PoM: A Linear-Time Replacement for Attention with the Polynomial Mixer
David Picard Nicolas Dufour Lucas Degeorge Arijit Ghosh Davide Allegro Tom Ravaud Yohann Perron Corentin Sautier Zeynep Sonat Baltaci Fei Meng Syrine Kalleli Marta López-Rauhut Thibaut Loiseau Ségolène Albouy Raphael Baena Elliot Vincent Loic Landrieu
CVPR Findings 2026
Abstract
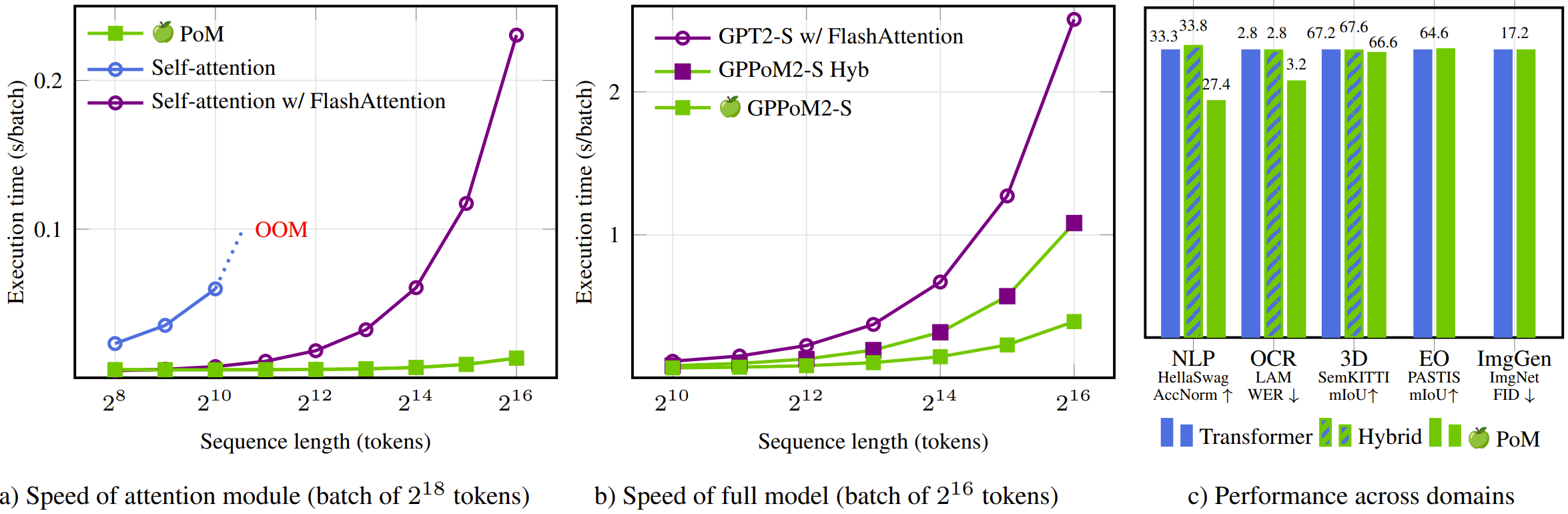
This paper introduces the Polynomial Mixer (PoM), a novel token mixing mechanism with linear complexity that serves as a drop-in replacement for self-attention. PoM aggregates input tokens into a compact representation through a learned polynomial function, from which each token retrieves contextual information. We prove that PoM satisfies the contextual mapping property, ensuring that transformers equipped with PoM remain universal sequence-to-sequence approximators. We replace standard self-attention with PoM across five diverse domains: text generation, handwritten text recognition, image generation, 3D modeling, and Earth observation. PoM matches the performance of attention-based models while drastically reducing computational cost when working with long sequences.
BibTeX
@article{picard2026pom,
title={PoM: A Linear-Time Replacement for Attention with the Polynomial Mixer},
author={Picard, David and Dufour, Nicolas and Degeorge, Lucas and Ghosh, Arijit and Allegro, Davide and Ravaud, Tom and Perron, Yohann and Sautier, Corentin and Baltaci, Zeynep Sonat and Meng, Fei and Kalleli, Syrine and L{\'o}pez-Rauhut, Marta and Loiseau, Thibaut and Albouy, S{\'e}gol{\`e}ne and Baena, Raphael and Vincent, Elliot and Landrieu, Loic},
journal={arXiv preprint arXiv:2604.06129},
year={2026}
}