DINO-Foresight: Looking into the Future with DINO
Efstathios Karypidis Ioannis Kakogeorgiou Spyros Gidaris Nikos Komodakis
NeurIPS 2025
Abstract
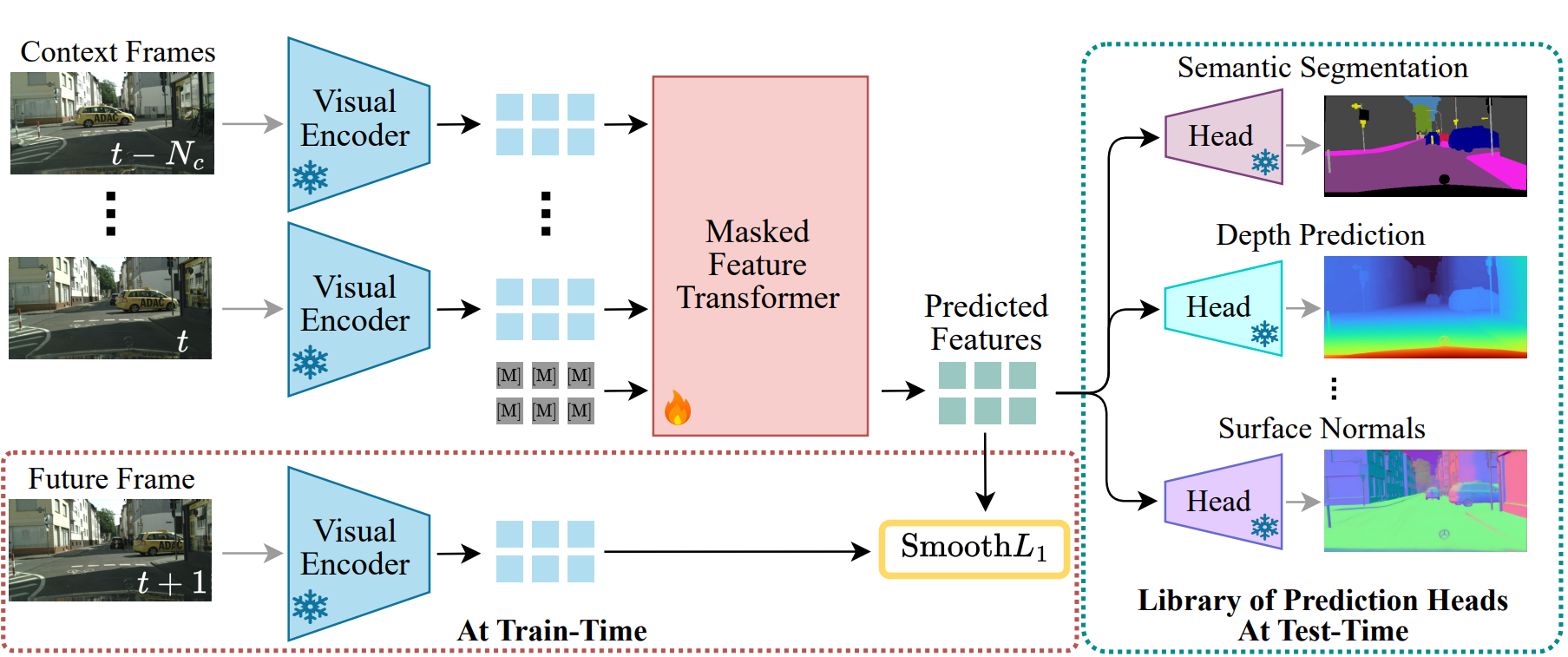
Predicting future dynamics is crucial for applications like autonomous driving and robotics, where understanding the environment is key. Existing pixel-level methods are computationally expensive and often focus on irrelevant details. To address these challenges, we introduce DINO-Foresight, a novel framework that operates in the semantic feature space of pretrained Vision Foundation Models (VFMs). Our approach trains a masked feature transformer in a self-supervised manner to predict the evolution of VFM features over time. By forecasting these features, we can apply off-the-shelf, task-specific heads for various scene understanding tasks. In this framework, VFM features are treated as a latent space, to which different heads attach to perform specific tasks for future-frame analysis. Extensive experiments show the very strong performance, robustness and scalability of our framework.
BibTeX
@inproceedings{karypidis2025dinoforesight,
title={DINO-Foresight: Looking into the Future with DINO},
author={Karypidis, Efstathios and Kakogeorgiou, Ioannis and Gidaris, Spyros and Komodakis, Nikos},
booktitle={NeurIPs},
year={2025}
}