3D sans 3D Scans: Scalable Pre-training from Video-Generated Point Clouds
CVPR 2026
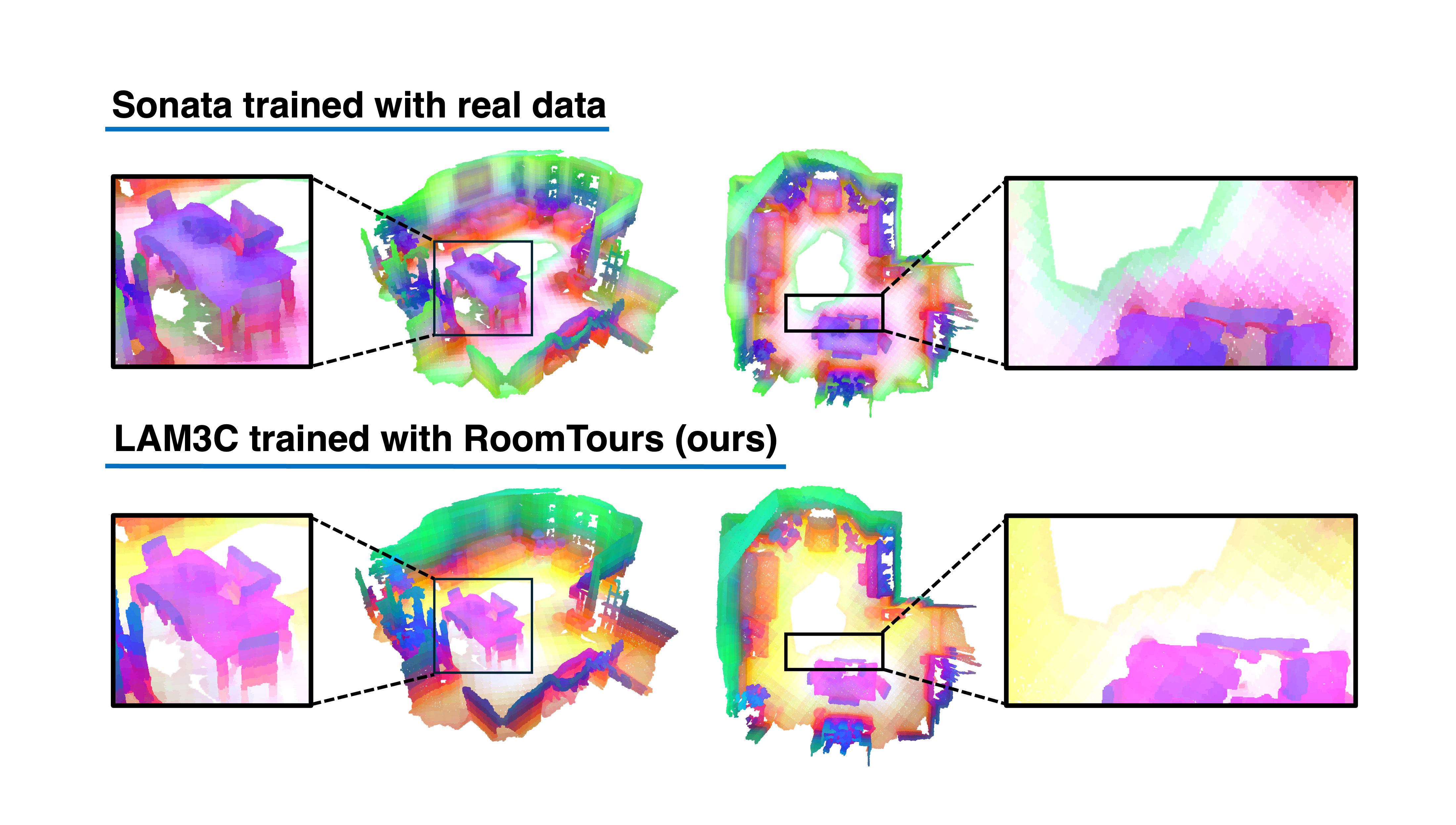
Abstract
We investigate the use of unlabeled videos for learning 3D representations without ever resorting to a 3D sensor. To this end, we introduce LAM3C, a self-supervised learning framework that operates directly on point clouds reconstructed from video. To support this, we curate RoomTours, a new dataset of 49,219 scenes generated from web-collected room-walkthrough videos using a feed-forward reconstruction model. Pre-training on this video-derived data introduces challenges: noisy geometry and incomplete coverage destabilize standard SSL objectives. We address these by proposing a noise-regularized loss that stabilizes representation learning by enforcing local geometric smoothness and ensuring feature stability under noisy point clouds. Despite never seeing real 3D scans, LAM3C surpasses prior self-supervised methods on indoor semantic and instance segmentation, demonstrating that unlabeled videos are a powerful and scalable resource for 3D self-supervised learning.
BibTeX
@inproceedings{yamada2026lam3c,
title={3D sans 3D Scans: Scalable Pre-training from Video-Generated Point Clouds},
author={Yamada, Ryosuke and Ide, Kohsuke and Fukuhara, Yoshihiro and Kataoka, Hirokatsu and Puy, Gilles and Bursuc, Andrei and Asano, Yuki M.},
booktitle={CVPR},
year={2026}
}