valeo.ai at CVPR 2024
The IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR) is a key event for researchers and engineers working on computer vision and machine learning. At the 2024 edition the valeo.ai team will present eight papers in the main conference, two papers in workshops, and one workshop keynote. Also, the team will present its winning solution to the Argoverse 2 “Unified Detection, Tracking and Forecasting” challenge held at the Workshop on Autonomous Driving. The team will be at CVPR to present these works and will be happy to discuss more about these projects and ideas, and share our exciting ongoing research. We outline our team papers below.

Three Pillars Improving Vision Foundation Model Distillation for Lidar
Authors: Gilles Puy, Spyros Gidaris, Alexandre Boulch, Oriane Siméoni, Corentin Sautier, Andrei Bursuc, Patrick Pérez, Renaud Marlet
[Paper] [Code] [Video] [Project page]
Self-supervised image backbones can be used to address complex 2D tasks (e.g., semantic segmentation, object discovery) very efficiently and with little or no downstream supervision. Ideally, 3D backbones for lidar should be able to inherit these properties after distillation of these powerful 2D features. The most recent methods for image-to-lidar distillation on autonomous driving data show promising results, obtained thanks to distillation methods that keep improving. Yet, we still notice a large performance gap when measuring by linear probing the quality of distilled vs fully supervised features.
In this work, instead of focusing only on the distillation method, we study the effect of three pillars for distillation: the 3D backbone, the pretrained 2D backbone, and the pretraining 2D+3D dataset. In particular, thanks to our scalable distillation method named ScaLR, we show that scaling the 2D and 3D backbones and pretraining on diverse datasets leads to a substantial improvement of the feature quality. This allows us to significantly reduce the gap between the quality of distilled and fully-supervised 3D features, and to improve the robustness of the pretrained backbones to domain gaps and perturbations. We show that scaling the 2D and 3D backbones, and pretraining on diverse datasets leads to considerable improvements of the feature quality. The role of these pillars is actually more important than the distillation method itself, which we simplify for easier scaling.
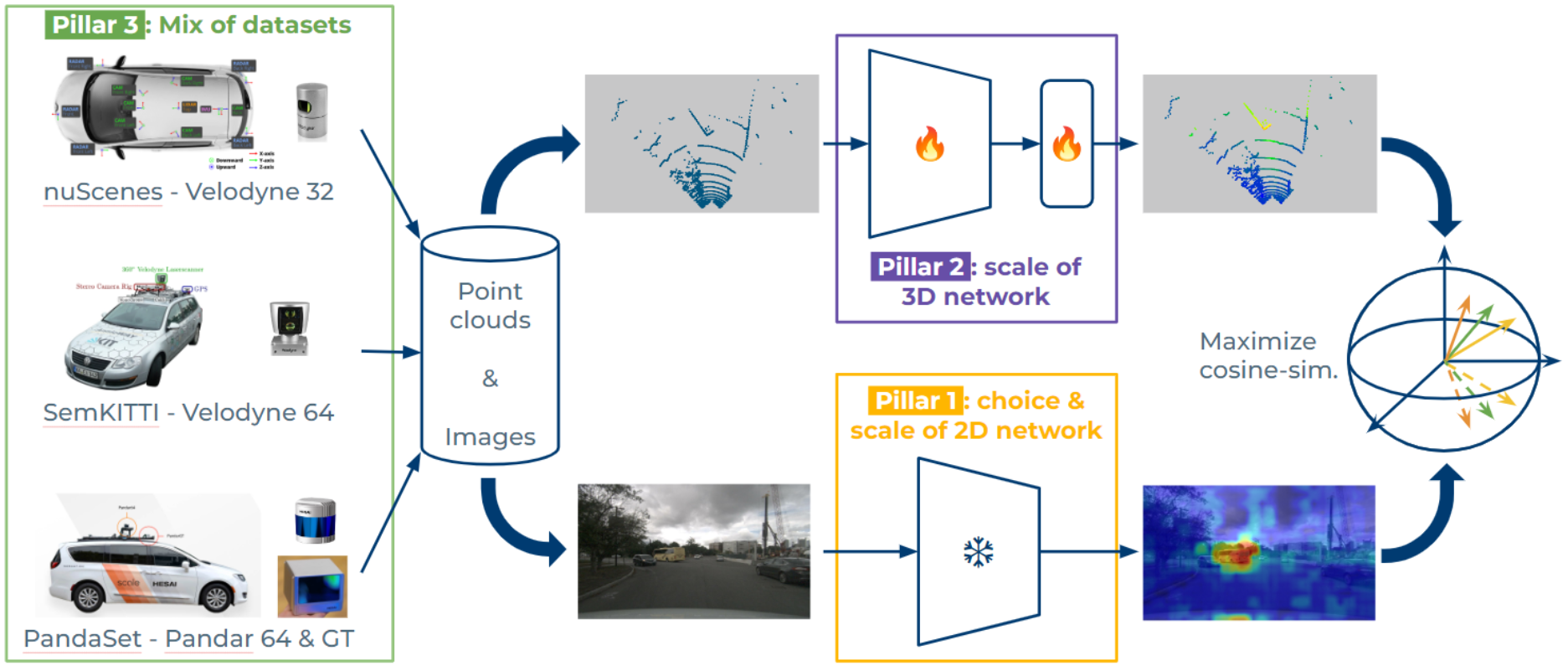
In this work, after proposing and studying a scalable distillation method, which we call ScaLR for Scalable Lidar Representation (see Figure above), we make the following contributions.
First, we are able to significantly reduce the gap between distilled and supervised lidar representations: on nuScenes, we increase the performance by 22.8 mIoU percentage points compared to the former best distillation method.
Second, we show it is possible to pretrain a single backbone on a mixture of datasets, performing similarly or better than separate backbones specialized on each dataset individually. The capacity of this backbone in providing good features across multiple datasets is illustrated in the figure below. For each scene in this figure, we pick a point located on a car and present the feature correlation map with respect to this point. We notice that the most correlated points also belong to cars on all datasets, illustrating the capacity of our single pretrained backbone to correctly distinguish objects on multiple datasets.

Third, we thoroughly study the properties of our distilled features. We show that they are robust to both domain gaps and perturbations. We also show that pretraining on diverse datasets improves robustness.
Finally, we show that a possible way to get even better features is to distill the knowledge from multiple vision foundation models at the same time, which can be easily done with our scalable distillation strategy
PointBeV: A Sparse Approach to BeV Predictions
Authors: Loïck Chambon, Éloi Zablocki, Mickaël Chen, Florent Bartoccioni, Patrick Pérez, Matthieu Cord
[Paper] [Code] [Project page]
Bird’s-eye View (BeV) representations have emerged as the de-facto shared space in driving applications, offering a unified space for sensor data fusion and supporting various downstream tasks. However, conventional models use grids with fixed resolution and range and face computational inefficiencies due to the uniform allocation of resources across all cells. To address this, we propose PointBeV, a novel sparse BeV segmentation model operating on sparse BeV cells instead of dense grids. This approach offers precise control over memory usage, enabling the use of long temporal contexts and accommodating memory-constrained platforms. PointBeV employs an efficient two-pass strategy for training, enabling focused computation on regions of interest. At inference time, it can be used with various memory/performance trade-offs and flexibly adjusts to new specific use cases.
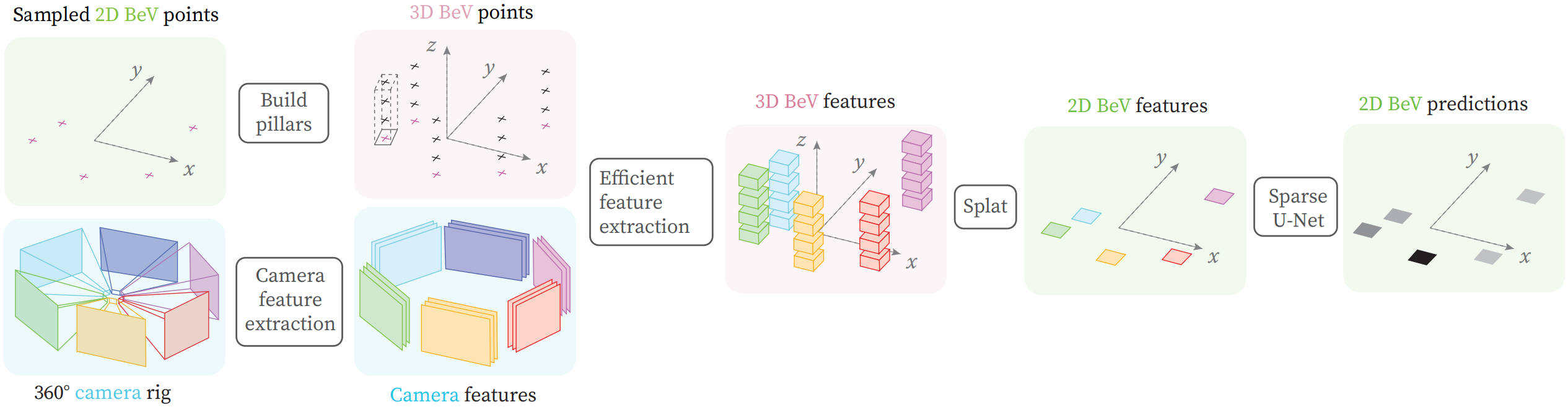
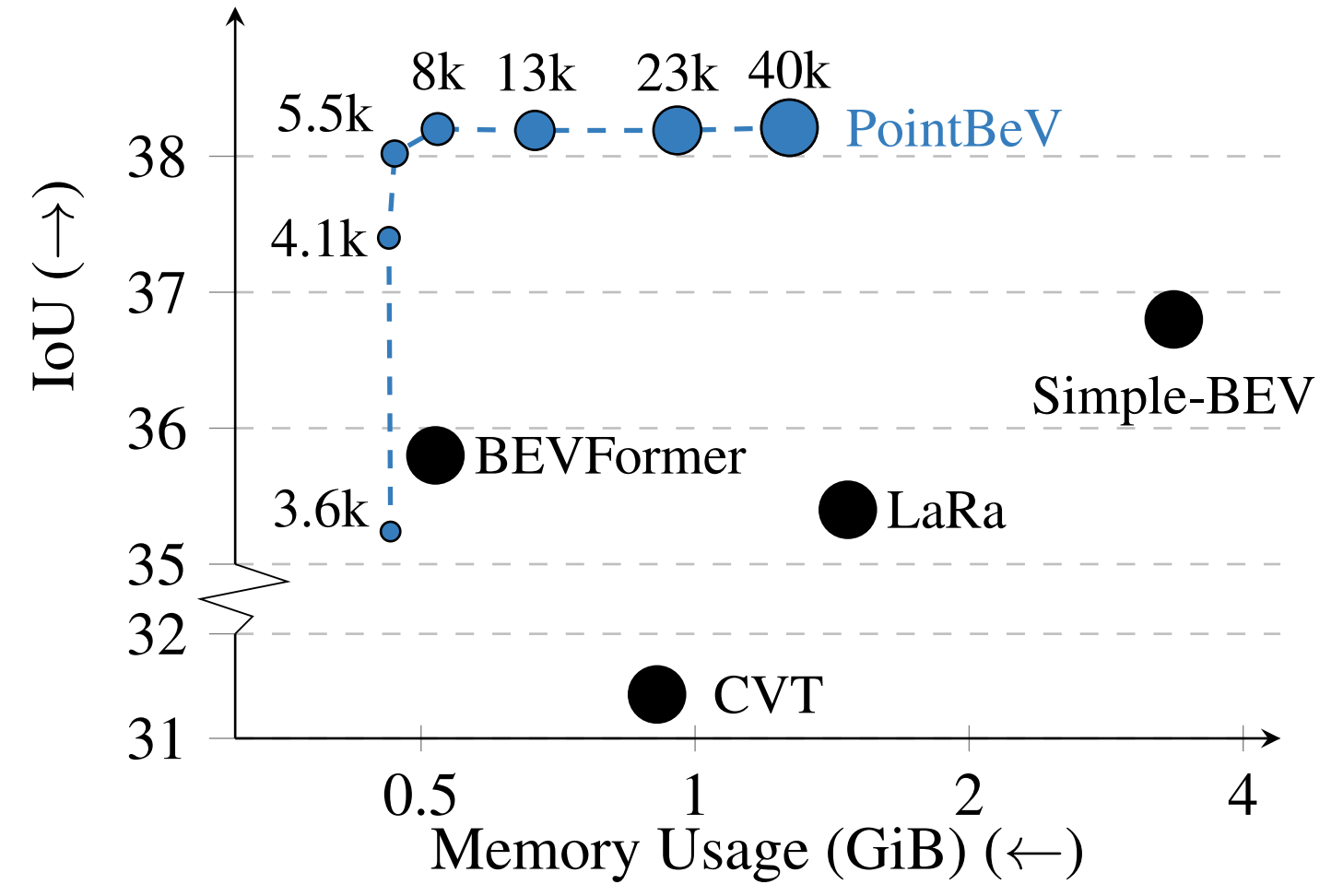
PointBeV achieves state-of-the-art results on the nuScenes dataset for vehicle, pedestrian, and lane segmentation, showcasing superior performance in static and temporal settings despite being trained solely with sparse signals. We will release our code along with two new efficient modules used in the architecture: Sparse Feature Pulling, designed for the effective extraction of features from images to BeV, and Submanifold Attention, which enables efficient temporal modeling.
Don’t drop your samples! Coherence-aware training benefits Conditional diffusion
Highlight
Authors: Nicolas Dufour , Victor Besnier, Vicky Kalogeiton, David Picard
[Paper] [Code] [Video] [Project page]
Conditional diffusion models are powerful generative models that can leverage various types of conditional information, such as class labels, segmentation masks, or text captions. However, in many real-world scenarios, conditional information may be noisy or unreliable due to human annotation errors or weak alignment. In this paper, we propose the Coherence-Aware Diffusion (CAD), a novel method that integrates coherence in conditional information into diffusion models, allowing them to learn from noisy annotations without discarding data. We assume that each data point has an associated coherence score that reflects the quality of the conditional information. We then condition the diffusion model on both the conditional information and the coherence score. In this way, the model learns to ignore or discount the conditioning when the coherence is low. We show that CAD is theoretically sound and empirically effective on various conditional generation tasks. Moreover, we show that leveraging coherence generates realistic and diverse samples that respect conditional information better than models trained on cleaned datasets where samples with low coherence have been discarded.

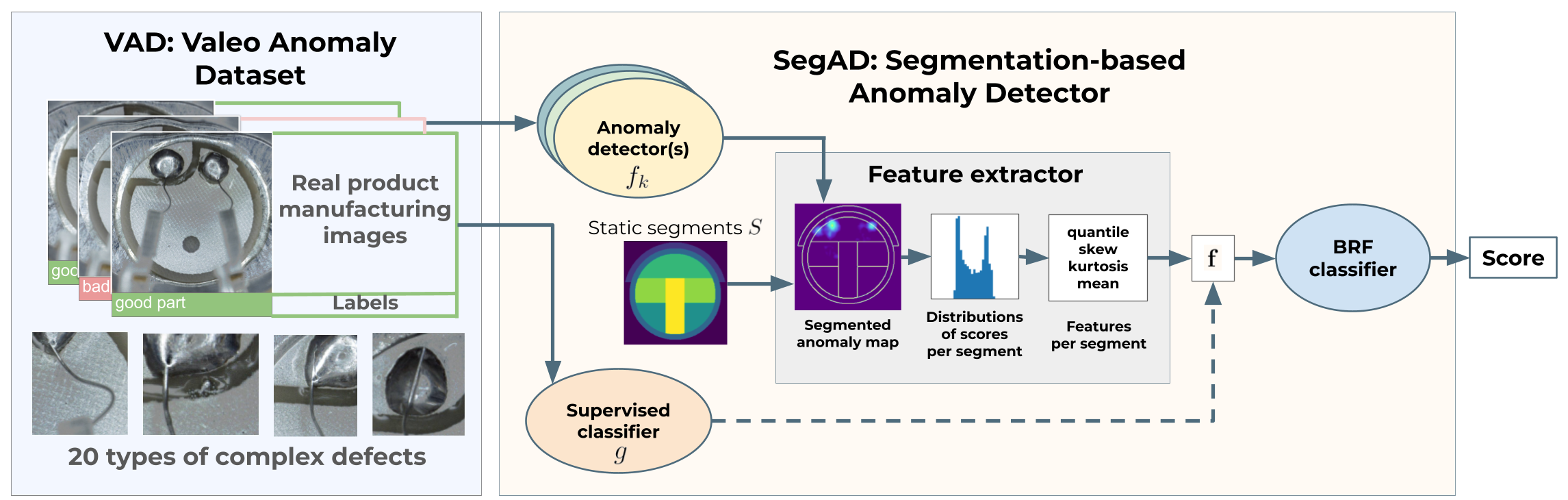
Supervised Anomaly Detection for Complex Industrial Images
Authors: Aimira Baitieva , David Hurych, Victor Besnier, Olivier Bernard
[Paper] [Code] [Project page]
Automating visual inspection in industrial production lines is essential for increasing product quality across various industries. Anomaly detection (AD) methods serve as robust tools for this purpose. However, existing public datasets primarily consist of images without anomalies, limiting the practical application of AD methods in production settings. To address this challenge, we present (1) the Valeo Anomaly Dataset (VAD), a novel real-world industrial dataset comprising 5000 images, including 2000 instances of challenging real defects across more than 20 subclasses. Acknowledging that traditional AD methods struggle with this dataset, we introduce (2) Segmentation based Anomaly Detector (SegAD). First, SegAD leverages anomaly maps as well as segmentation maps to compute local statistics. Next, SegAD uses these statistics and an optional supervised classifier score as input features for a Boosted Random Forest (BRF) classifier, yielding the final anomaly score. Our SegAD achieves state-of-the-art performance on both VAD (+2.1% AUROC) and the VisA dataset (+0.4% AUROC). The code and the models are publicly available
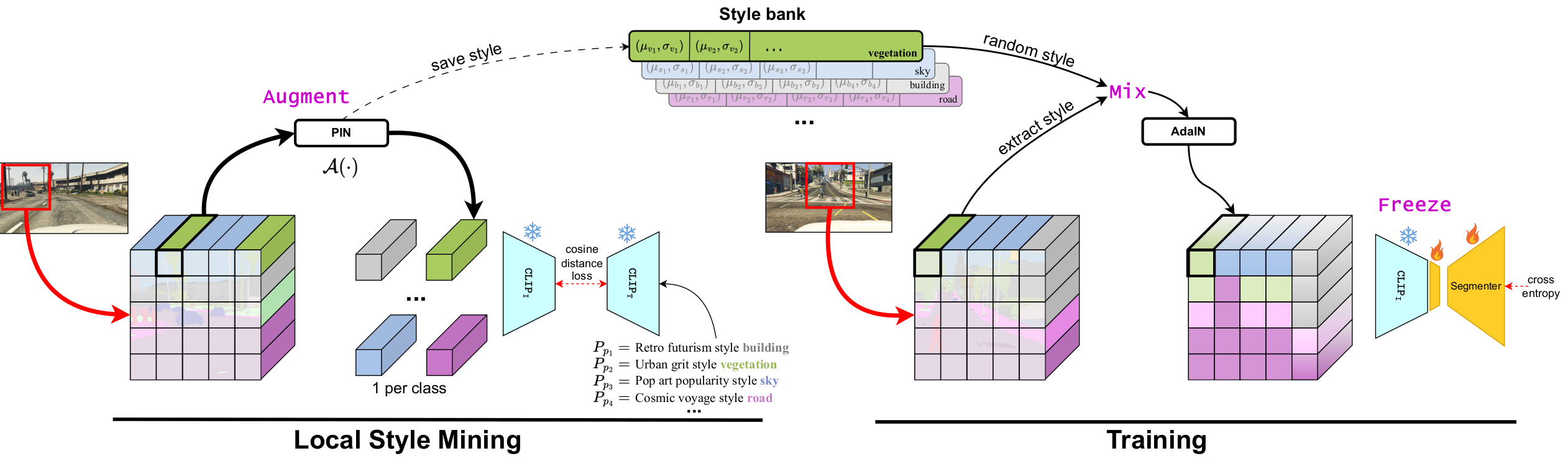
A Simple Recipe for Language-guided Domain Generalized Segmentation
Authors: Mohammad Fahes, Tuan-Hung Vu, Andrei Bursuc, Patrick Pérez, Raoul de Charette
[Paper] [Code] [Video] [page]
Generalization to new domains not seen during training is one of the long-standing goals and challenges in deploying neural networks in real-world applications. Existing generalization techniques necessitate substantial data augmentation, potentially sourced from external datasets, and aim at learning invariant representations by imposing various alignment constraints. Large-scale pretraining has recently shown promising generalization capabilities, along with the potential of bridging different modalities. For instance, the recent advent of vision-language models like CLIP has opened the doorway for vision models to exploit the textual modality. In this paper, we introduce a simple framework for generalizing semantic segmentation networks by employing language as the source of randomization. Our recipe comprises three key ingredients: i) the preservation of the intrinsic CLIP robustness through minimal fine-tuning, ii) language-driven local style augmentation, and iii) randomization by locally mixing the source and augmented styles during training. Extensive experiments report state-of-the-art results on various generalization benchmarks.

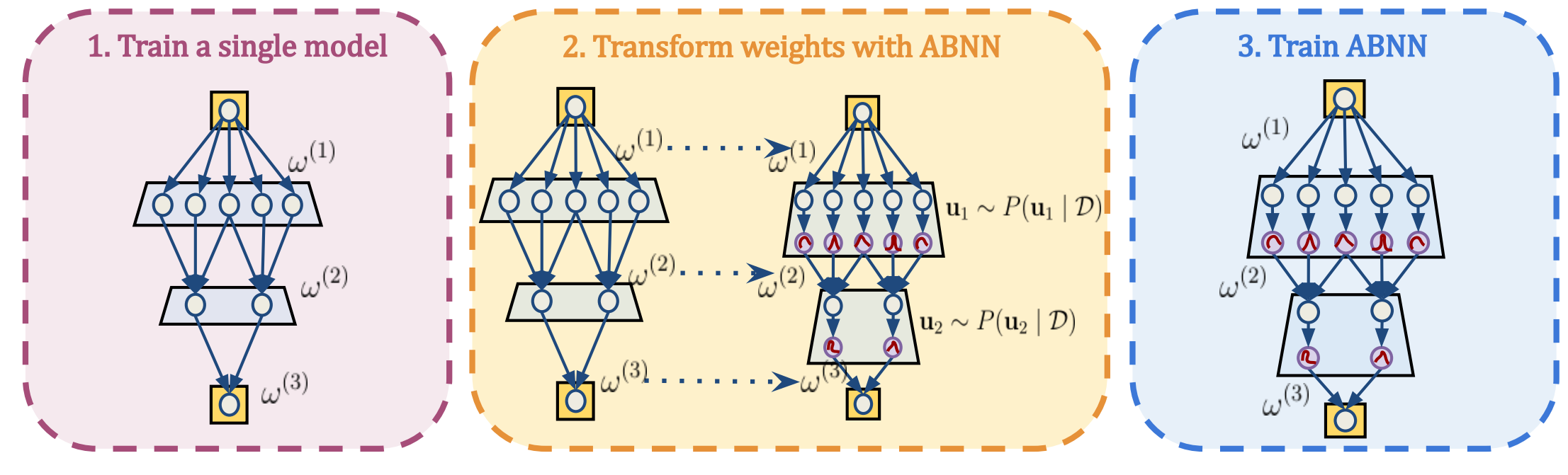
Make Me a BNN: A Simple Strategy for Estimating Bayesian Uncertainty from Pre-trained Models
Authors: Gianni Franchi, Olivier Laurent, Maxence Leguéry, Andrei Bursuc, Andrea Pilzer, Angela Yao
[Paper] [Code] [Video] [page]
Deep Neural Networks (DNNs) are powerful tools for various computer vision tasks, yet they often struggle with reliable uncertainty quantification — a critical requirement for real-world applications. Bayesian Neural Networks (BNN) are equipped for uncertainty estimation but cannot scale to large DNNs where they are highly unstable to train. To address this challenge, we introduce the Adaptable Bayesian Neural Network (ABNN), a simple and scalable strategy to seamlessly transform DNNs into BNNs in a post-hoc manner with minimal computational and training overheads. ABNN preserves the main predictive properties of DNNs while enhancing their uncertainty quantification abilities through simple BNN adaptation layers (attached to normalization layers) and a few fine-tuning steps on pre-trained models. We conduct extensive experiments across multiple datasets for image classification and semantic segmentation tasks, and our results demonstrate that ABNN achieves state-of-the-art performance without the computational budget typically associated with ensemble methods.
SPOT: Self-Training with Patch-Order Permutation for Object-Centric Learning with Autoregressive Transformers
Highlight
Authors: Ioannis Kakogeorgiou, Spyros Gidaris, Konstantinos Karantzalos, Nikos Komodakis
[Paper] [Code] [page]
Unsupervised object-centric learning aims to decompose scenes into interpretable object entities, termed slots. Slot-based auto-encoders stand out as a prominent method for this task. Within them, crucial aspects include guiding the encoder to generate object-specific slots and ensuring the decoder utilizes them during reconstruction. This work introduces two novel techniques, (i) an attention-based self-training approach, which distills superior slot-based attention masks from the decoder to the encoder, enhancing object segmentation , and (ii) an innovative patch-order permutation strategy for autoregressive transformers that strengthens the role of slot vectors in reconstruction.
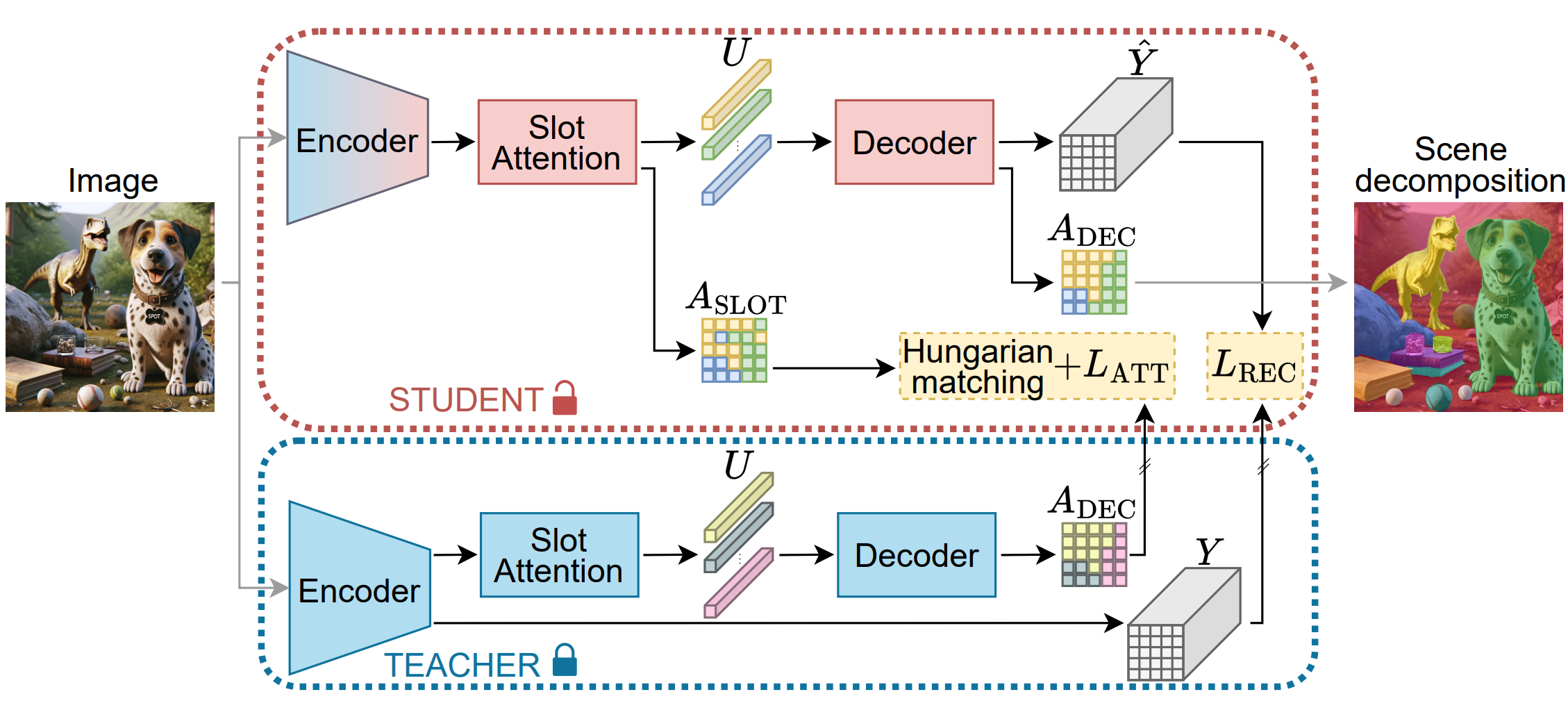
The effectiveness of these strategies is showcased experimentally. The combined approach significantly surpasses prior slot-based autoencoder methods in unsupervised object segmentation, especially with complex real-world images.

NOPE: Novel Object Pose Estimation from a Single Image
Authors: Van Nguyen Nguyen, Thibault Groueix, Georgy Ponimatkin, Yinlin Hu, Renaud Marlet, Mathieu Salzmann, Vincent Lepetit
[Paper] [Code] [page]
TL;DR: We introduce NOPE, a simple approach to estimate relative pose of unseen objects given only a single reference image. NOPE also predicts 3D pose distribution which can be used to address pose ambiguities due to symmetries.
The practicality of 3D object pose estimation remains limited for many applications due to the need for prior knowledge of a 3D model and a training period for new objects. To address this limitation, we propose an approach that takes a single image of a new object as input and predicts the relative pose of this object in new images without prior knowledge of the object’s 3D model and without requiring training time for new objects and categories. We achieve this by training a model to directly predict discriminative embeddings for viewpoints surrounding the object. This prediction is done using a simple U-Net architecture with attention and conditioned on the desired pose, which yields extremely fast inference. We compare our approach to state-of-the-art methods and show it outperforms them both in terms of accuracy and robustness.

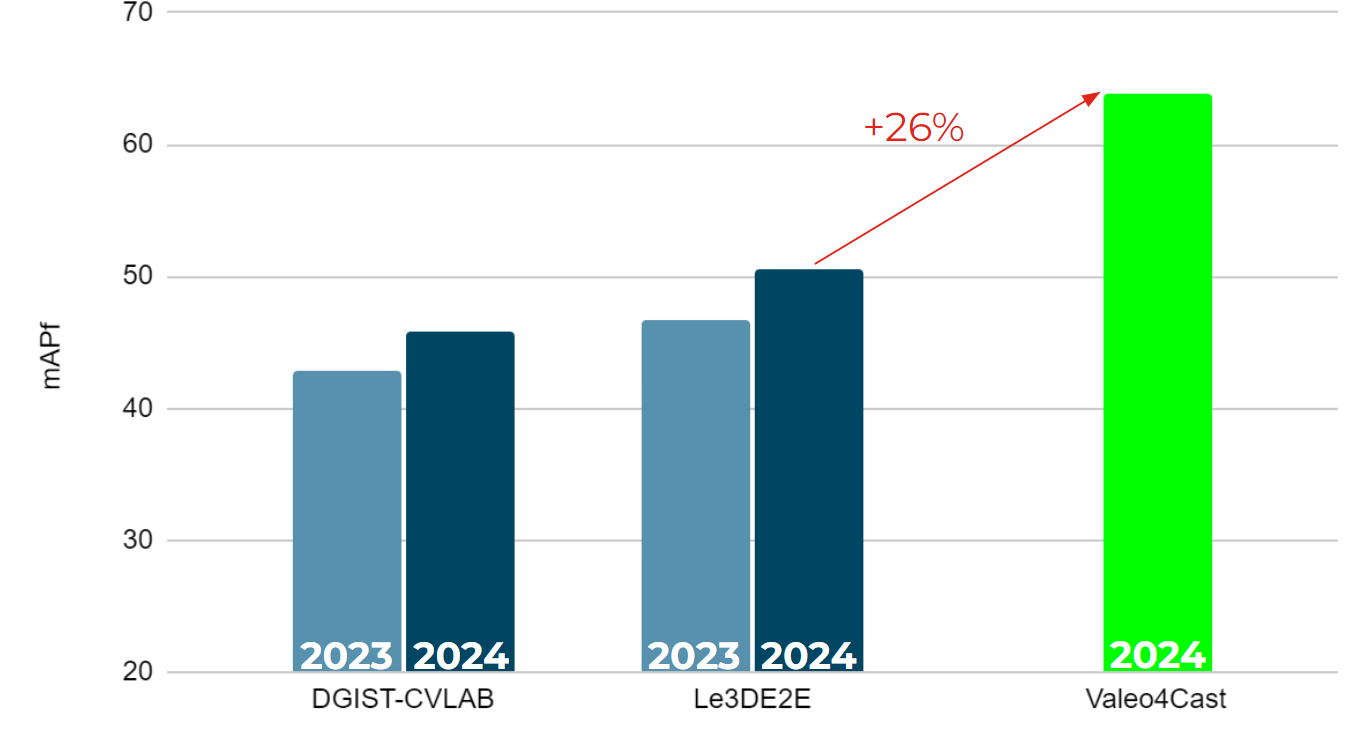
Valeo4Cast: A Modular Approach to End-to-End Forecasting
Authors: Yihong Xu, Éloi Zablocki, Alexandre Boulch, Gilles Puy, Mickaël Chen, Florent Bartoccioni, Nermin Samet, Oriane Siméoni, Spyros Gidaris, Tuan-Hung Vu, Andrei Bursuc, Eduardo Valle, Renaud Marlet, Matthieu Cord
[Paper] [leaderboard] [page]
Motion forecasting is crucial in autonomous driving systems to anticipate the future trajectories of surrounding agents such as pedestrians, vehicles, and traffic signals. In end-to-end forecasting, the model must jointly detect from sensor data (cameras or LiDARs) the position and past trajectories of the different elements of the scene and predict their future location. We depart from the current trend of tackling this task via end-to-end training from perception to forecasting and we use a modular approach instead. Following a recent study, we individually build and train detection, tracking, and forecasting modules. We then only use consecutive finetuning steps to integrate the modules better and alleviate compounding errors. Our study reveals that this simple yet effective approach significantly improves performance on the end-to-end forecasting benchmark. Consequently, our solution ranks first in the Argoverse 2 end-to-end Forecasting Challenge held at CVPR 2024 Workshop on Autonomous Driving (WAD), with 63.82 mAPf. We surpass forecasting results by +17.1 points over last year’s winner and by +13.3 points over this year’s runner-up. This remarkable performance in forecasting can be explained by our modular paradigm, which integrates finetuning strategies and significantly outperforms the end-to-end-trained counterparts.
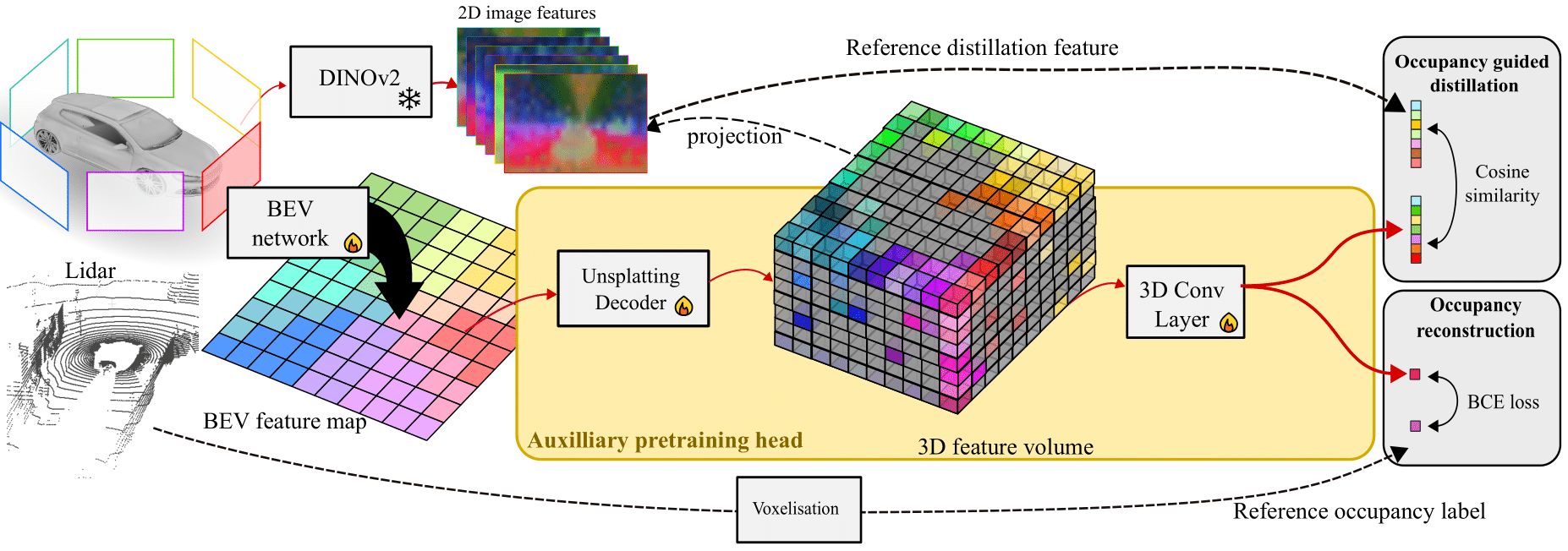
OccFeat: Self-supervised Occupancy Feature Prediction for Pretraining BEV Segmentation Networks
CVPR 2024 Workshop on Autonomous Driving (WAD)
Authors: Sophia Sirko-Galouchenko, Alexandre Boulch, Spyros Gidaris, Andrei Bursuc, Antonin Vobecky, Renaud Marlet, Patrick Pérez
[Paper] [page]
We introduce a self-supervised pretraining method, called OccFeat, for camera-only Bird’s-Eye-View (BEV) segmentation networks. With OccFeat, we pretrain a BEV network via occupancy prediction and feature distillation tasks. Occupancy prediction provides a 3D geometric understanding of the scene to the model. However, the geometry learned is class-agnostic. Hence, we add semantic information to the model in the 3D space through distillation from a self-supervised pretrained image foundation model. Models pretrained with our method exhibit improved BEV semantic segmentation performance, particularly in low-data scenarios. Moreover, empirical results affirm the efficacy of integrating feature distillation with 3D occupancy prediction in our pretraining approach.
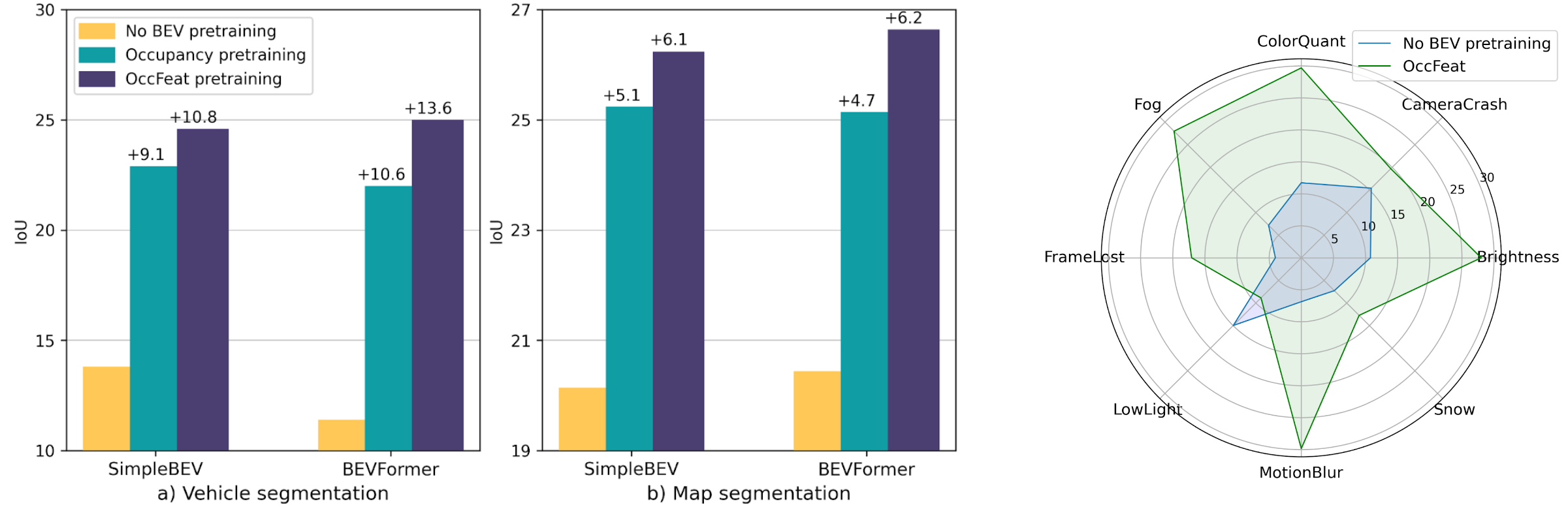
The results show the benefit of our pretraining method, especially in low-shot regimes, e.g., when using annotations only for 1% or 10% of nuScene’s training data. Additionally, our OccFeat pretraining improves the robustness, as evaluated on the nuScenes-C benchmark.
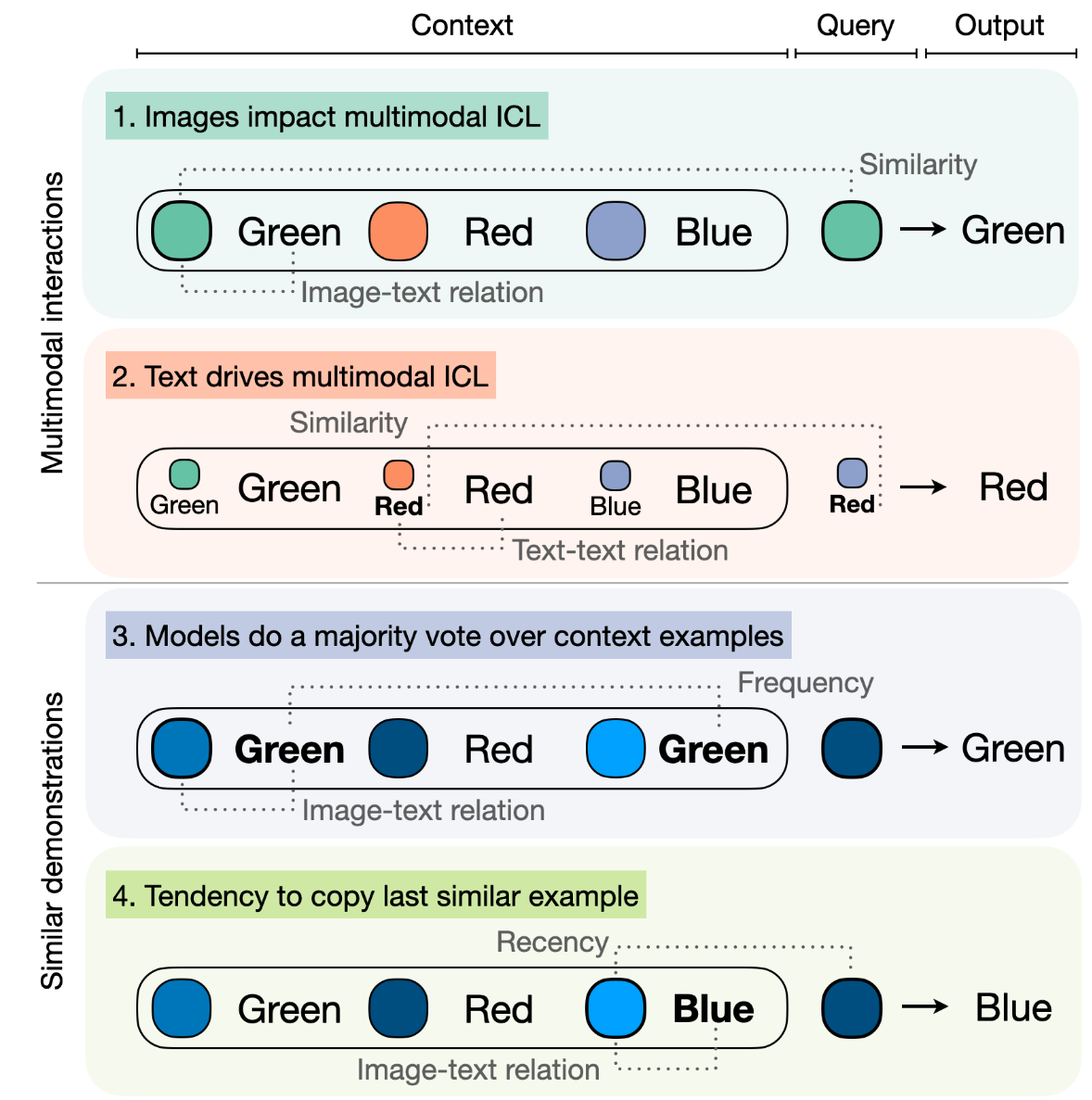
What Makes Multimodal In-Context Learning Work?
CVPR 2024 Workshop on Prompting in Vision
Authors: Folco Bertini Baldassini, Mustafa Shukor, Matthieu Cord, Laure Soulier, Benjamin Piwowarski
[Paper] [code] [page]
Large Language Models have demonstrated remarkable performance across various tasks, exhibiting the capacity to swiftly acquire new skills, such as through In-Context Learning (ICL) with minimal demonstration examples. In this work, we present a comprehensive framework for investigating Multimodal ICL (M-ICL) in the context of Large Multimodal Models. We consider the best open-source multimodal models (e.g., IDEFICS, OpenFlamingo) and a wide range of multimodal tasks. Our study unveils several noteworthy findings: (1) M-ICL primarily relies on text-driven mechanisms, showing little to no influence from the image modality. (2) When used with advanced-ICL strategy (like RICES), M-ICL is not better than a simple strategy based on majority voting over context examples. Moreover, we identify several biases and limitations of M-ICL that warrant consideration prior to deployment.