handle real-world data with up to 32 agents. Additionally, by using a differentiable simulator, our approach simplifies gradient descent-based optimization involving a simulator, paving the way for future advancements.
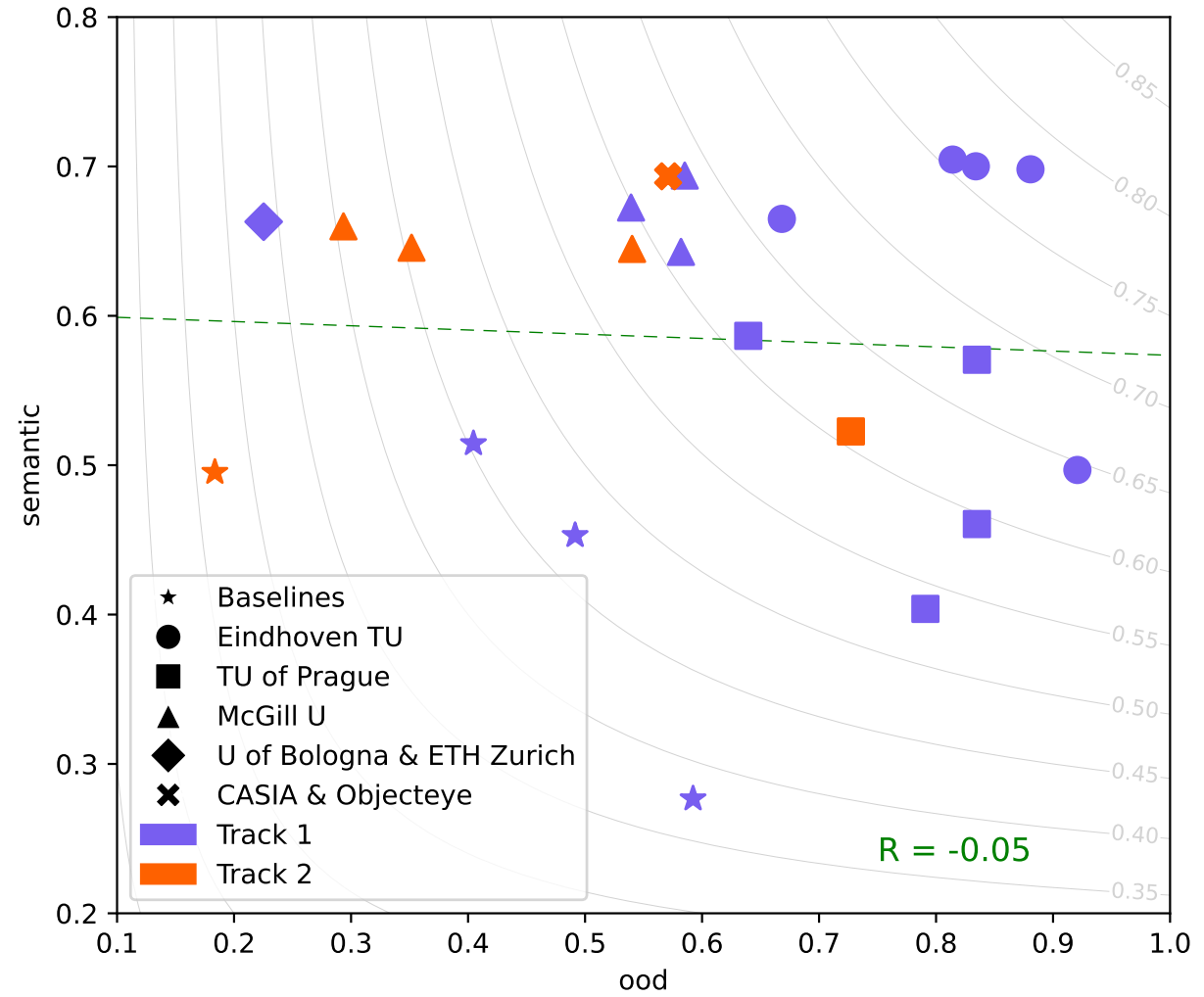
The BRAVO Semantic Segmentation Challenge Results in UNCV2024
ECCV 2024 Workshop on Uncertainty Quantification for Computer Vision
Authors: Tuan-Hung Vu Eduardo Valle Andrei Bursuc Tommie Kerssies Daan de Geus Gijs Dubbelman Long Qian Bingke Zhu Yingying Chen Ming Tang Jinqiao Wang Tomáš Vojíř Jan Šochman Jiří Matas Michael Smith Frank Ferrie Shamik Basu Christos Sakaridis Luc Van Gool
[Paper] [Code] [Project page]
We propose the unified BRAVO challenge to benchmark the reliability of semantic segmentation models under realistic perturbations and unknown out-of-distribution (OOD) scenarios. We define two categories of reliability: (1) semantic reliability, which reflects the model’s accuracy and calibration when exposed to various perturbations; and (2) OOD reliability, which measures the model’s ability to detect object classes that are unknown during training. The challenge attracted nearly 100 submissions from international teams representing notable research institutions. The results reveal interesting insights into the importance of large-scale pre-training and minimal architectural design in developing robust and reliable semantic segmentation models.