Multi-Token Prediction Needs Registers
Anastasios Gerontopoulos Spyros Gidaris Nikos Komodakis
NeurIPS 2025
Abstract
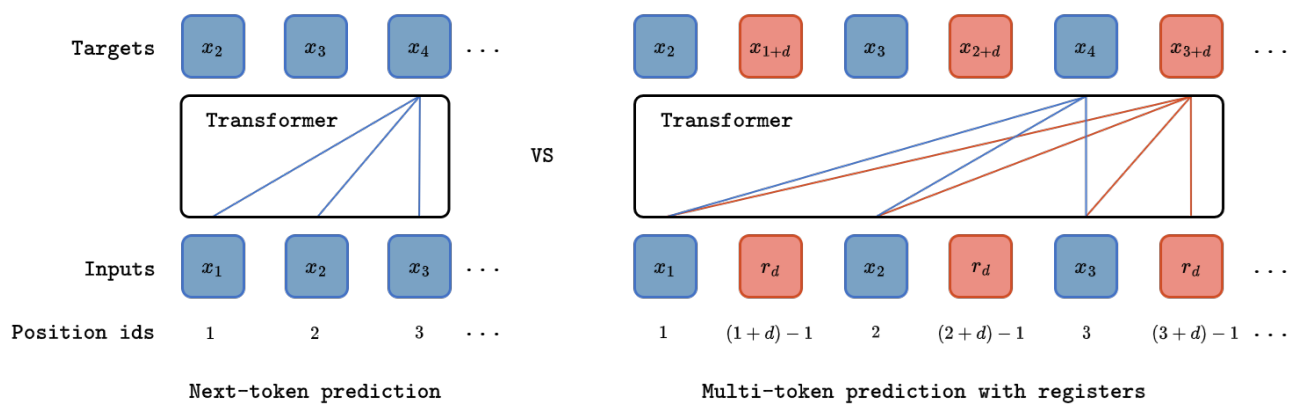
Multi-token prediction has emerged as a promising objective for improving language model pretraining, but its benefits have not consistently generalized to other settings such as fine-tuning. In this paper, we propose MuToR, a simple and effective approach to multi-token prediction that interleaves learnable register tokens into the input sequence, each tasked with predicting future targets. Compared to existing methods, MuToR offers several key advantages: it introduces only a negligible number of additional parameters, requires no architectural changes--ensuring compatibility with off-the-shelf pretrained language models--and remains aligned with the next-token pretraining objective, making it especially well-suited for supervised fine-tuning. Moreover, it naturally supports scalable prediction horizons. We demonstrate the effectiveness and versatility of MuToR across a range of use cases, including supervised fine-tuning, parameter-efficient fine-tuning (PEFT), and pretraining, on challenging generative tasks in both language and vision domains.
BibTeX
@inproceedings{gerontopoulos2025mutor,
title={Multi-Token Prediction Needs Registers},
author={Gerontopoulos, Anastasios and Gidaris, Spyros and Komodakis, Nikos},
booktitle={NeurIPs},
year={2025}
}