The team will be at CVPR to present these works, exchange ideas, and share our exciting ongoing research. We look forward to seeing you in Denver!
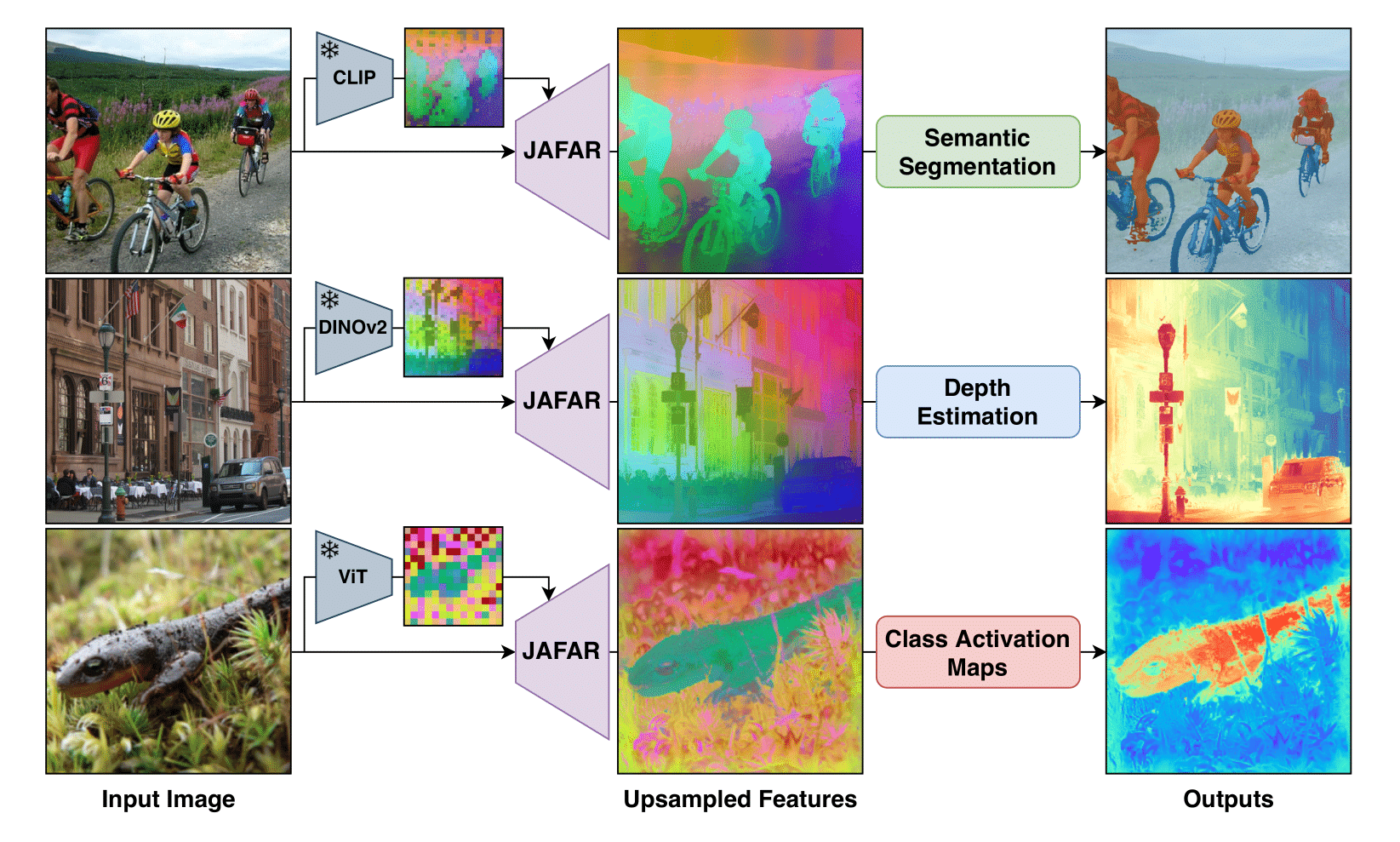
NAF: Zero-Shot Feature Upsampling via Neighborhood Attention Filtering
Highlight
Authors: Loick Chambon, Paul Couairon, Eloi Zablocki, Alexandre Boulch, Nicolas Thome, Matthieu Cord
[Paper] [Code]

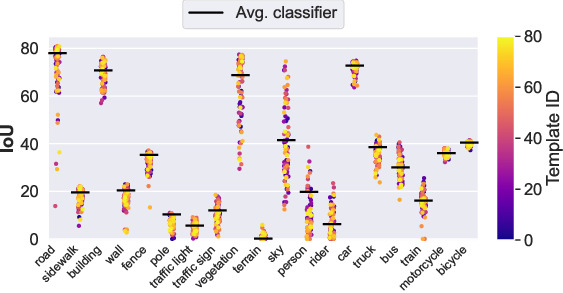
Vision Foundation Models produce spatially downsampled representations that create challenges for pixel-level tasks. We introduce Neighborhood Attention Filtering (NAF), a method that learns adaptive spatial-and-content weights through Cross-Scale Neighborhood Attention and Rotary Position Embeddings, guided solely by high-resolution input images. NAF operates as a zero-shot upsampler compatible with any VFM without retraining, achieving state-of-the-art performance across multiple downstream tasks while maintaining efficiency at 18 FPS for 2K feature maps. The method also demonstrates strong results in image restoration applications.
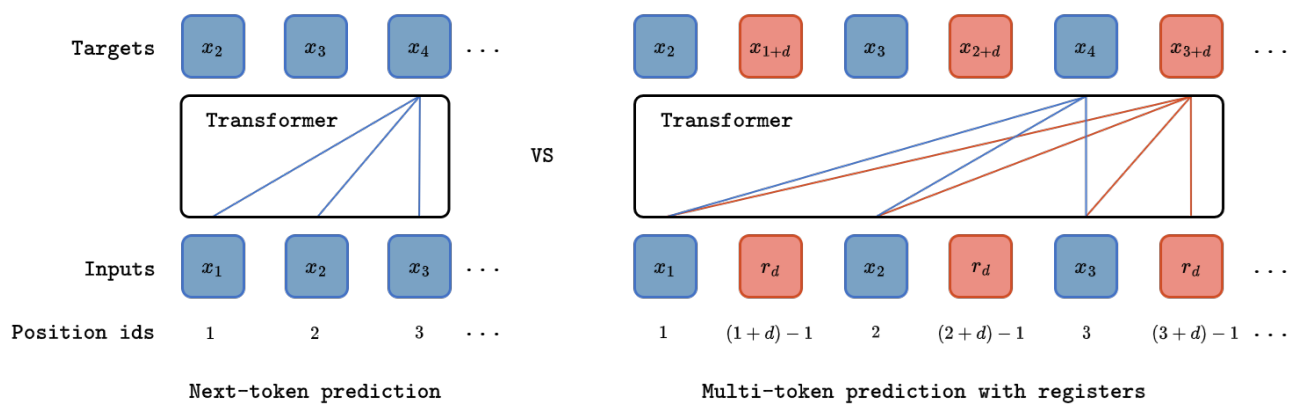
Driving on Registers
Authors: Ellington Kirby, Alexandre Boulch, Yihong Xu, Yuan Yin, Gilles Puy, Eloi Zablocki, Andrei Bursuc, Spyros Gidaris, Renaud Marlet, Florent Bartoccioni, Anh-Quan Cao, Nermin Samet, Tuan-Hung Vu, Matthieu Cord
[Paper] [Code] [Project page]

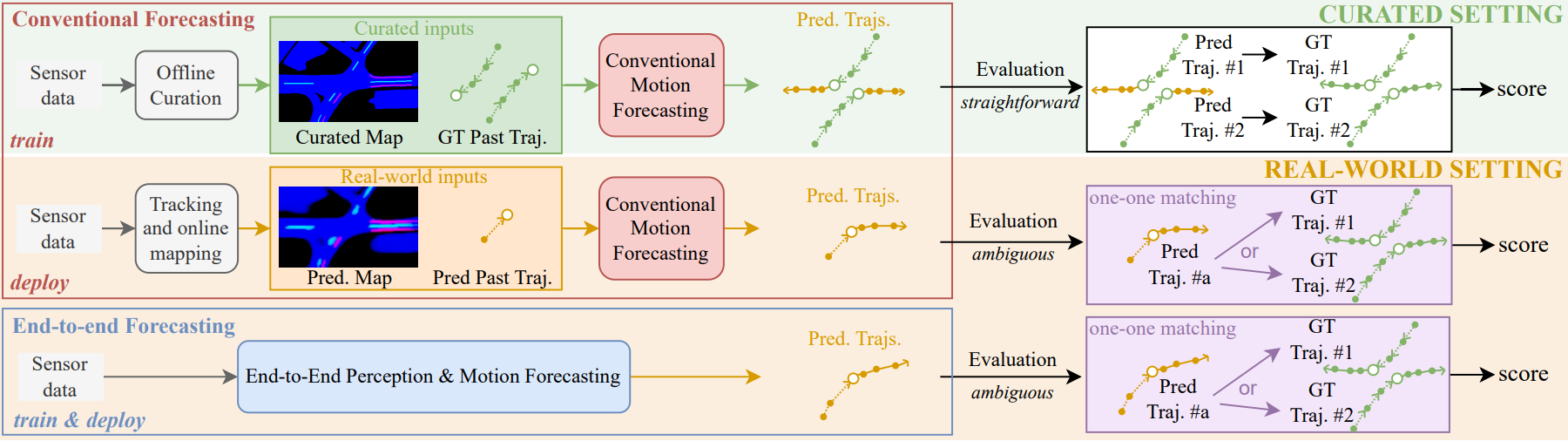
We present DrivoR, a simple and efficient transformer-based architecture for end-to-end autonomous driving. Our approach builds on pretrained Vision Transformers (ViTs) and introduces camera-aware register tokens that compress multi-camera features into a compact scene representation, significantly reducing downstream computation without sacrificing accuracy. These tokens drive two lightweight transformer decoders that generate and then score candidate trajectories. The scoring decoder learns to mimic an oracle and predicts interpretable sub-scores representing aspects such as safety, comfort, and efficiency, enabling behavior-conditioned driving at inference. Despite its minimal design, DrivoR outperforms or matches strong contemporary baselines across NAVSIM-v1, NAVSIM-v2, and the photorealistic closed-loop HUGSIM benchmark. Our results show that a pure-transformer architecture, combined with targeted token compression, is sufficient for accurate, efficient, and adaptive end-to-end driving.
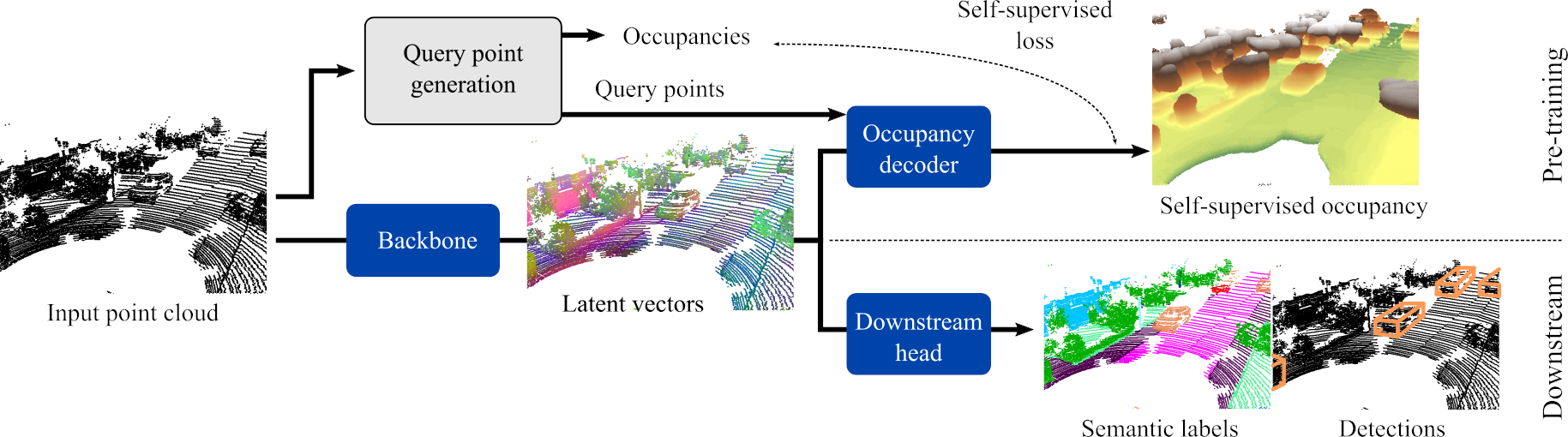
OccAny: Generalized Unconstrained Urban 3D Occupancy
Authors: Anh-Quan Cao, Tuan-Hung Vu
[Paper] [Code] [Project page]

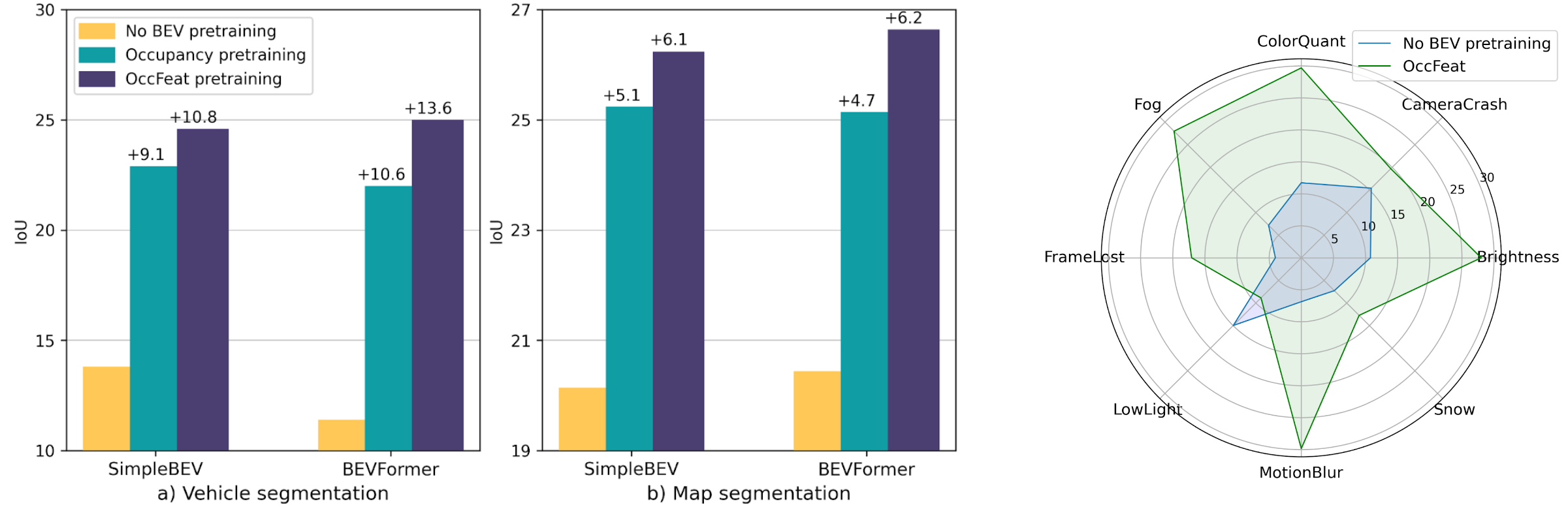
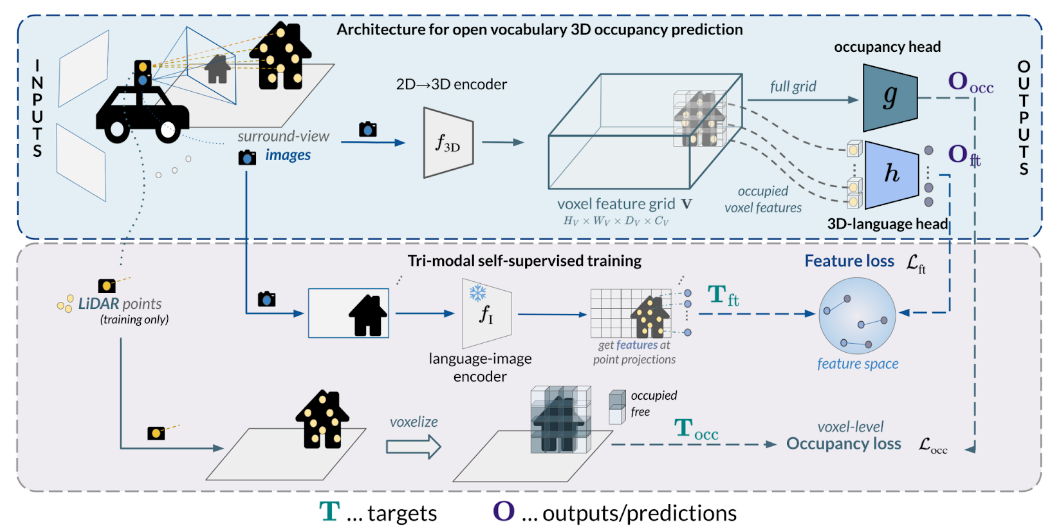
Relying on in-domain annotations and precise sensor-rig priors, existing 3D occupancy prediction methods are limited in both scalability and out-of-domain generalization. While recent visual geometry foundation models exhibit strong generalization capabilities, they were mainly designed for general purposes and lack one or more key ingredients required for urban occupancy prediction, namely metric prediction, geometry completion in cluttered scenes and adaptation to urban scenarios. We address this gap and present OccAny, the first unconstrained urban 3D occupancy model capable of operating on out-of-domain uncalibrated scenes to predict and complete metric occupancy coupled with segmentation features. OccAny is versatile and can predict occupancy from sequential, monocular, or surround-view images. Extensive experiments demonstrate that OccAny outperforms all visual geometry baselines on the 3D occupancy prediction task, while remaining competitive with in-domain self-supervised methods across three input settings on two established urban occupancy prediction datasets.
Franca: Nested Matryoshka Clustering for Scalable Visual Representation Learning
Authors: Shashanka Venkataramanan, Valentinos Pariza, Mohammadreza Salehi, Lukas Knobel, Spyros Gidaris, Elias Ramzi, Andrei Bursuc, Yuki M. Asano
[Paper] [Code]

We present Franca, the first fully open-source (data, code, weights) vision foundation model that matches and in many cases surpasses the performance of state-of-the-art proprietary models, e.g., DINOv2, CLIP, SigLIPv2. Our approach is grounded in a transparent training pipeline using publicly available data: ImageNet-21K and a subset of ReLAION-2B. We introduce a parameter-efficient, multi-head clustering projector based on nested Matryoshka representations that progressively refines features into increasingly fine-grained clusters without increasing model size. Additionally, we propose a novel positional disentanglement strategy that explicitly removes positional biases from dense representations, leading to consistent gains on several downstream benchmarks. Our contributions establish a new standard for transparent, high-performance vision models and open a path toward more reproducible and generalizable foundation models.
MAD: Motion Appearance Decoupling for efficient Driving World Models
Authors: Ahmad Rahimi, Valentin Gerard, Eloi Zablocki, Matthieu Cord, Alexandre Alahi
[Paper] [Code] [Project page]

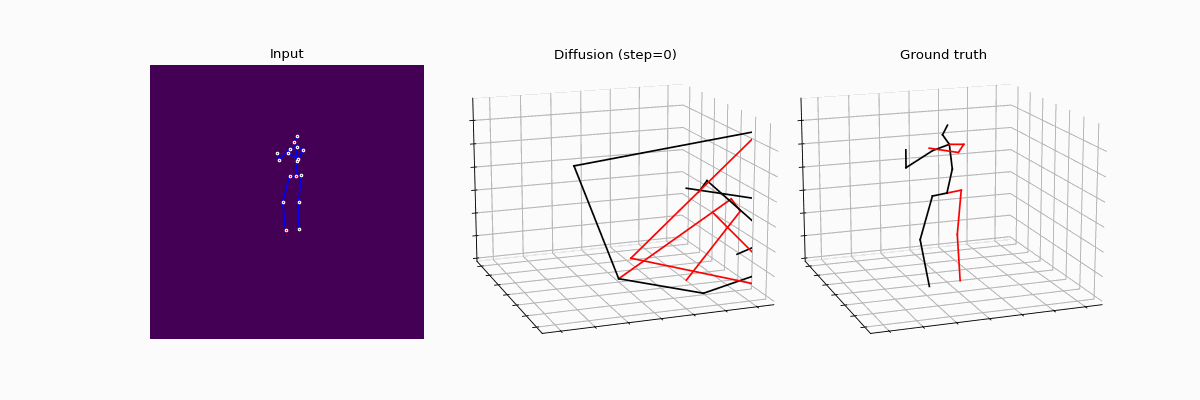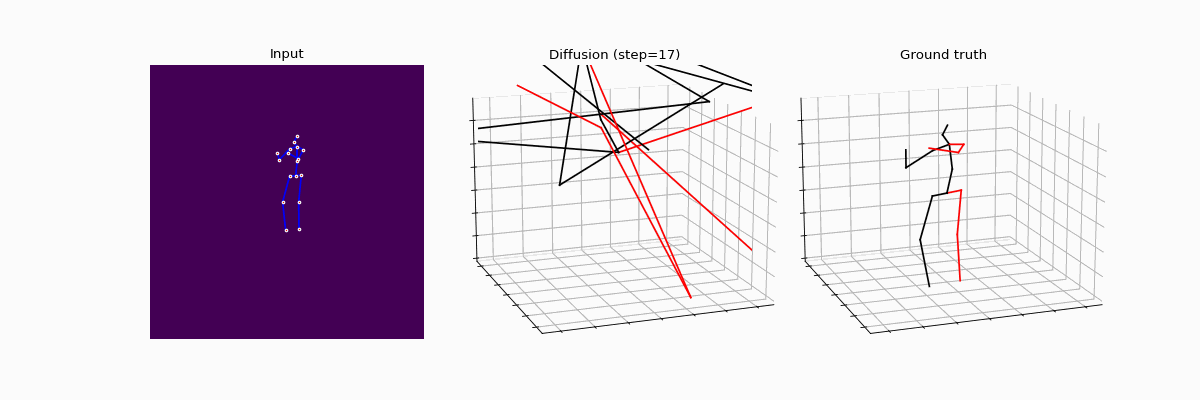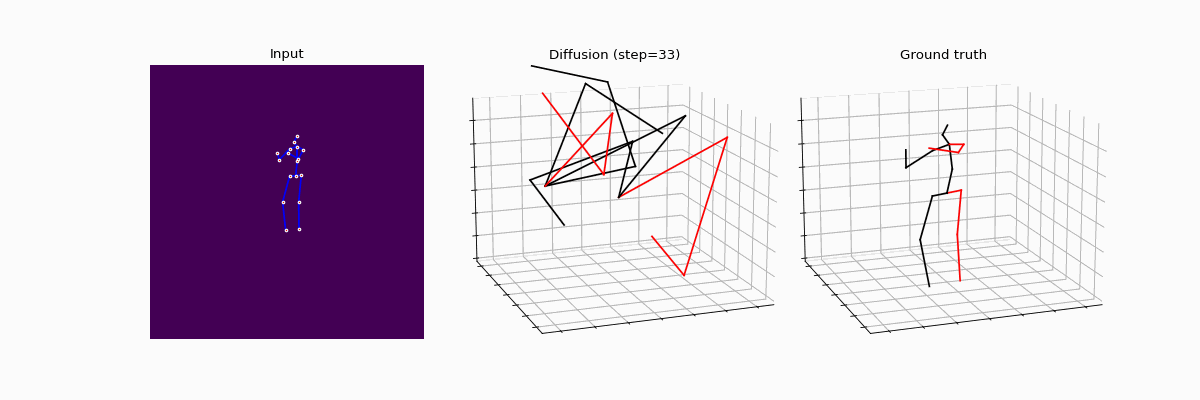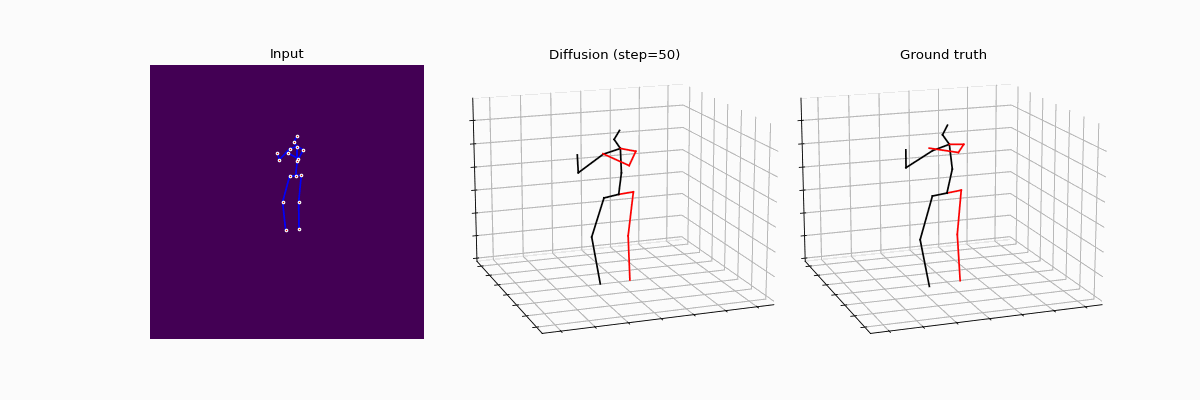
Recent video diffusion models generate photorealistic, temporally coherent videos, yet they fall short as reliable world models for autonomous driving, where structured motion and physically consistent interactions are essential. We propose an efficient adaptation framework that converts generalist video diffusion models into controllable driving world models with minimal supervision. The key idea is to decouple motion learning from appearance synthesis. First, the model is adapted to predict structured motion in a simplified form: videos of skeletonized agents and scene elements, focusing learning on physical and social plausibility. Then, the same backbone is reused to synthesize realistic RGB videos conditioned on these motion sequences. This two-stage process mirrors a reasoning-rendering paradigm: first infer dynamics, then render appearance. Our experiments show this decoupled approach is exceptionally efficient: adapting SVD, we match prior SOTA models with less than 6% of their compute. Scaling to LTX, our MAD-LTX model outperforms all open-source competitors, and supports a comprehensive suite of text, ego, and object controls.
StableMTL: Repurposing Latent Diffusion Models for Multi-Task Learning from Partially Annotated Synthetic Datasets
Authors: Anh-Quan Cao, Ivan Lopes, Raoul de Charette
[Paper] [Code]
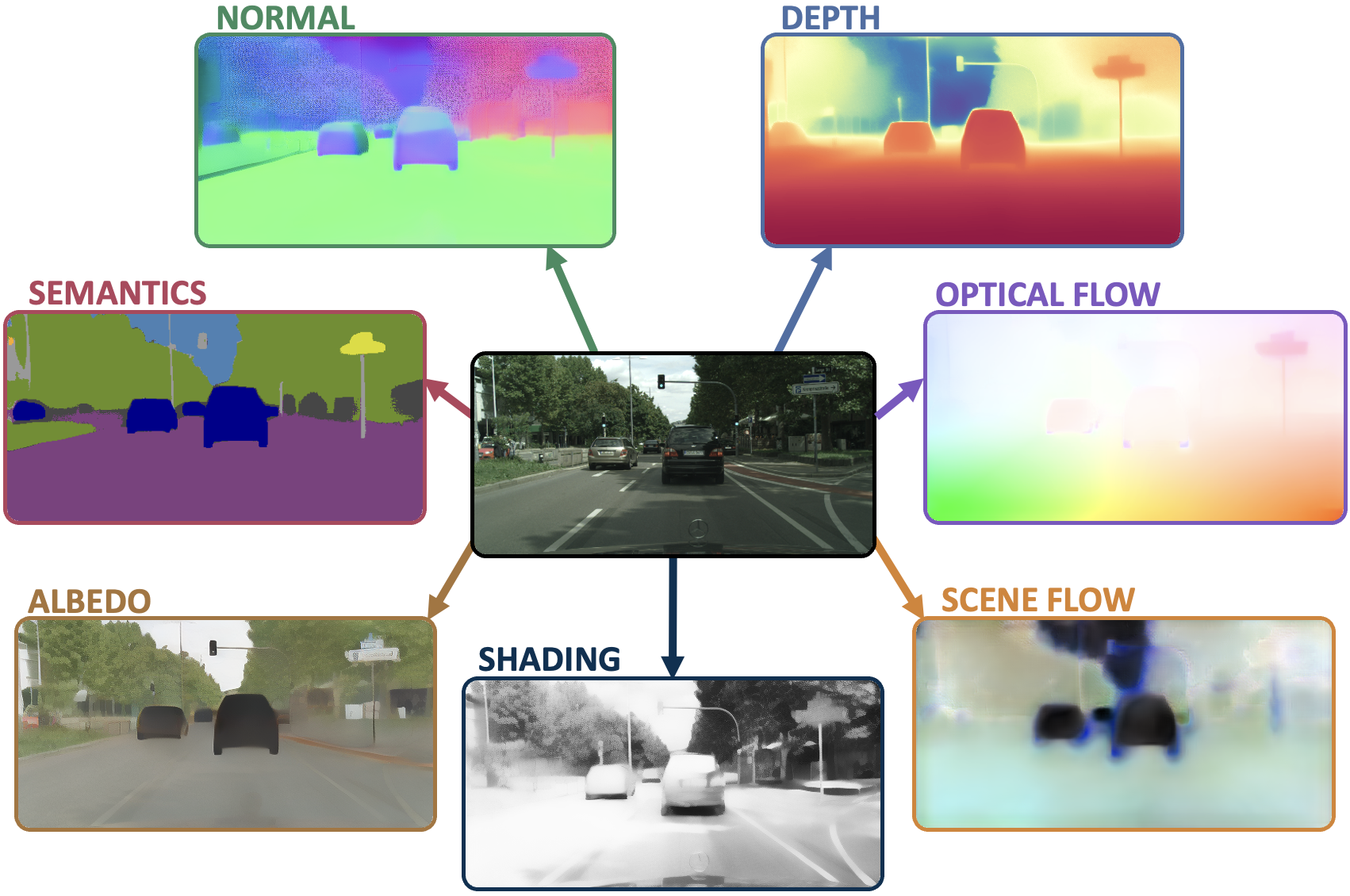
Multi-task learning for dense prediction is limited by the need for extensive annotation for every task, though recent works have explored training with partial task labels. Leveraging the generalization power of diffusion models, we extend the partial learning setup to a zero-shot setting, training a multi-task model on multiple synthetic datasets, each labeled for only a subset of tasks. Our method, StableMTL, repurposes image generators for latent regression, adapting a denoising framework with task encoding, per-task conditioning and a tailored training scheme. Instead of per-task losses requiring careful balancing, a unified latent loss is adopted, enabling seamless scaling to more tasks. To encourage inter-task synergy, we introduce a multi-stream model with a task-attention mechanism that converts N-to-N task interactions into efficient 1-to-N attention, promoting effective cross-task sharing. StableMTL outperforms baselines on 7 tasks across 8 benchmarks.
LiDAS: Lighting-driven Dynamic Active Sensing for Nighttime Perception
Authors: Simon de Moreau, Andrei Bursuc, Hafid El-Idrissi, Fabien Moutarde
[Paper] [Project page]
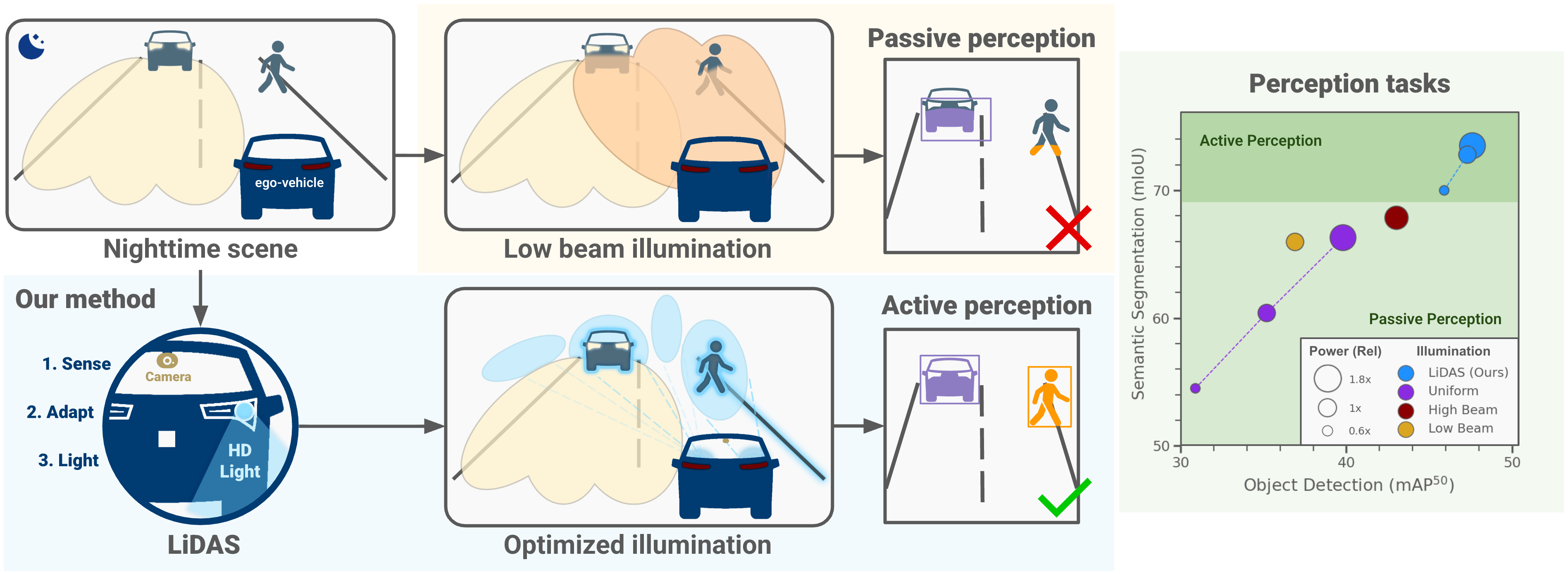
Camera-based perception in autonomous driving suffers a steep performance drop at night, when low light degrades image quality and existing solutions either rely on costly hardware upgrades or post-hoc image enhancement. We introduce LiDAS, a closed-loop active illumination system that dynamically predicts the optimal lighting pattern for visual perception, concentrating light on objects of interest while reducing it in empty regions. LiDAS integrates seamlessly with standard perception models and high-definition headlights, enabling zero-shot nighttime generalization of daytime-trained networks. On a realistic nighttime simulator and on real driving sequences, LiDAS yields +18.7% mAP50 and +5.0% mIoU over standard low-beam at equal power, while also enabling up to 40% energy savings at matched performance. Our approach turns commodity headlights into active perception devices, paving the way for robust nighttime autonomous perception.
LAM3C: 3D sans 3D Scans: Scalable Pre-training from Video-Generated Point Clouds
Authors: Ryosuke Yamada, Kohsuke Ide, Yoshihiro Fukuhara, Hirokatsu Kataoka, Gilles Puy, Andrei Bursuc, Yuki M. Asano
[Paper] [Code] [Project page]
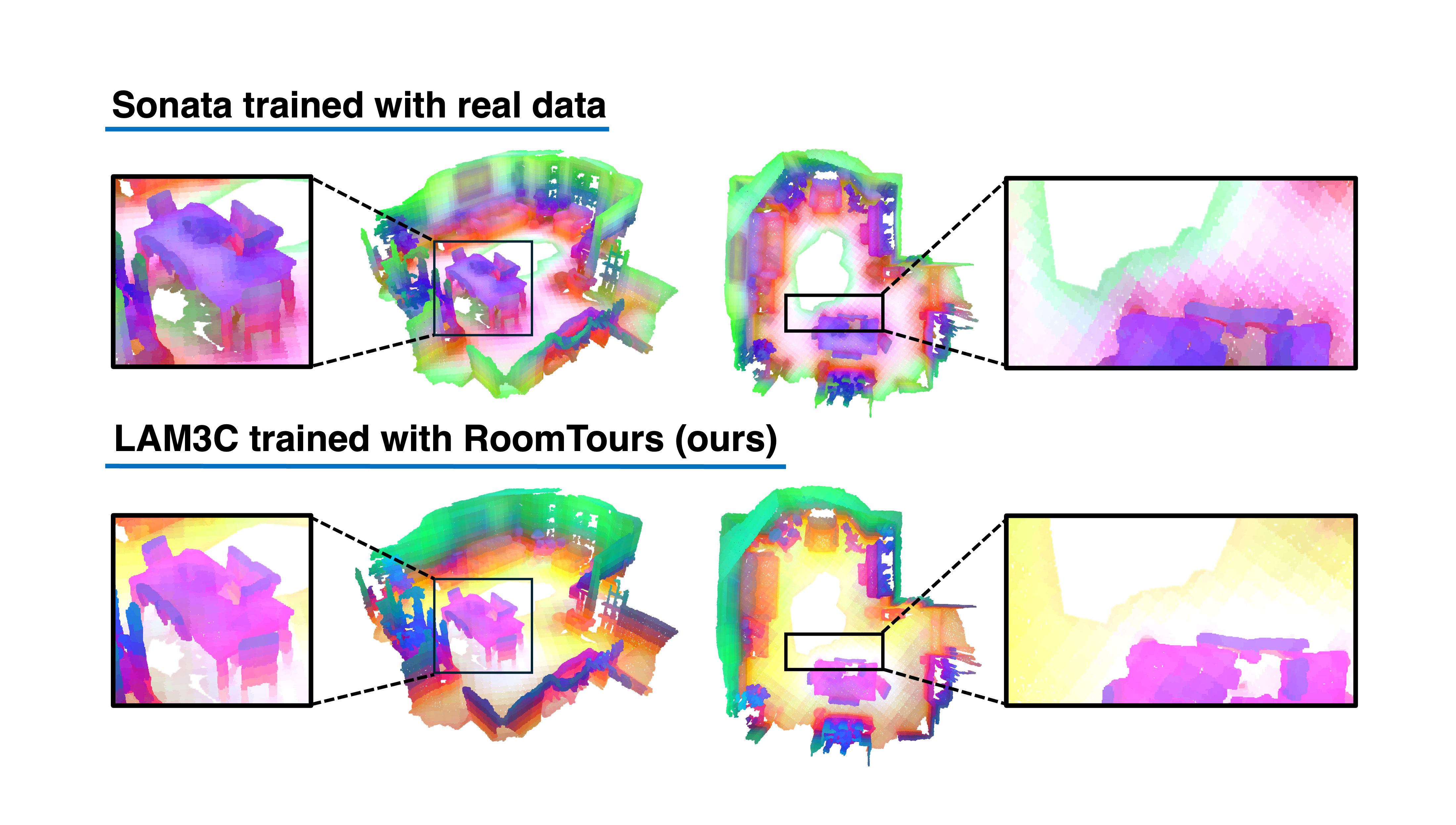
We investigate the use of unlabeled videos for learning 3D representations without ever resorting to a 3D sensor. To this end, we introduce LAM3C, a self-supervised learning framework that operates directly on point clouds reconstructed from video. To support this, we curate RoomTours, a new dataset of 49,219 scenes generated from web-collected room-walkthrough videos using a feed-forward reconstruction model. Pre-training on this video-derived data introduces challenges: noisy geometry and incomplete coverage destabilize standard SSL objectives. We address these by proposing a noise-regularized loss that stabilizes representation learning by enforcing local geometric smoothness and ensuring feature stability under noisy point clouds. Despite never seeing real 3D scans, LAM3C surpasses prior self-supervised methods on indoor semantic and instance segmentation, demonstrating that unlabeled videos are a powerful and scalable resource for 3D self-supervised learning.
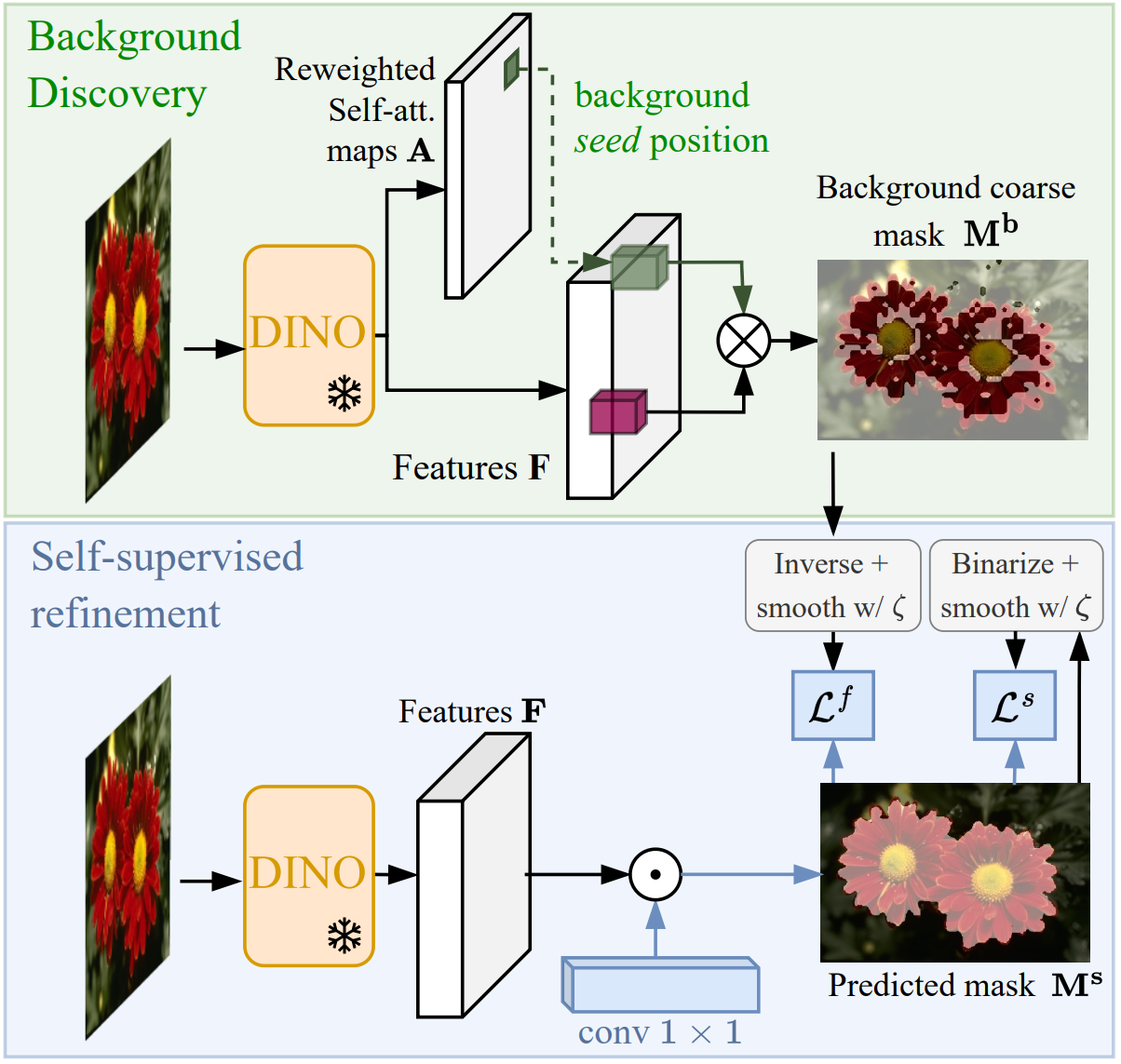
ICM: Attention, May I Have Your Decision? Localizing Generative Choices in Diffusion Models
Authors: Katarzyna Zaleska, Lukasz Popek, Monika Wysoczanska, Kamil Deja
[Paper] [Code]
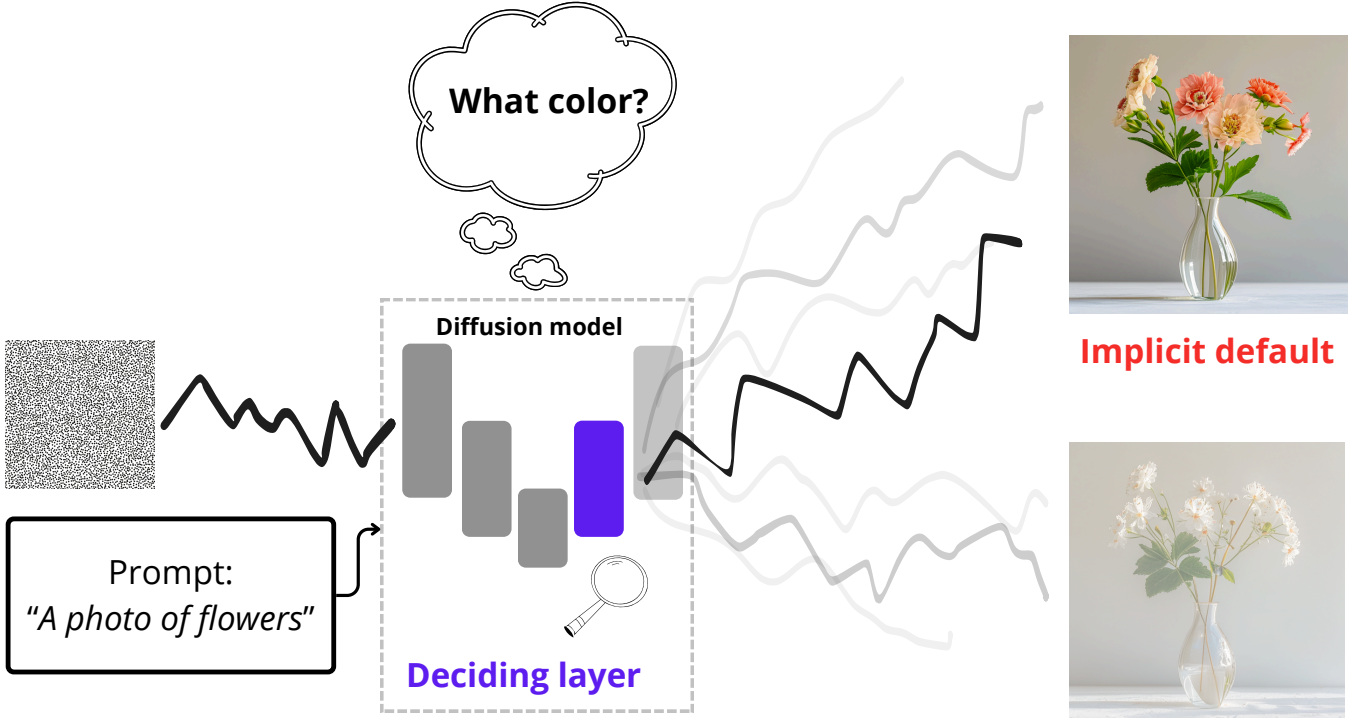
Text-to-image diffusion models routinely face ambiguous prompts that under-specify visual details, forcing them to make implicit decisions about unspecified attributes. We posit that this decision-making is computationally localized within the model’s architecture rather than being uniformly distributed. We introduce a probing technique that identifies the layers exhibiting the highest attribute separability, and find that self-attention layers are the locus where these implicit choices are resolved. Building on this insight, we propose ICM (Implicit Choice-Modification), a targeted steering method that modifies only the identified self-attention layers to control the model’s implicit decisions. Experiments demonstrate that ICM achieves superior debiasing performance with fewer artifacts than existing approaches, providing both a new tool for controllable generation and a better understanding of where generative choices live in diffusion models.
PoM: A Linear-Time Replacement for Attention with the Polynomial Mixer
CVPR 2026 Findings
Authors: David Picard, Nicolas Dufour, Lucas Degeorge, Arijit Ghosh, Davide Allegro, Tom Ravaud, Yohann Perron, Corentin Sautier, Zeynep Sonat Baltaci, Fei Meng, Syrine Kalleli, Marta Lopez-Rauhut, Thibaut Loiseau, Segolene Albouy, Raphael Baena, Elliot Vincent, Loic Landrieu
[Paper] [Code]
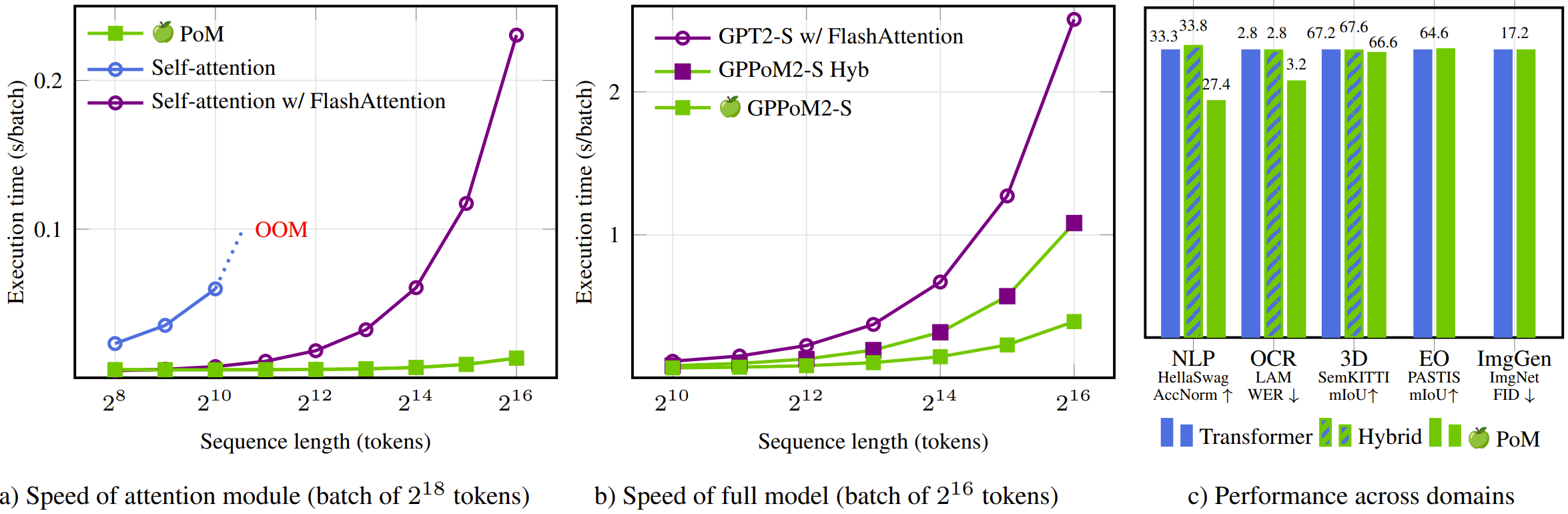
This paper introduces the Polynomial Mixer (PoM), a novel token mixing mechanism with linear complexity that serves as a drop-in replacement for self-attention. PoM aggregates input tokens into a compact representation through a learned polynomial function, from which each token retrieves contextual information. We prove that PoM satisfies the contextual mapping property, ensuring that transformers equipped with PoM remain universal sequence-to-sequence approximators. We replace standard self-attention with PoM across five diverse domains: text generation, handwritten text recognition, image generation, 3D modeling, and Earth observation. PoM matches the performance of attention-based models while drastically reducing computational cost when working with long sequences.
]]>