TOAD: Test-Time Trajectory Optimization for Autonomous Driving
preprint 2026

TOAD turns the planner's frozen scorer into a reward and searches for trajectories that maximize it with CEM at test time.
Abstract
End-to-end planners for autonomous driving typically generate a set of candidate trajectories, score each one, and return the highest-scoring candidate. However, the scorer is applied only after the proposals are generated and cannot influence the set of trajectories: a weak set of candidates limits planning performance regardless of the scorer’s quality. We instead treat the scorer as a learned trajectory-level reward function and search for trajectories that maximize it. Our method, TOAD, runs the Cross-Entropy Method at test time, warm-started from the planner’s proposals. It requires no retraining and is plug-and-play for existing planners. Across six base planners, TOAD improves results on NAVSIM-v1 (94.7 PDMS), NAVSIM-v2 (56.3 EPDMS), and the closed-loop HUGSIM benchmark.
Key insight. Successful test-time search requires a scorer that stays accurate off the proposal distribution. Scorers fit to a fixed vocabulary fail in TOAD despite strong ranking performance; only a disentangled scorer trained to evaluate freely decoded trajectories survives the search.
Architecture
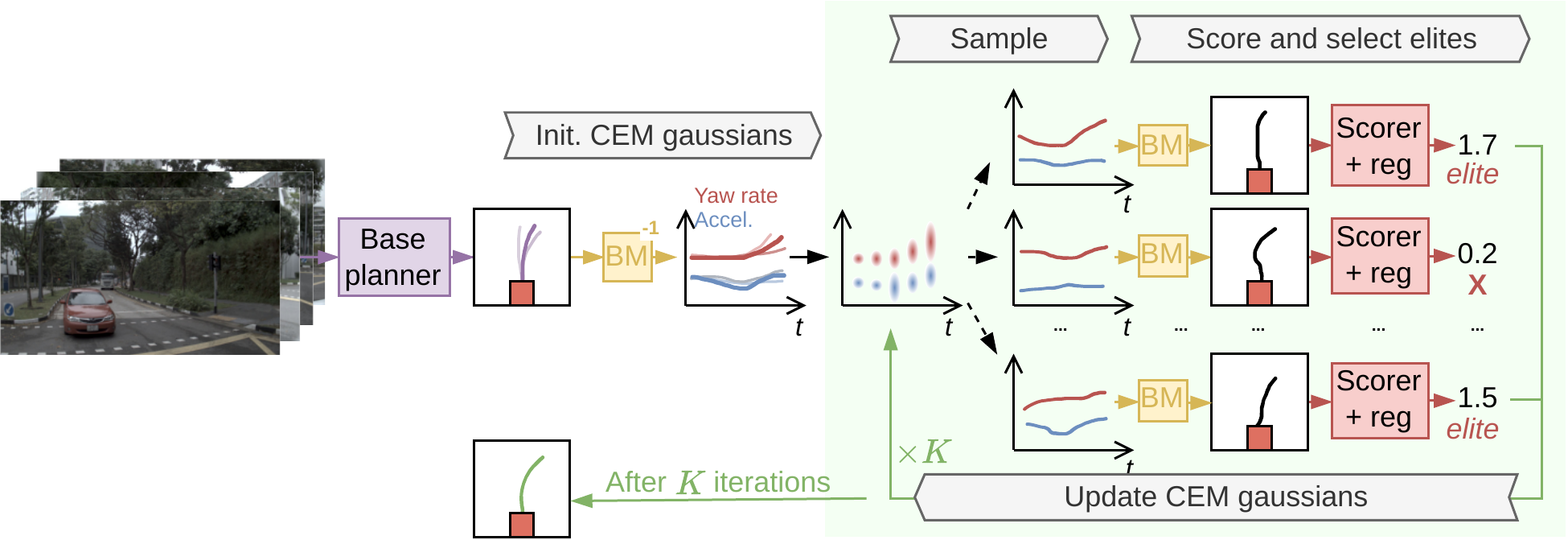
Overview of TOAD: CEM in control space, warm-started from the planner's proposals, scored under Scorer + reg.
Qualitative Examples
Evolution of CEM Optimization
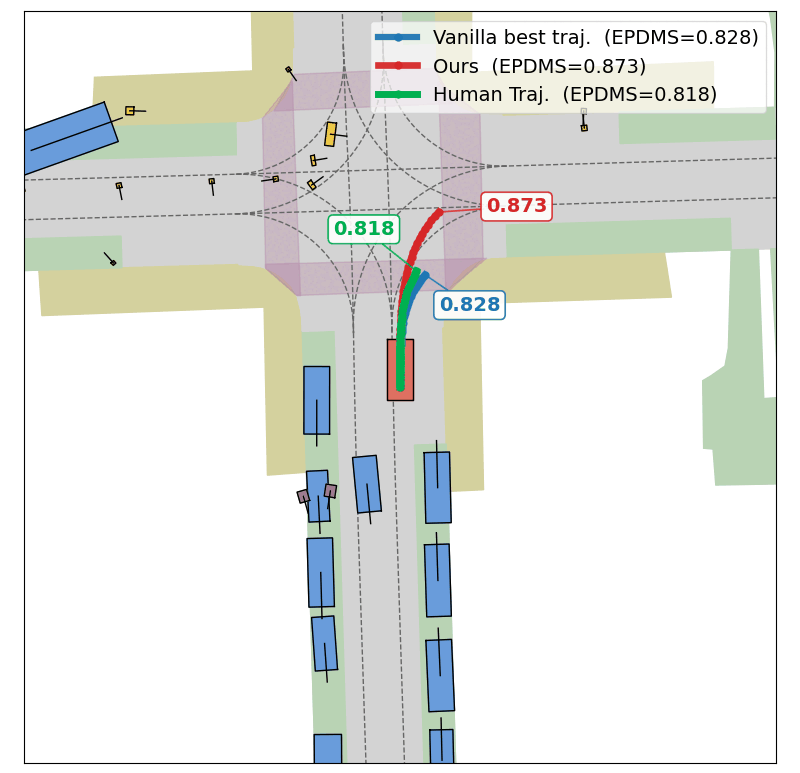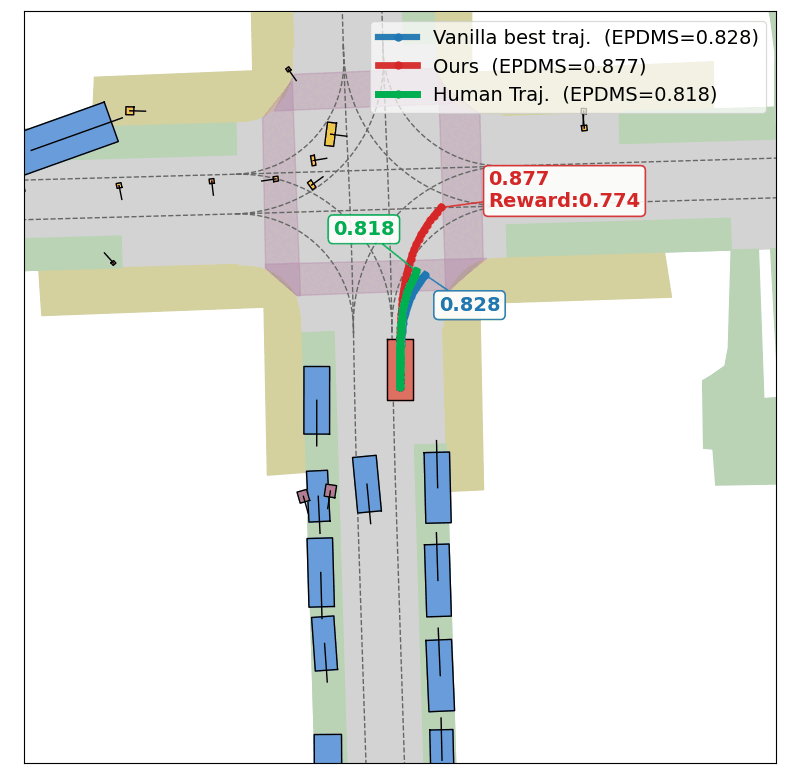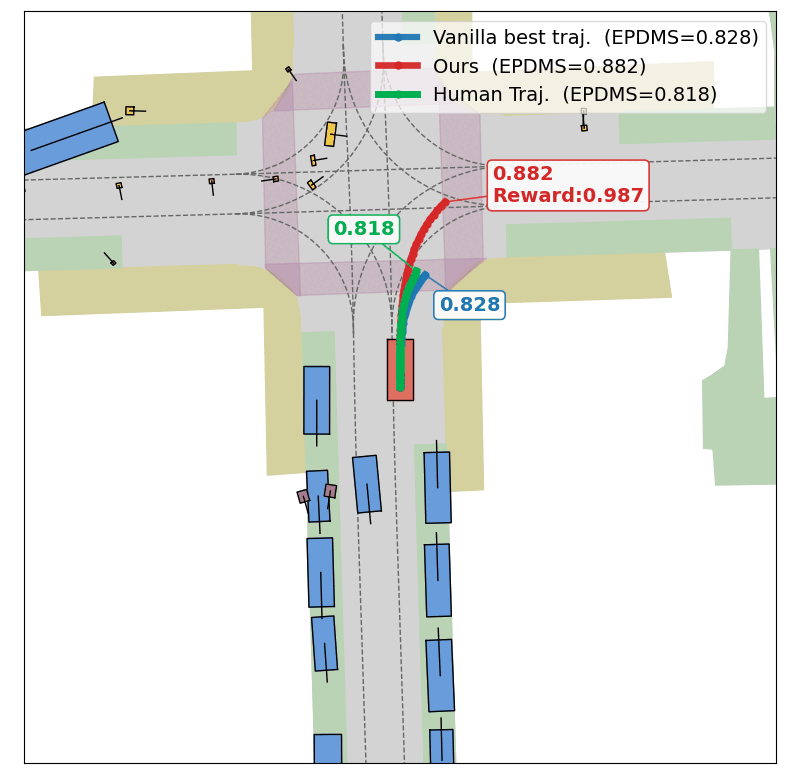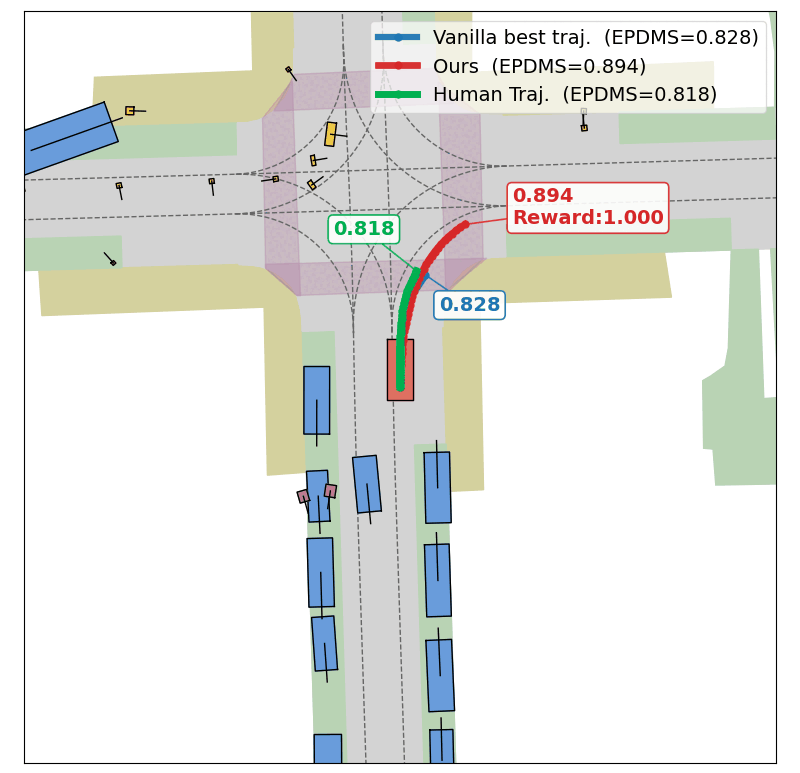
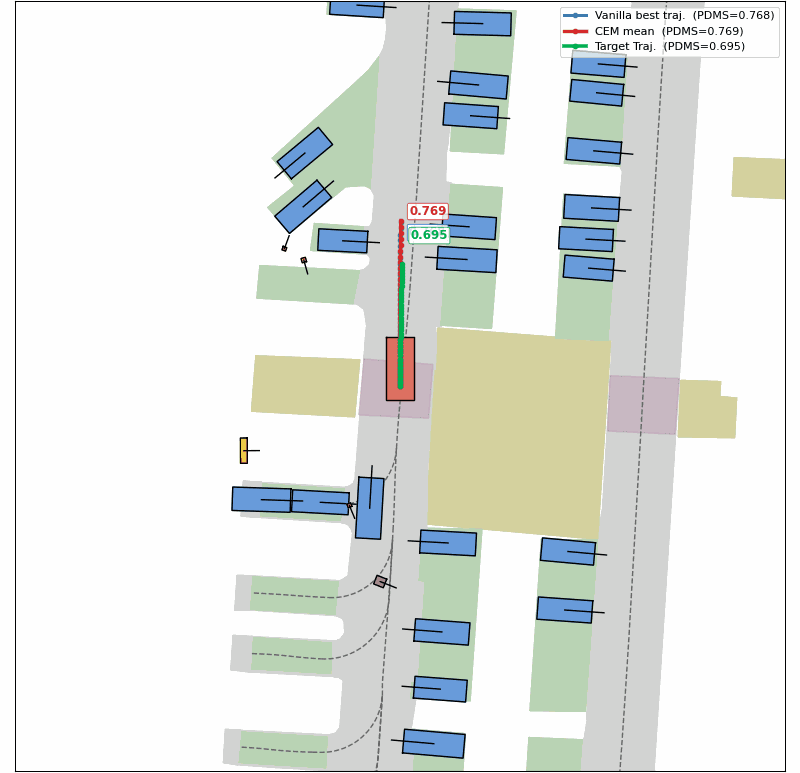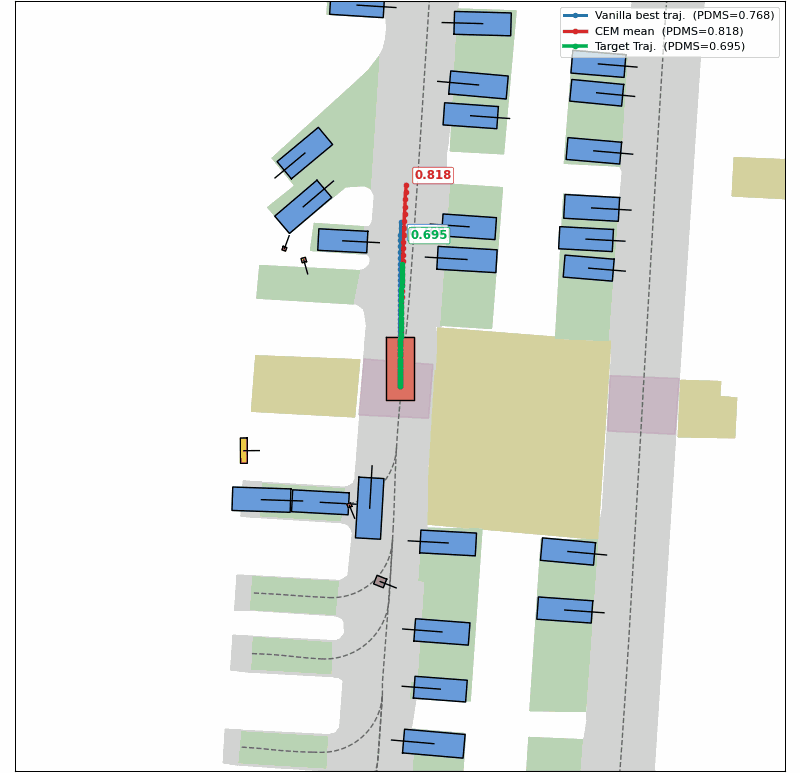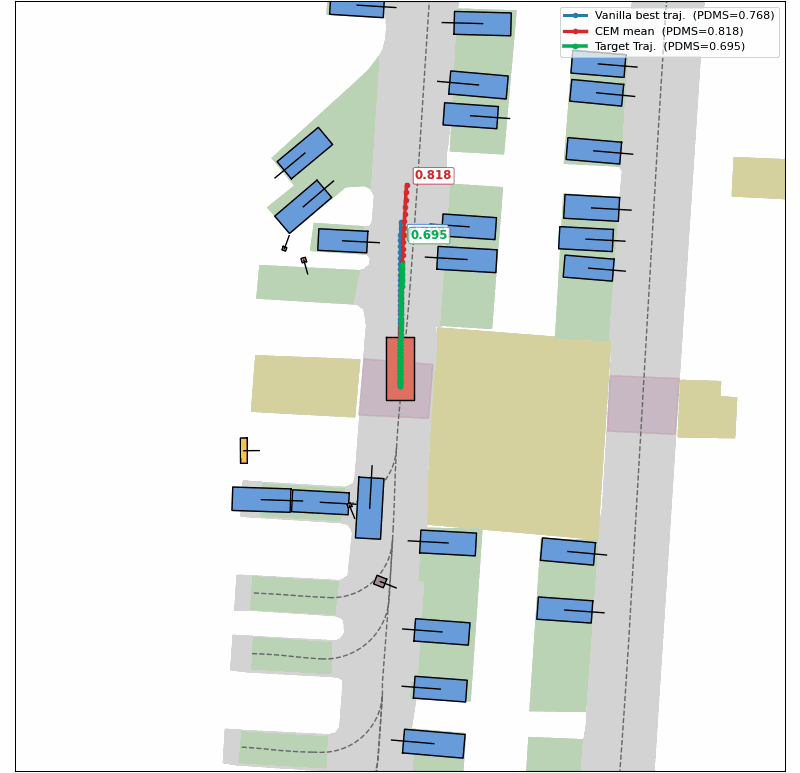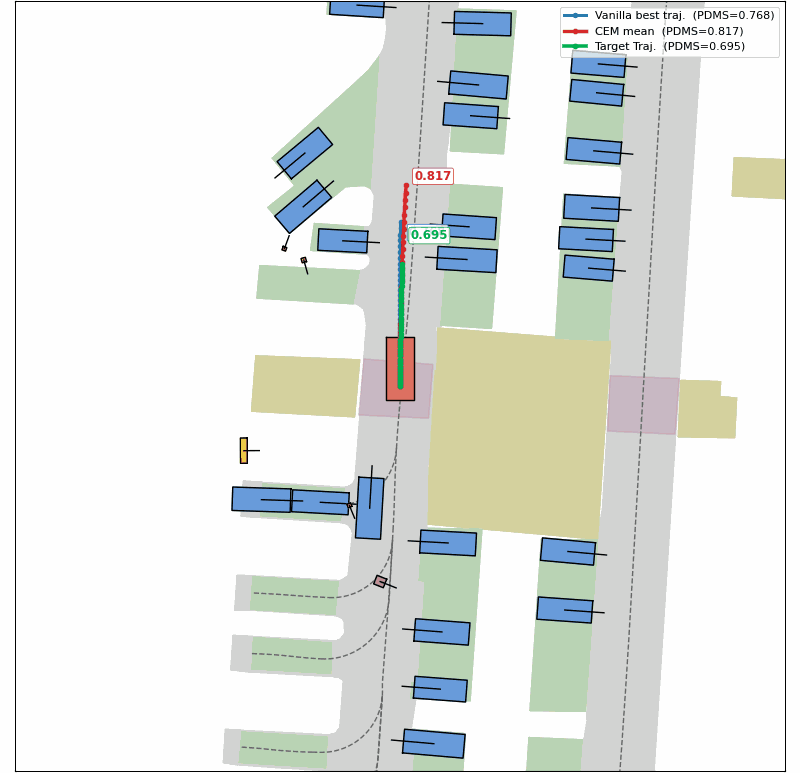
Success
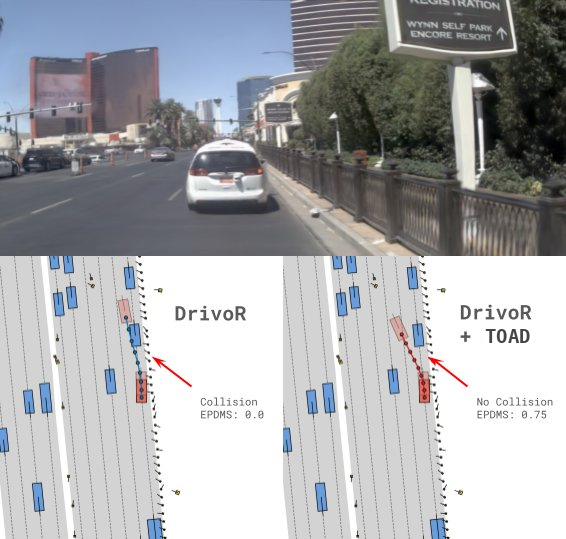
In this scene, the base planner (DrivoR) commits to a trajectory that results in a collision (EPDMS: 0.0). Optimizing the planner's scorer at test time, TOAD searches for a higher-reward trajectory that avoids the collision and recovers a safe maneuver (EPDMS: 0.75).
Failure
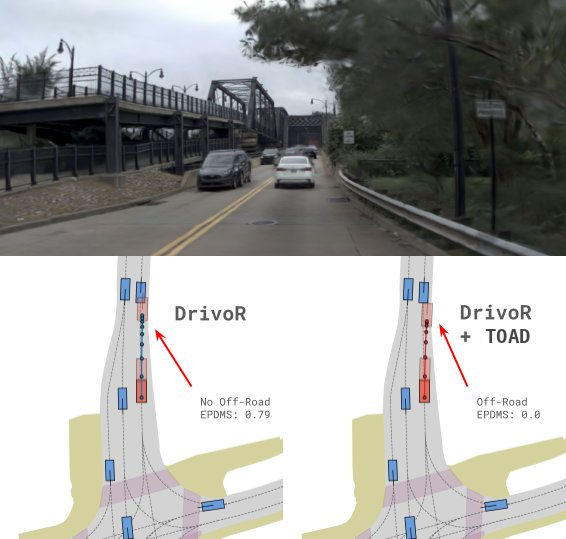
TOAD is bounded by the quality of the learned scorer it optimizes. Here, the base planner (DrivoR) stays on-road and achieves a strong score (EPDMS: 0.79), but TOAD follows the scorer's reward into an off-road trajectory (EPDMS: 0.0): when the reward is misleading, maximizing it can hurt rather than help.
BibTeX
@misc{xu2026toad,
title = {Test-Time Trajectory Optimization for Autonomous Driving},
author = {Xu, Yihong and Zablocki, {\'E}loi and Yin, Yuan and Ramzi, Elias and Kirby, Ellington and Boulch, Alexandre and Cord, Matthieu},
year = {2026},
eprint = {2606.07170},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}