FLOSS: Free Lunch in Open-vocabulary Semantic Segmentation
ICCV 2025
Abstract
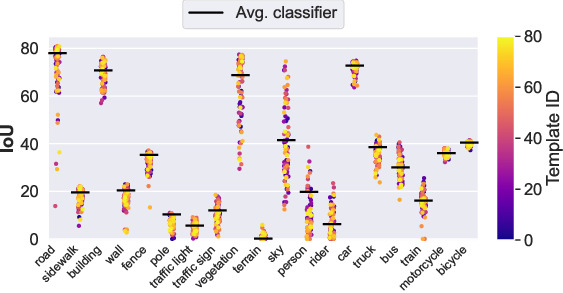
In this paper, we challenge the conventional practice in Open-Vocabulary Semantic Segmentation (OVSS) of using averaged class-wise text embeddings, which are typically obtained by encoding each class name with multiple templates (e.g., a photo of , a sketch of a ). We investigate the impact of templates for OVSS, and find that for each class, there exist single-template classifiers--which we refer to as class-experts--that significantly outperform the conventional averaged classifier. First, to identify these class-experts, we introduce a novel approach that estimates them without any labeled data or training. By leveraging the class-wise prediction entropy of single-template classifiers, we select those yielding the lowest entropy as the most reliable class-experts. Second, we combine the outputs of class-experts in a new fusion process. Our plug-and-play method, coined FLOSS, is orthogonal and complementary to existing OVSS methods, offering an improvement without the need for additional labels or training. Extensive experiments show that FLOSS consistently enhances state-of-the-art OVSS models, generalizes well across datasets with different distribution shifts, and delivers substantial improvements in low-data scenarios where only a few unlabeled images are available. Our code is available at this https URL . </p>
BibTeX
@inproceedings{benigmim2025floss,
title={Fine-Tuning CLIP's Last Visual Projector: A Few-Shot Cornucopia},
author={Yasser Benigmim and Mohammad Fahes and Tuan-Hung Vu and Andrei Bursuc and Raoul de Charette},
booktitle={ICCV},
year={2025}
}