PPT: Pretraining with Pseudo-Labeled Trajectories for Motion Forecasting
Yihong Xu Yuan Yin Éloi Zablocki Tuan-Hung Vu Alexandre Boulch Matthieu Cord
ICRA 2026
Abstract
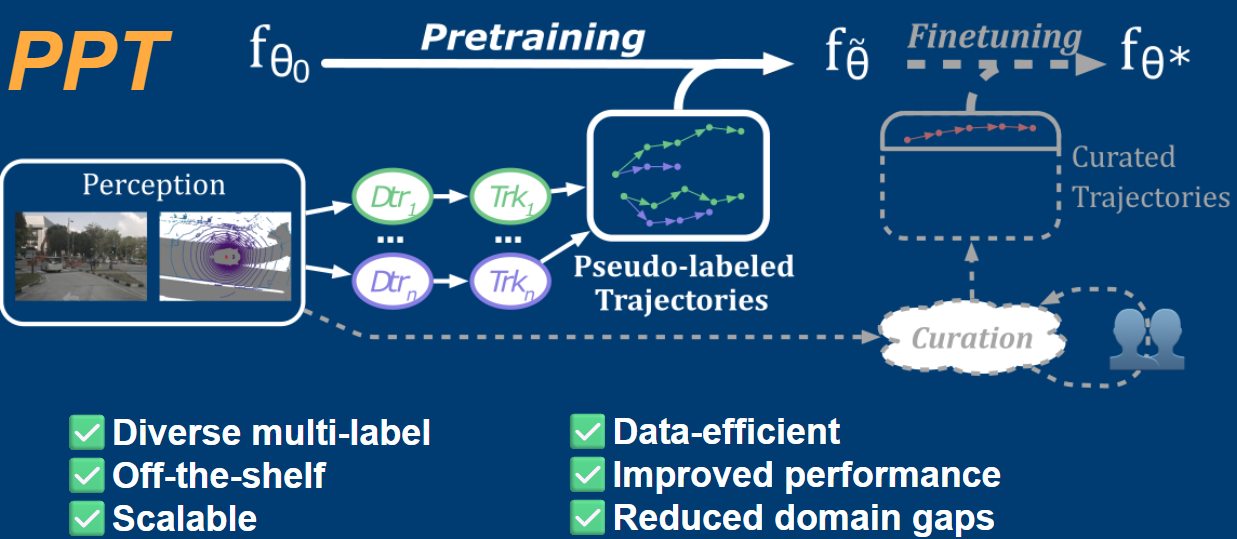
Accurately predicting how agents move in dynamic scenes is essential for safe autonomous driving. State-of-the-art motion forecasting models rely on large curated datasets with manually annotated or heavily post-processed trajectories. However, building these datasets is costly, generally manual, hard to scale, and lacks reproducibility. They also introduce domain gaps that limit generalization across environments. We introduce PPT (Pretraining with Pseudo-labeled Trajectories), a simple and scalable alternative that uses unprocessed and diverse trajectories automatically generated from off-the-shelf 3D detectors and tracking. Unlike traditional pipelines aiming for clean, single-label annotations, PPT embraces noise and diversity as useful signals for learning robust representations. With optional finetuning on a small amount of labeled data, models pretrained with PPT achieve strong performance across standard benchmarks particularly in low-data regimes, and in cross-domain, end-to-end and multi-class settings. PPT is easy to implement and improves generalization in motion forecasting.
BibTeX
@inproceedings{xu2026ppt,
author = {Yihong Xu and
Yuan Yin and
{\'{E}}loi Zablocki and
Tuan{-}Hung Vu and
Alexandre Boulch and
Matthieu Cord},
title = {PPT: Pre-Training with Pseudo-Labeled Trajectories for Motion Forecasting},
booktitle = {ICRA},
year = {2026},
}