CoReDi: Coevolving Representations in Joint Image-Feature Diffusion
ECCV 2026
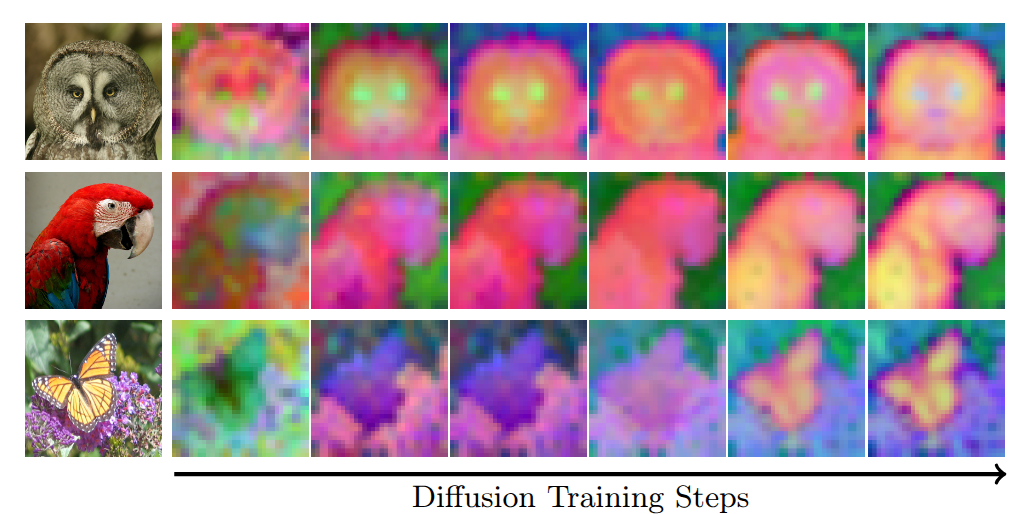
Abstract
Joint image-feature generative modeling has recently emerged as an effective strategy for improving diffusion training by coupling low-level VAE latents with high-level semantic features extracted from pre-trained visual encoders. We propose CoReDi (Coevolving Representation Diffusion), which enables the semantic representation space to evolve during training through a learned lightweight linear projection. We employ stop-gradient targets, normalization, and targeted regularization that prevents feature collapse to ensure stability. The framework is tested on both VAE latent and pixel-space diffusion, showing improvements in convergence speed and sample quality compared to fixed representation approaches.
BibTeX
@inproceedings{kouzelis2026coredi,
title = {Coevolving Representations in Joint Image-Feature Diffusion},
author = {Kouzelis, Theodoros and Gidaris, Spyros and Komodakis, Nikos},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2026}
}