What Makes Multimodal In-Context Learning Work?
CVPR Workshop on Prompting in Vision 2024
Abstract
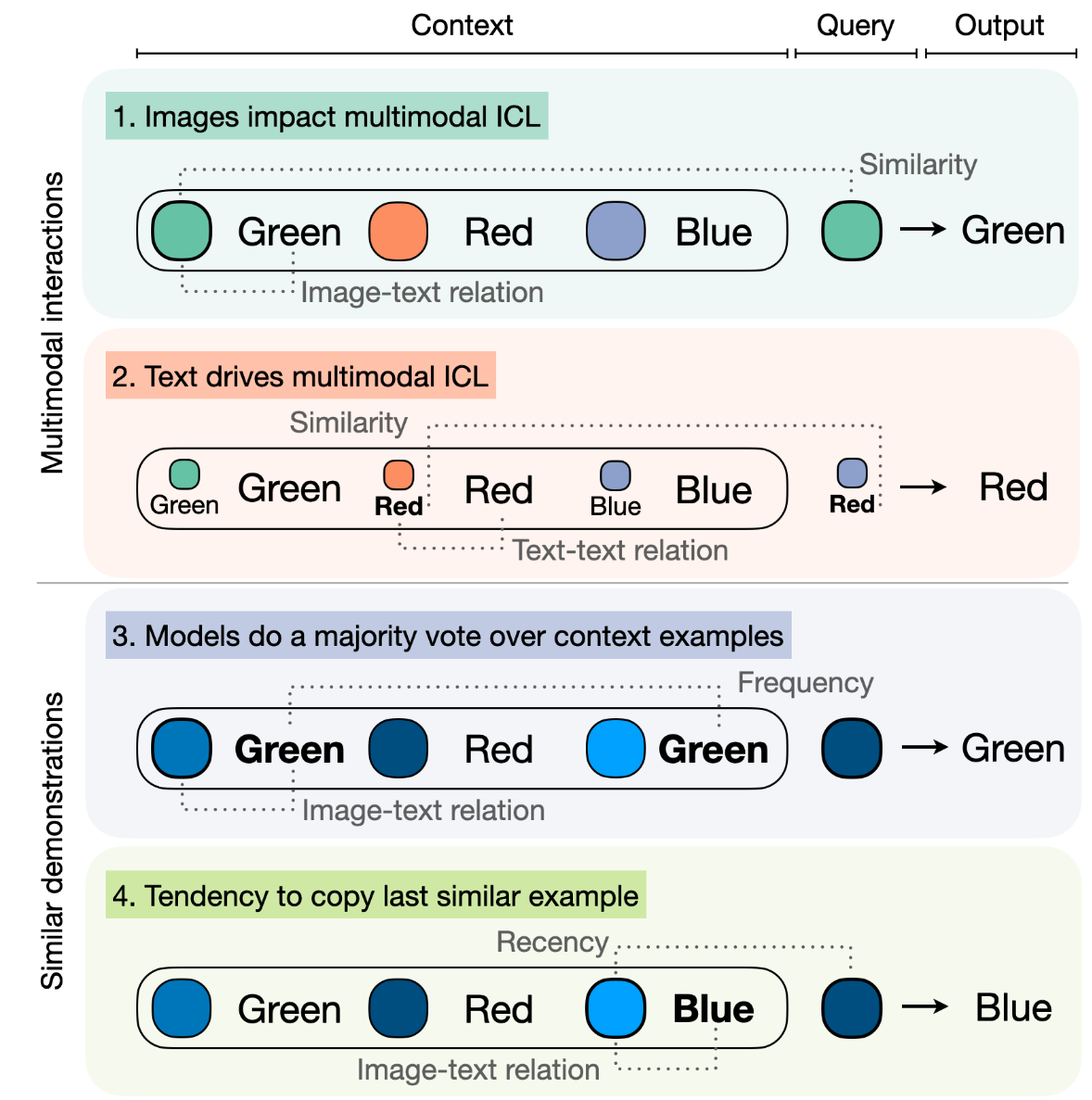
Large Language Models have demonstrated remarkable performance across various tasks, exhibiting the capacity to swiftly acquire new skills, such as through In-Context Learning (ICL) with minimal demonstration examples. In this work, we present a comprehensive framework for investigating Multimodal ICL (M-ICL) in the context of Large Multimodal Models. We consider the best open-source multimodal models (e.g., IDEFICS, OpenFlamingo) and a wide range of multimodal tasks. Our study unveils several noteworthy findings: (1) M-ICL primarily relies on text-driven mechanisms, showing little to no influence from the image modality. (2) When used with advanced-ICL strategy (like RICES), M-ICL is not better than a simple strategy based on majority voting over context examples. Moreover, we identify several biases and limitations of M-ICL that warrant consideration prior to deployment.
BibTeX
@misc{baldassini2024makes,
title={What Makes Multimodal In-Context Learning Work?},
author={Folco Bertini Baldassini and Mustafa Shukor and Matthieu Cord and Laure Soulier and Benjamin Piwowarski},
year={2024},
eprint={2404.15736},
archivePrefix={arXiv},
primaryClass={cs.CV}
}