valeo.ai at ICCV 2025
The International Conference on Computer Vision (ICCV) is a leading conference that brings together researchers and practitioners in computer vision and machine learning. At the 2025 edition, the valeo.ai team will present five papers in the main conference. We are also co-organizing the Learning to See: Advancing Spatial Understanding for Embodied Intelligence workshop, and contributing to the Foundational Data for Industrial Tech Transfer workshop with a keynote on Towards openness of vision foundation models.
The team will be at ICCV to present these works, exchange ideas, and share our exciting ongoing research. We look forward to seeing you in Honolulu!


DIP: Unsupervised Dense In-Context Post-training of Visual Representations
Authors: Sophia Sirko-Galouchenko, Antonin Vobecky, Andrei Bursuc, Nicolas Thome, Spyros Gidaris
[Paper] [Code]

We introduce DIP, a novel unsupervised post-training method designed to enhance dense image representations in large-scale pretrained vision encoders for in-context scene understanding. Unlike prior approaches that rely on complex self-distillation architectures, our method trains the vision encoder using pseudo-tasks that explicitly simulate downstream in-context scenarios, inspired by meta-learning principles. To enable post-training on unlabeled data, we propose an automatic mechanism for generating in-context tasks that combines a pretrained diffusion model and the vision encoder itself. DIP is simple, unsupervised, and computationally efficient, requiring less than 9 hours on a single A100 GPU. By learning dense representations through pseudo in-context tasks, it achieves strong performance across a wide variety of downstream real-world in-context scene understanding tasks. It outperforms both the initial vision encoder and prior methods, offering a practical and effective solution for improving dense representations.
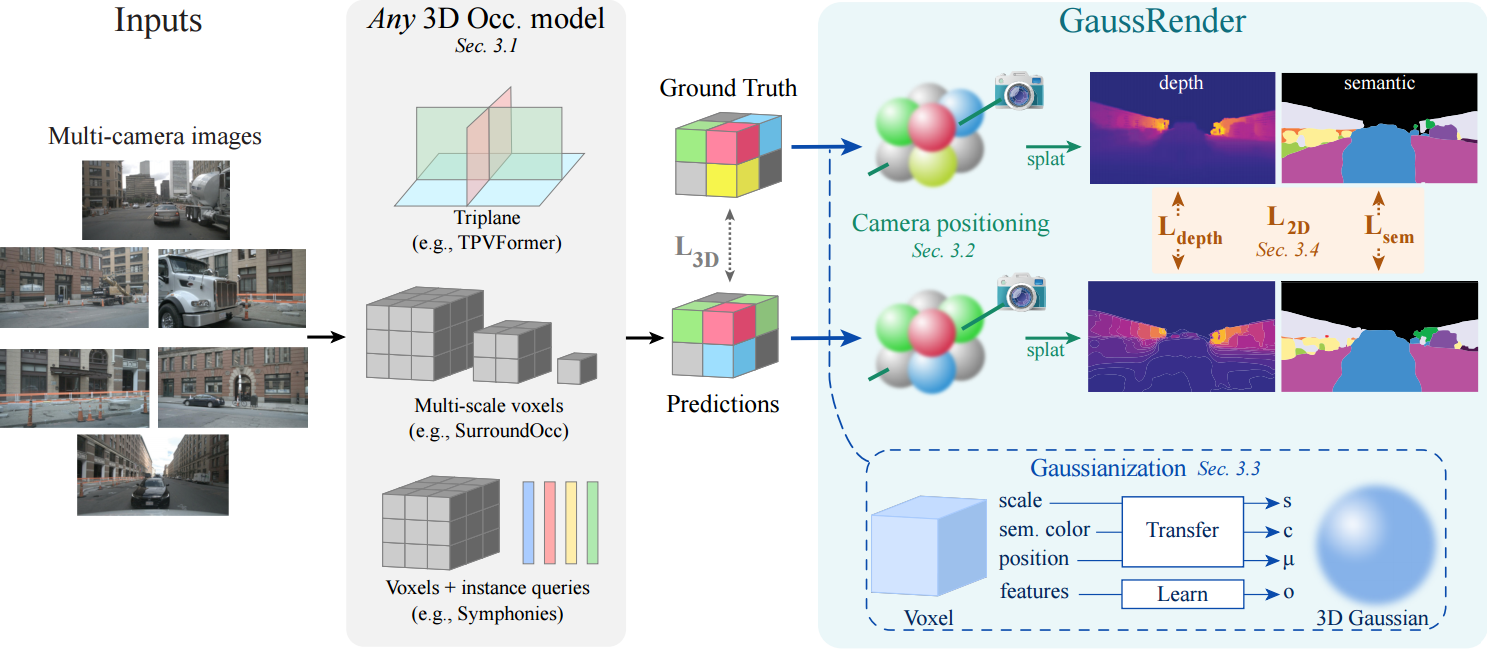
GaussRender: Learning 3D Occupancy with Gaussian Rendering
Authors: Loïck Chambon, Éloi Zablocki, Alexandre Boulch, Mickaël Chen, Matthieu Cord
[Paper] [Code]
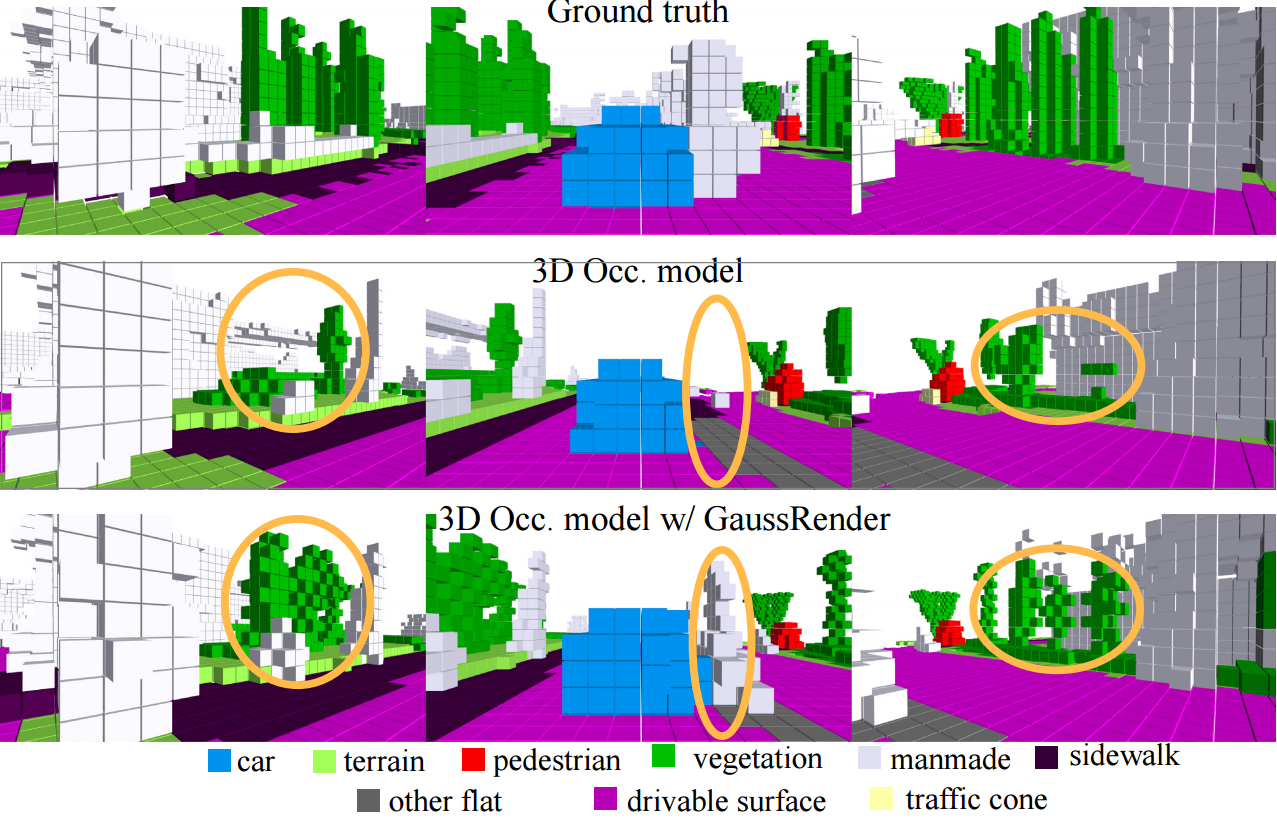
Understanding the 3D geometry and semantics of driving scenes is critical for safe autonomous driving. Recent advances in 3D occupancy prediction improve scene representation but often suffer from spatial inconsistencies, leading to floating artifacts and poor surface localization. Existing voxel-wise losses (e.g., cross-entropy) fail to enforce geometric coherence. GaussRender is a module that improves 3D occupancy learning by enforcing projective consistency. The key idea is to project both predicted and ground-truth 3D occupancy into 2D camera views for supervision, penalizing inconsistent 3D configurations and enforcing coherent 3D structure. To achieve this efficiently, GaussRender leverages differentiable rendering with Gaussian splatting. It integrates seamlessly with existing architectures, requires no inference-time modifications, and significantly improves geometric fidelity across multiple benchmarks (SurroundOcc-nuScenes, Occ3D-nuScenes, SSCBench-KITTI360) and 3D occupancy models (TPVFormer, SurroundOcc, Symphonies).


Results
GaussRender can be plugged into any 3D model. Dedicated experiments on multiple 3D benchmarks (SurroundOcc-nuScenes, Occ3D-nuScenes, SSCBench-KITTI360) and models (TPVFormer, SurroundOcc, Symphonies) demonstrate its performance.
Occ3D-nuScenes
| Models | TPVFormer (ours) | TPVFormer | SurroundOcc (ours) | SurroundOcc | OccFormer | RenderOcc |
|---|---|---|---|---|---|---|
| Type | w/ GaussRender | base | w/ GaussRender | base | base | base |
| mIoU | 30.48 🥇 (+2.65) | 27.83 | 30.38 🥈 (+1.17) | 29.21 | 21.93 | 26.11 |
| RayIoU | 38.3 🥇 (+1.1) | 37.2 | 37.5 🥈 (+2.0) | 35.5 | - | 19.5 |
SurroundOcc-nuScenes
| Models | TPVFormer (ours) | TPVFormer | SurroundOcc (ours) | SurroundOcc | OccFormer | GaussianFormerv2 |
|---|---|---|---|---|---|---|
| Type | w/ GaussRender | base | w/ GaussRender | base | base | base |
| IoU | 32.05 🥈 (+1.19) | 30.86 | 32.61 🥇 (+1.12) | 31.49 | 31.39 | 30.56 |
| mIoU | 20.58 🥈 (+3.48) | 17.10 | 20.82 🥇 (+0.52) | 20.30 | 19.03 | 20.02 |
SSCBench-KITTI360
| Models | SurroundOcc (ours) | SurroundOcc | Symphonies (ours) | Symphonies | OccFormer | MonoScene |
|---|---|---|---|---|---|---|
| Type | w/ GaussRender | base | w/ GaussRender | base | base | base |
| IoU | 38.62 (+0.11) | 38.51 | 44.08 🥇 (+0.68) | 43.40 🥈 | 40.27 | 37.87 |
| mIoU | 13.34 (+0.26) | 13.08 | 18.11 🥇 (+0.29) | 17.82 🥈 | 13.81 | 12.31 |
MoSiC: Optimal-Transport Motion Trajectories for Dense Self-Supervised Learning
Authors: Mohammadreza Salehi, Shashanka Venkataramanan, Ioana Simion, Efstratios Gavves, Cees Snoek, Yuki Asano
[Paper] [Code]

Dense self-supervised learning has shown great promise for learning pixel- and patch-level representations, but extending it to videos remains challenging due to complex motion dynamics. Existing approaches struggle under object deformations, occlusions, and camera movement, leading to inconsistent feature learning over time. In this work, we introduce MoSiC, a motion-guided self-supervised framework that clusters dense point tracks to learn spatiotemporally consistent representations. Using an off-the-shelf point tracker, we extract long-range motion trajectories and optimize feature clustering with a momentum-encoder-based optimal transport mechanism. Temporal coherence is enforced by propagating cluster assignments along tracked points, ensuring feature consistency across views despite viewpoint changes. By leveraging motion as an implicit supervisory signal and initializing from strong image-pretrained models, MoSiC learns robust representations that generalize across frames. Our approach improves state-of-the-art performance by 1% to 6% across six image and video datasets and four evaluation benchmarks.
FLOSS: Free Lunch in Open-vocabulary Semantic Segmentation
Authors: Yasser Benigmim, Mohammad Fahes, Tuan-Hung Vu, Andrei Bursuc, Raoul de Charette
[Paper] [Code]
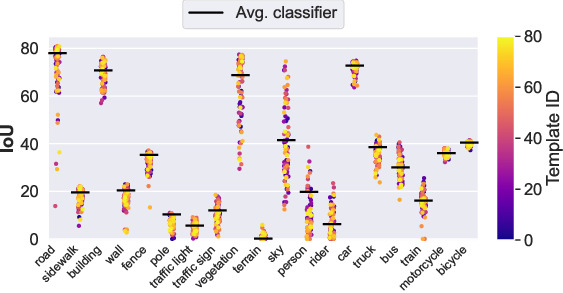
In Open-Vocabulary Semantic Segmentation (OVSS), class-wise text embeddings are usually averaged over multiple templates (e.g., “a photo of
Analyzing Fine-tuning Representation Shift for Multimodal LLMs Steering Alignment
Authors: Pegah Khayatan, Mustafa Shukor, Jayneel Parekh, Matthieu Cord
[Paper] [Code]
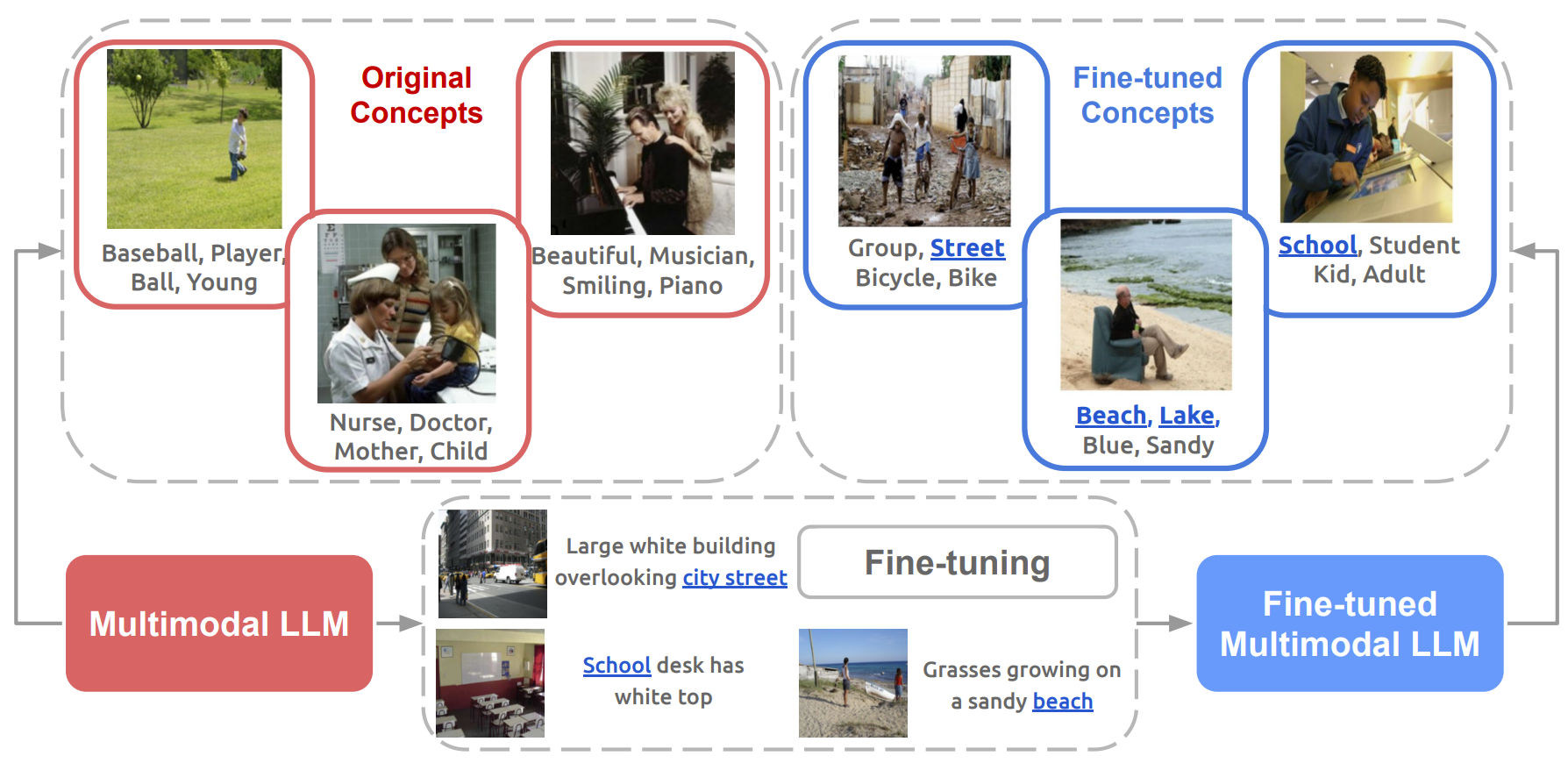
Multimodal LLMs have achieved remarkable proficiency in understanding multimodal inputs, yet little attention has been given to explaining how their internal representations evolve during training. Most explainability research focuses only on final model states, ignoring dynamic representational shifts. In this work, we systematically analyze the evolution of hidden state representations during fine-tuning, revealing how models adapt to new multimodal tasks. Using a concept-based approach, we map hidden states to interpretable visual and textual concepts, enabling us to trace concept changes across modalities as training progresses. We introduce shift vectors to capture these changes, allowing recovery of fine-tuned concepts from the original model. Furthermore, we demonstrate practical applications in model steering, such as adjusting answer types, caption styles, or biasing responses without additional training. This work provides novel insights into multimodal representation adaptation and offers tools for interpreting and controlling fine-tuned multimodal LLMs.